本文所用代码gayhub的地址:https://github.com/chenyuntc/simple-faster-rcnn-pytorch (非本人所写,博文只是解释代码)
好长时间没有发博客了,感觉也没啥人读我的博客,不过我不能放弃啊,总会有人发现它的价值的,哈哈!最近一直在生啃目标检测的几篇论文,距离成为我想象中的大神还有很远的一段距离啊,刚啃完Faster-RCNN的论文的时候,觉得可能是语言的关系,自己看得一直是似懂非懂的,感觉没有掌握到里面的精髓,于是我决定撸代码来看,据说Ross Girshick大神的代码很健壮,看了下是基于caffe/caffe2写的,自己不太熟悉caffe的框架和环境,于是就心血来潮在网上找基于pytorch的Faster-RCNN的代码,最后还真被我找到了陈云写的simple-faster-rcnn-pytorch-master,能从头撸出Faster-RCNN的实现真的是十分的不容易,我光读就读了一个星期,真是惭愧,差距还是很大的!simple-faster-RCNN顾名思义就是简化版的faster-rcnn,作者说代码除去注释只有2000行左右,但是能达到和rgb大神差不多的精度,真的是很了不起了!为此我还特意买了作者一本书,就当是付费看代码吧~
具体的实现精度和相关的环境建议大家仔细阅读作者的README文件,上面讲的很清楚,本篇博客主要负责解释代码,以备日后重新读不用这么费力气。
本篇博客是整个Faster-rcnn系列的第四篇文章,主要解释/simple-faster-rcnn-pytorch-master/train.py 以及/simple-faster-rcnn-pytorch-master/trainer.py
前三章地址在:
1 Faster-RCNN的数据读取及预处理部分:(对应于代码的/simple-faster-rcnn-pytorch-master/data文件夹)
2 Faster-RCNN的模型准备部分:(对应于代码目录/simple-faster-rcnn-pytorch-master/model/utils/文件夹)
3 Faster-RCNN的模型正式介绍:(对应于代码目录/simple-faster-rcnn-pytorch-master/model/文件夹)
下面正式开始介绍Faster-rcnn的训练部分的代码
一:trainer.py部分代码:
首先来看trainer.py,因为trainer.py里面实现了很多函数供train.py调用,trainer.py文件里函数结构如下图:
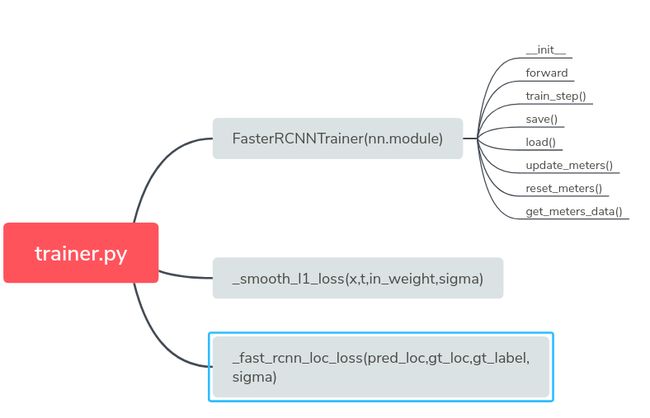
然后我们开始一个函数一个函数的进行剖析,可能读着读着你就会发现原来晦涩难懂的问题突然就变得很直觉了!
1 __init__函数 代码如下:


1 def __init__(self, faster_rcnn): 2 super(FasterRCNNTrainer, self).__init__() 3 4 self.faster_rcnn = faster_rcnn 5 self.rpn_sigma = opt.rpn_sigma 6 self.roi_sigma = opt.roi_sigma 7 8 # target creator create gt_bbox gt_label etc as training targets. 9 self.anchor_target_creator = AnchorTargetCreator() 10 self.proposal_target_creator = ProposalTargetCreator() 11 12 self.loc_normalize_mean = faster_rcnn.loc_normalize_mean 13 self.loc_normalize_std = faster_rcnn.loc_normalize_std 14 15 self.optimizer = self.faster_rcnn.get_optimizer() 16 # visdom wrapper 17 self.vis = Visualizer(env=opt.env) 18 19 # indicators for training status 20 self.rpn_cm = ConfusionMeter(2) 21 self.roi_cm = ConfusionMeter(21) 22 self.meters = {k: AverageValueMeter() for k in LossTuple._fields}
__init__ Faster_RCNNTrainer的初始化函数,其父类是nn.module,主要是一些变量的初始化部分,定义了self.faster_rcnn = faster_rcnn,而这个rpn_sigma和roi_sigma是在_faster_rcnn_loc_loss调用用来计算位置损失函数用到的超参数,
之后定义了十分重要的两个函数,AnchorTargetCreator()和ProposalTargetCreator(),它们一个用于从20000个候选anchor中产生256个anchor进行二分类和位置回归,也就是为rpn网络产生的预测位置和预测类别提供真正的ground_truth标准
用于rpn网络的自我训练,自我提高,提升产生ROIs的精度!具体的筛选过程和准则看前面几篇文章,而ProposalTargetCreator()的作用是从2000个筛选出的ROIS中再次选出128个ROIs用于训练,它的作用和前面的anchortargetCreator类似,不过它们服务的网络是不同的,前面anchortargetCreator服务的是RPN网络,而我们的proposaltargetCreator服务的是ROIHearder的网络,ROIheader的作用就是真正产生ROI__loc和ROI_cls的网络,它完成了目标检测最重要的预测目标位置和类别!之后定义了位置信息的均值方差,因为送入到网络训练的位置信息全部是归一化处理的,需要用到相关的均值和方差数据,接下来是优化器数据,用的是faster_rcnn文件里的get_optimizer()数据,里面决定了是使用Adam还是SGD等等,以及衰减率的设置之类,最后是可视化部分的一些设置,rpn_cm是混淆矩阵,就是验证预测值与真实值精确度的矩阵ConfusionMeter(2)括号里的参数指的是类别数,所以rpn_cm =2,而roi_cm =21因为roi的类别有21种(20个object类+1个background)
2 def forward(self,imgs,bboxes,labels,scale)函数 代码如下:
1 def forward(self, imgs, bboxes, labels, scale): 2 """Forward Faster R-CNN and calculate losses. 3 4 Here are notations used. 5 6 * :math:`N` is the batch size. 7 * :math:`R` is the number of bounding boxes per image. 8 9 Currently, only :math:`N=1` is supported. 10 11 Args: 12 imgs (~torch.autograd.Variable): A variable with a batch of images. 13 bboxes (~torch.autograd.Variable): A batch of bounding boxes. 14 Its shape is :math:`(N, R, 4)`. 15 labels (~torch.autograd..Variable): A batch of labels. 16 Its shape is :math:`(N, R)`. The background is excluded from 17 the definition, which means that the range of the value 18 is :math:`[0, L - 1]`. :math:`L` is the number of foreground 19 classes. 20 scale (float): Amount of scaling applied to 21 the raw image during preprocessing. 22 23 Returns: 24 namedtuple of 5 losses 25 """ 26 n = bboxes.shape[0] 27 if n != 1: 28 raise ValueError('Currently only batch size 1 is supported.') 29 30 _, _, H, W = imgs.shape 31 img_size = (H, W) 32 33 features = self.faster_rcnn.extractor(imgs) 34 35 rpn_locs, rpn_scores, rois, roi_indices, anchor = \ 36 self.faster_rcnn.rpn(features, img_size, scale) 37 38 # Since batch size is one, convert variables to singular form 39 bbox = bboxes[0] 40 label = labels[0] 41 rpn_score = rpn_scores[0] 42 rpn_loc = rpn_locs[0] 43 roi = rois 44 45 # Sample RoIs and forward 46 # it's fine to break the computation graph of rois, 47 # consider them as constant input 48 sample_roi, gt_roi_loc, gt_roi_label = self.proposal_target_creator( 49 roi, 50 at.tonumpy(bbox), 51 at.tonumpy(label), 52 self.loc_normalize_mean, 53 self.loc_normalize_std) 54 # NOTE it's all zero because now it only support for batch=1 now 55 sample_roi_index = t.zeros(len(sample_roi)) 56 roi_cls_loc, roi_score = self.faster_rcnn.head( 57 features, 58 sample_roi, 59 sample_roi_index) 60 61 # ------------------ RPN losses -------------------# 62 gt_rpn_loc, gt_rpn_label = self.anchor_target_creator( 63 at.tonumpy(bbox), 64 anchor, 65 img_size) 66 gt_rpn_label = at.totensor(gt_rpn_label).long() 67 gt_rpn_loc = at.totensor(gt_rpn_loc) 68 rpn_loc_loss = _fast_rcnn_loc_loss( 69 rpn_loc, 70 gt_rpn_loc, 71 gt_rpn_label.data, #定位损失为什么加label大概是因为负例不参与定位损失吧 72 self.rpn_sigma) 73 74 # NOTE: default value of ignore_index is -100 ... 75 rpn_cls_loss = F.cross_entropy(rpn_score, gt_rpn_label.cuda(), ignore_index=-1) 76 _gt_rpn_label = gt_rpn_label[gt_rpn_label > -1] 77 _rpn_score = at.tonumpy(rpn_score)[at.tonumpy(gt_rpn_label) > -1] 78 self.rpn_cm.add(at.totensor(_rpn_score, False), _gt_rpn_label.data.long()) 79 80 # ------------------ ROI losses (fast rcnn loss) -------------------# 81 n_sample = roi_cls_loc.shape[0] 82 roi_cls_loc = roi_cls_loc.view(n_sample, -1, 4) 83 roi_loc = roi_cls_loc[t.arange(0, n_sample).long().cuda(), \ 84 at.totensor(gt_roi_label).long()] 85 gt_roi_label = at.totensor(gt_roi_label).long() 86 gt_roi_loc = at.totensor(gt_roi_loc) 87 88 roi_loc_loss = _fast_rcnn_loc_loss( 89 roi_loc.contiguous(), 90 gt_roi_loc, 91 gt_roi_label.data, 92 self.roi_sigma) 93 94 roi_cls_loss = nn.CrossEntropyLoss()(roi_score, gt_roi_label.cuda()) 95 96 self.roi_cm.add(at.totensor(roi_score, False), gt_roi_label.data.long()) 97 98 losses = [rpn_loc_loss, rpn_cls_loss, roi_loc_loss, roi_cls_loss] 99 losses = losses + [sum(losses)] 100 101 return LossTuple(*losses)
这段函数该是整个文件的精髓,画一张流程图出来描述整个网络的运作过程:
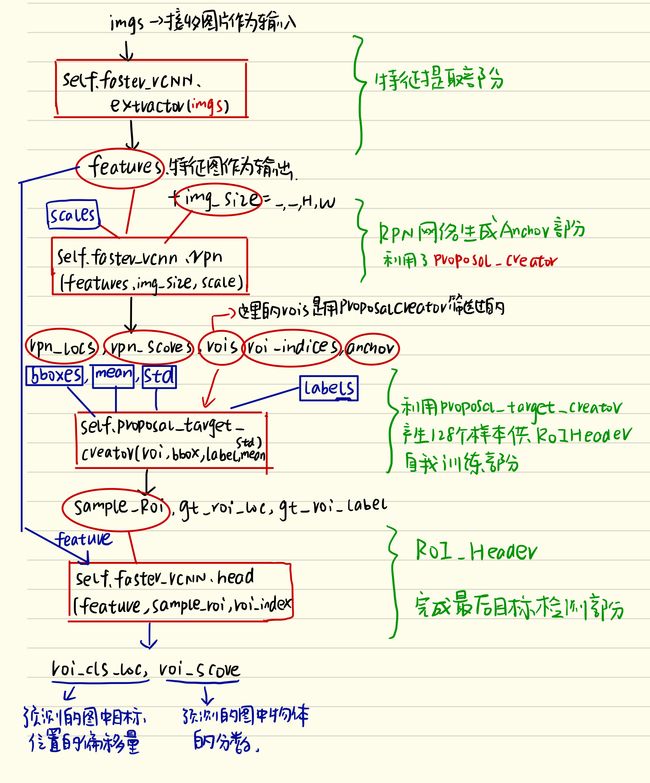
整幅图片描述在求损失之前训练过程经历了什么!不准确的说是一个伪正向传播的过程,为啥说是伪正向传播呢,因为过程中调用了proposal_target_creator(),而这个函数的作用其实是为了训练ROI_Header网络而提供所谓的128张sample_roi以及它的ground_truth的位置和label用的!所以它的根本目的是为了训练网络,在测试的时候是用不到的!流程图中红色圆框代表的是网络运行过程中产生的参数,而蓝色框代表的是网络定义的时候就有的参数!仔细看整个流程图,网络的运作结构就一目了然了!下面解释下代码:
n= bboxes.shape[0]首先获取batch个数,如果不等于就报错,因为本程序只支持batch_size=1,接着读取图片的高和宽,这里解释下,不论图片还是bbox,它们的数据格式都是形如n,c,hh,ww这种,所以H,W就可以获取到图片的尺寸,紧接着用self.faster_rcnn.extractor(imgs)提取图片的特征,然后放到rpn网络里面self.faster_rcnn.rpn(feature,img_size,scale)提取出rpn_locs,rpn_scores,rois,roi_indices,anchor来,下一步就是经过proposal_target_creator网络产生采样过后的sample_roi,以及其对应的gt_cls_loc和gt_score,最后经过head网络,完成整个的预测过程!流程图中的结构是一模一样的!
但是这个文件之所以叫trainer就是因为不仅仅有正向的运作过程,肯定还有反向的传播,包括了损失计算等等,没错,接下来我们看下面的损失计算部分的流程图:
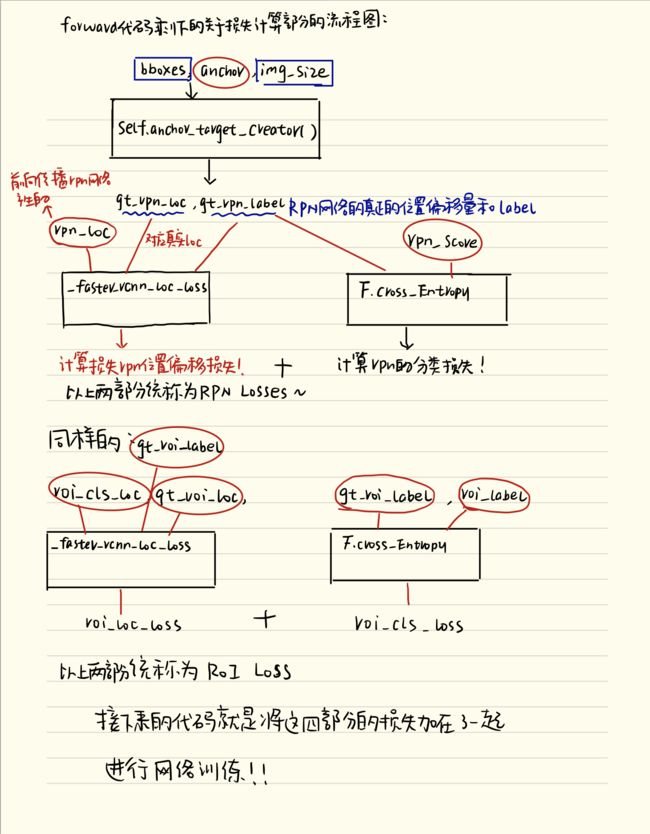
如上图所示,其实剩下的代码就是计算了两部分的损失,一个是RPN_losses,一个是ROI_Losses,为啥要这样做呢?大家考虑一下,这个Faster-rcnn的网络,哪些地方应用到了网络呢?一个是提取proposal的过程,在faster-rcnn里创造性的提出了anchor,用网络来产生proposals,所以rpn_losses就是为了计算这部分的损失,从而使用梯度下降的办法来提升提取prososal的网络的性能,另一个使用到网络的地方就是ROI_header,没错就是在利用特征图和ROIs来预测目标检测的类别以及位置的偏移量的时候再一次使用到了网络,那这部分预测网络的性能如何保证呢?ROI_losses就是计算这部分的损失函数,从而用梯度下降的办法来继续提升网络的性能啊兄弟!这样一来,这两部分的网络的损失都记算出来了!forward函数也就介绍完了!这个地方需要特别注意的一点就是rpn_cm和roi_cm这两个对象应该是Confusion matrix也就是混淆矩阵啦,作用就是用于后续的数据可视化,不是本文重点介绍的内容啦!
3 def train_step(self,imgs,bboxes,labels,scale)函数,代码如下:
1 def train_step(self, imgs, bboxes, labels, scale): 2 self.optimizer.zero_grad() 3 losses = self.forward(imgs, bboxes, labels, scale) 4 losses.total_loss.backward() 5 self.optimizer.step()#进行一次参数优化过程 6 self.update_meters(losses) 7 return losses
整个函数实际上就是进行了一次参数的优化过程,首先self.optimizer.zero_grad()将梯度数据全部清零,然后利用刚刚介绍的self.forward(imgs,bboxes,labels,scales)函数将所有的损失计算出来,接着进行依次losses.total_loss.backward()反向传播计算梯度,self.optimizer.step()进行一次参数更新过程,self.update_meters(losses)就是将所有损失的数据更新到可视化界面上,最后将losses返回!
4 def save() def load() def update_meters(),def reset_meters() def get_meter_data()函数
这几个函数不想仔细展开解释了,顾名思义,save和load就是根据传入的参数来选择保存model模型或者说config设置或者是other_info其他参数vis_info可视化参数等等
而update_meters,reset_meters以及get_meter_data()就是负责将数据向可视化界面更新传输获取以及重置的函数,基本上也和主要代码没什么太大的关系!
5 def _smooth_l1_loss(x,t,in_weight,sigma)函数,代码如下:
1 def _smooth_l1_loss(x, t, in_weight, sigma): 2 sigma2 = sigma ** 2 3 diff = in_weight * (x - t) 4 abs_diff = diff.abs() 5 flag = (abs_diff.data < (1. / sigma2)).float() 6 y = (flag * (sigma2 / 2.) * (diff ** 2) + 7 (1 - flag) * (abs_diff - 0.5 / sigma2)) 8 return y.sum()
这个函数其实就是写了一个smooth_l1损失函数的计算公式,这个公式里面的x,t就是代表预测和实际的两个变量,in_weight代表的是权重,因为在计算损失函数的过程中被标定为背景的那一类其实是不计算损失函数的,所以说可以巧妙地将对应的权重设置为0,这样就完成了忽略背景类的目的,这也就是为什么计算位置的损失函数还要传入ground_truth的label作为参数的原因,sigma是一个因子,在前面的__init__函数里有定义好!
6 def _fast_rcnn_loc_loss(pred_loc,gt_loc,gt_label,sigma)函数,代码如下:
1 def _fast_rcnn_loc_loss(pred_loc, gt_loc, gt_label, sigma): 2 in_weight = t.zeros(gt_loc.shape).cuda() 3 # Localization loss is calculated only for positive rois. 4 # NOTE: unlike origin implementation, 5 # we don't need inside_weight and outside_weight, they can calculate by gt_label 6 in_weight[(gt_label > 0).view(-1, 1).expand_as(in_weight).cuda()] = 1 7 loc_loss = _smooth_l1_loss(pred_loc, gt_loc, in_weight.detach(), sigma) 8 # Normalize by total number of negtive and positive rois. 9 loc_loss /= ((gt_label >= 0).sum().float()) # ignore gt_label==-1 for rpn_loss 10 return loc_loss
这个函数完成的任务就是我刚刚在前面说的,用in_weight来作为权重,只将那些不是背景的anchor/ROIs的位置加入到损失函数的计算中来,方法就是只给不是背景的anchor/ROIs的in_weight设置为1,这样就可以完成loc_loss的求和计算,最后进行返回就完成了计算位置损失的任务!
二:train.py部分代码:
接下来就是train.py部分的代码了,同样的先将程序框图送上:

看这程序框图仿佛发现这个文件好像根本没啥东西啊,不着急我们慢慢展开来介绍:
1 def eval(dataloader,faster_rcnn,test_num=10000)函数,代码如下:
1 def eval(dataloader, faster_rcnn, test_num=10000): 2 pred_bboxes, pred_labels, pred_scores = list(), list(), list() 3 gt_bboxes, gt_labels, gt_difficults = list(), list(), list() 4 for ii, (imgs, sizes, gt_bboxes_, gt_labels_, gt_difficults_) in tqdm(enumerate(dataloader)): 5 sizes = [sizes[0][0].item(), sizes[1][0].item()] 6 pred_bboxes_, pred_labels_, pred_scores_ = faster_rcnn.predict(imgs, [sizes]) 7 gt_bboxes += list(gt_bboxes_.numpy()) 8 gt_labels += list(gt_labels_.numpy()) 9 gt_difficults += list(gt_difficults_.numpy()) 10 pred_bboxes += pred_bboxes_ 11 pred_labels += pred_labels_ 12 pred_scores += pred_scores_ 13 if ii == test_num: break 14 15 result = eval_detection_voc( 16 pred_bboxes, pred_labels, pred_scores, 17 gt_bboxes, gt_labels, gt_difficults, 18 use_07_metric=True) 19 return result
eval()顾名思义,就是一个评估预测结果好坏的函数,展开来看果不其然,首先pred_bboxes,pred_labels,pred_scores ,gt_bboxes,gt_labels,gt_difficults 一开始就定义了这么多的list列表!它们分别是预测框的位置,预测框的类别和分数以及相应的真实值的类别分数等等!
接下来就是一个for循环,从 enumerate(dataloader)里面依次读取数据,读取的内容是: imgs图片,sizes尺寸,gt_boxes真实框的位置 gt_labels真实框的类别以及gt_difficults这些
然后利用faster_rcnn.predict(imgs,[sizes]) 得出预测的pred_boxes_,pred_labels_,pred_scores_预测框位置,预测框标记以及预测框的分数等等!这里的predict是真正的前向传播过程!完成真正的预测目的!
之后将pred_bbox,pred_label,pred_score ,gt_bbox,gt_label,gt_difficult预测和真实的值全部依次添加到开始定义好的列表里面去,如果迭代次数等于测试test_num,那么就跳出循环!调用 eval_detection_voc函数,接收上述的六个列表参数,完成预测水平的评估!得到预测的结果!这个eval_detection_voc后面会解释!
2 def train(**kwargs)函数,代码如下:
1 def train(**kwargs): 2 opt._parse(kwargs) 3 4 dataset = Dataset(opt) 5 print('load data') 6 dataloader = data_.DataLoader(dataset, \ 7 batch_size=1, \ 8 shuffle=True, \ 9 # pin_memory=True, 10 num_workers=opt.num_workers) 11 testset = TestDataset(opt) 12 test_dataloader = data_.DataLoader(testset, 13 batch_size=1, 14 num_workers=opt.test_num_workers, 15 shuffle=False, \ 16 pin_memory=True 17 ) 18 faster_rcnn = FasterRCNNVGG16() 19 print('model construct completed') 20 trainer = FasterRCNNTrainer(faster_rcnn).cuda() 21 if opt.load_path: 22 trainer.load(opt.load_path) 23 print('load pretrained model from %s' % opt.load_path) 24 trainer.vis.text(dataset.db.label_names, win='labels') 25 best_map = 0 26 lr_ = opt.lr 27 for epoch in range(opt.epoch): 28 trainer.reset_meters() 29 for ii, (img, bbox_, label_, scale) in tqdm(enumerate(dataloader)): 30 scale = at.scalar(scale) 31 img, bbox, label = img.cuda().float(), bbox_.cuda(), label_.cuda() 32 trainer.train_step(img, bbox, label, scale)#进行一次参数优化过程 33 34 if (ii + 1) % opt.plot_every == 0: 35 if os.path.exists(opt.debug_file): 36 ipdb.set_trace() 37 38 # plot loss 39 trainer.vis.plot_many(trainer.get_meter_data()) 40 41 # plot groud truth bboxes 42 ori_img_ = inverse_normalize(at.tonumpy(img[0])) 43 gt_img = visdom_bbox(ori_img_, 44 at.tonumpy(bbox_[0]), 45 at.tonumpy(label_[0])) 46 trainer.vis.img('gt_img', gt_img) 47 48 # plot predicti bboxes 49 _bboxes, _labels, _scores = trainer.faster_rcnn.predict([ori_img_], visualize=True) 50 pred_img = visdom_bbox(ori_img_, 51 at.tonumpy(_bboxes[0]), 52 at.tonumpy(_labels[0]).reshape(-1), 53 at.tonumpy(_scores[0])) 54 trainer.vis.img('pred_img', pred_img) 55 56 # rpn confusion matrix(meter) 57 trainer.vis.text(str(trainer.rpn_cm.value().tolist()), win='rpn_cm') 58 # roi confusion matrix 59 trainer.vis.img('roi_cm', at.totensor(trainer.roi_cm.conf, False).float()) 60 eval_result = eval(test_dataloader, faster_rcnn, test_num=opt.test_num) 61 trainer.vis.plot('test_map', eval_result['map']) 62 lr_ = trainer.faster_rcnn.optimizer.param_groups[0]['lr'] 63 log_info = 'lr:{}, map:{},loss:{}'.format(str(lr_), 64 str(eval_result['map']), 65 str(trainer.get_meter_data())) 66 trainer.vis.log(log_info) 67 68 if eval_result['map'] > best_map: 69 best_map = eval_result['map'] 70 best_path = trainer.save(best_map=best_map) 71 if epoch == 9: 72 trainer.load(best_path) 73 trainer.faster_rcnn.scale_lr(opt.lr_decay) 74 lr_ = lr_ * opt.lr_decay 75 76 if epoch == 13: 77 break
这个函数是这篇文章的重点部分,也是整个网络的训练部分,首先来看下代码:
首先是 opt._parse(**kwargs) + dataset = Dataset(opt) 我认为这个地方就是将调用函数时候附加的参数用config.py文件里面的opt._parse()进行解释,然后获取其数据存储的路径,之后放到Dataset里面!Dataset完成的任务见第一篇博客数据预处理部分,这里简单解释一下,就是用VOCBboxDataset作为数据读取库,然后依次从样例数据库中读取图片出来,还调用了Transform(object)函数,完成图像的调整和随机反转工作!
然后是dataloader = data_.DataLoader(dataset,batch_size=1,shuffle=True,num_workers=opt.num_workers) 将数据装载到dataloader中,shuffle=True允许数据打乱排序,num_workers是设置数据分为几批处理,同样的将测试数据集也进行同样的处理,然后装载到test_dataloader中!接下来定义faster_rcnn=FasterRCNNVGG16()定义好模型!FasterRCNNVGG16()的参数模型见系列博客的第三篇模型介绍,之后是设置trainer = FasterRCNNTrainer(faster_rcnn).cuda()将FasterRCNNVGG16作为fasterrcnn的模型送入到FasterRCNNTrainer中并设置好GPU加速,接下来判断opt.load_path是否存在,如果存在,直接从opt.load_path读取预训练模型,然后将训练数据的label进行可视化操作,之后用一个for循环开始训练过程,而训练迭代的次数opt.epoch也在config.py文件中都预先定义好,属于超参数,接下来看for循环体:
1首先在可视化界面重设所有数据
2然后从训练数据中枚举dataloader,设置好缩放范围,将img,bbox,label,scale全部设置为可gpu加速
3调用trainer.py中的函数trainer.train_step(img,bbox,label,scale)进行一次参数迭代优化过程!
4 判断数据读取次数是否能够整除plot_every(是否达到了画图次数),如果达到判断debug_file是否存在,用ipdb工具设置断点,调用trainer中的trainer.vis.plot_many(trainer.get_meter_data())将训练数据读取并上传完成可视化!
5将每次迭代读取的图片用dataset文件里面的inverse_normalize()函数进行预处理,将处理后的图片调用Visdom_bbox(ori_img_,at_tonumpy(_bboxes[0]),at.tonumpy(_labels[0].reshape(-1)),at.tonumpy(_scores[0]))
6调用trainer.vis.img('pred_img',pred_img)将迭代读取原始数据中的原图,bboxes框架,labels标签在可视化工具下显示出来
7调用 _bboxes,_labels,_socres = trainer.faster_rcnn.predict([ori_img_],visualize=True)调用faster_rcnn的predict函数进行预测,预测的结果保留在以_下划线开头的对象里面
8利用同样的方法将原始图片以及边框类别的预测结果同样在可视化工具中显示出来!
9调用train.vis.text(str(trainer.rpn_cm.value().tolist),win='rpn_cm')将rpn_cm也就是RPN网络的混淆矩阵在可视化工具中显示出来
10调用trainer.vis.img('roi_cm', at.totensor(trainer.roi_cm.conf, False).float())将Roi_cm将roi的可视化矩阵以图片的形式显示出来
===============接下来是测试阶段的代码=============================================================
11 调用eval_result = eval(test_dataloader, faster_rcnn, test_num=opt.test_num)将测试数据调用eval()函数进行评价,存储在eval_result中
12 trainer.vis.plot('test_map', eval_result['map']) 将eval_result['map']在可视化工具中进行显示
13 lr_ = trainer.faster_rcnn.optimizer.param_groups[0]['lr'] 设置学习的learning rate
14log_info = 'lr:{}, map:{},loss:{}'.format(str(lr_),str(eval_result['map']),str(trainer.get_meter_data())) + trainer.vis.log(log_info) 将损失学习率以及map等信息及时显示更新
15 用if判断语句永远保存效果最好的map!
16 if判断语句如果学习的epoch达到了9就将学习率*0.1变成原来的十分之一
17 判断epoch==13结束训练验证过程
可以看出,其实train.py文件里大多数都是为可视化部分做了详细的设置,代码基本上都是围绕着可视化来进行的,最后,作为本篇博客的结束,贴一个作者运行时可视化的截图吧!
可以更好的方便大家理解为什么要这么设置,代码对应的可视化部分都有哪些:
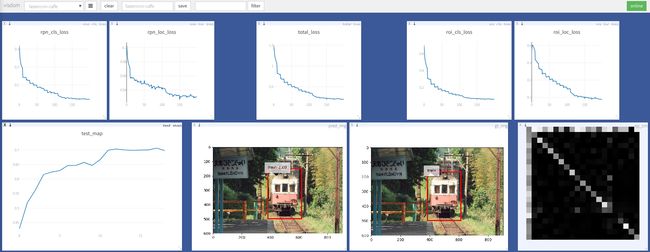
至此,Faster-RCNN的pytorch简化版本的整个训练过程的代码就解释完了,如果对你还有点启发的话就写个留言鼓励一下吧~如果觉得哪里有问题,欢迎留言指出哦!纯手打,难免有误,多多包含谢谢大家!