利用 Python 练习数据挖掘(鸢尾花练习)中遇到的问题,以及解决方法。
大佬好,我是只小菜鸟,目前正在学习数据挖掘。在练习鸢尾花这个经典练习中,遇到一些问题,顺便记录一下。
原链接利用python练习数据挖掘。
一 获取数据、
import urllib2
url = 'http://aima.cs.berkeley.edu/data/iris.csv'#数据地址
#获取数据
u=urllib2.urlopen(url)
localfile=open("iris.csv","w")
localfile.write(u.read())
localfile.close()#前4列包含着特征值,最后一列代表着样本类型。
data = genfromtxt('iris.csv',delimiter=',',usecols=(0,1,2,3))#添加数据,打开文档,以逗号为分割,添加1,2,3,4列数据
target = genfromtxt('iris.csv',delimiter=',',usecols=(4),dtype=str)#添加目标,打开数据文档,数据的第5列为数据目标,类型是str
print data.shape
>>>(150, 4)
print target.shape
>>>(150, )
#上面代码中,创建了一个包含特征值的矩阵(data.shape)以及一个包含样本类型的向量(target.shape)
print set(target)#获取样本类型和名字
>>>set(['setosa', 'versicolor', 'virginica'])
print data[target=='setosa',0]#打印目标为“setosa”的第一列的所有数据
>>>[ 5.1 4.9 ... 5.3 5. ]二 绘图、
matplotlib绘图实例:pyplot、pylab模块及作图参数
1、点状图
from pylab import plot show
plot(data[target="setosa',0],data[target="setosa",2],"yo")#使用目标“setosa”的第一维度和第三维度作为参数,“yo”是指黄色点状,如果是“y”是指黄色折线.
plot(data[target=='versicolor',0],data[target=='versicolor',2],'ro')#使用....作为参数,红色点状
plot(data[target=='virginica',0],data[target=='virginica',2],'go')#`这里写代码片`使用....作为参数,绿色点状
show()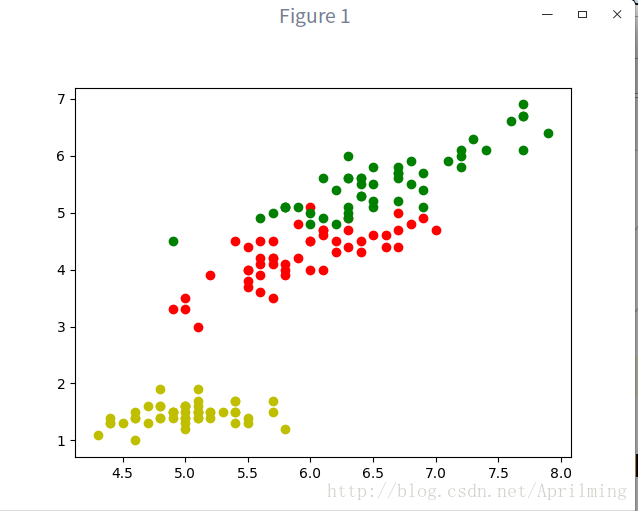
上图是参数为”yo”,”ro”,”go”
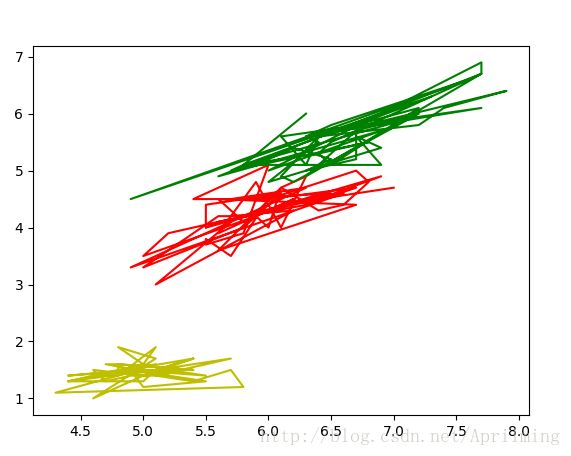
上图是参数为”y”,”r”,”g”
2、柱状图
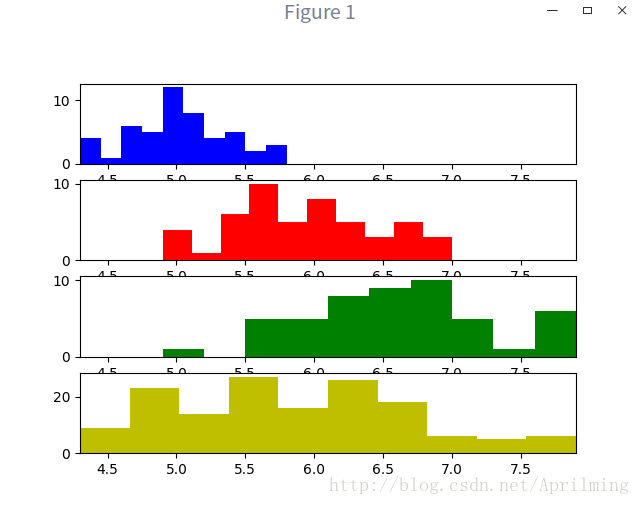
from pylab import figure, subplot, hist, xlim, show
xmin = min(data[:,0])#最小值
xmax = max(data[:,0])#最大值
figure()
subplot(411) #第一种花瓣的集合,b代表蓝色,alpha代表透明度,
hist(data[target=='setosa',0],color='b',alpha=1)
xlim(xmin,xmax)
subplot(412) # 第二红花瓣集合
hist(data[target=='versicolor',0],color='r',alpha=1)
xlim(xmin,xmax)
subplot(413) # 第三种花瓣集合
hist(data[target=='virginica',0],color='g',alpha=1)
xlim(xmin,xmax)
subplot(414) # 局部直方图
hist(data[:,0],color='y',alpha=1)
xlim(xmin,xmax)
show()至于为什么是subplot是(411-414)我就不清楚了,百度一下是这样的
百度知道的链接
“% subplot(行数目,列数目,当前第几个图)subplot(m, n, j);% 则表示一个figure里面有m行,n列图,现在绘制的是第j个图。”
三、分类
分类是一个数据挖掘方法,用于把一个数据集中的样本数据分配给各个目标类。实现这个方法的模块叫做分类器。使用分类器需要以下两步:训练和分类。训练是指采集已知其特定类归属的数据并基于这些数据创建分类器。 分类是指使用通过这些已知数据建立的分类器来处理未知的数据,以判断未知数据的分类情况。
#字符串数组转型成整型数据
t = zeros(len(target))
t[target == 'setosa'] = 1
t[target == 'versicolor'] = 2
t[target == 'virginica'] = 3接下来的这一步原文中是这样的:
from sklearn.naive_bayes import GaussianNB#导入模块
classifier = GaussianNB()#实例化
classifier.fit(data,t)#分类器错误
接下来在原文中是这样的:

但是实际运行的过程中是报错的:

错误信息:
from sklearn.naive_bayes import GaussianNB classifier = GaussianNB() classifier.fit(data,t)
解决方法:
data[0]这一快加[]:
print classifier.predict([data[0]])
print classifier.predict([data[0]])
>>>[ 1.]
print t[0]
>>>1简单的训练和测试已经完成,但是下面又出现一个问题:
问题:
原文中是这样的:
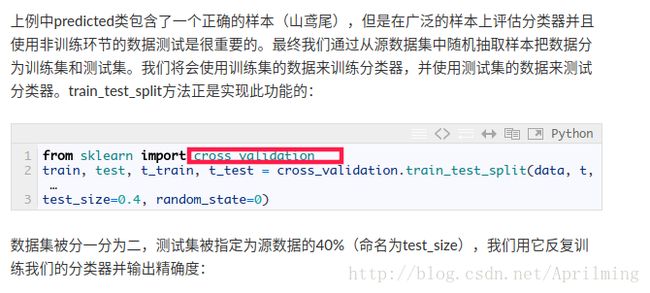
但是在实际中是:
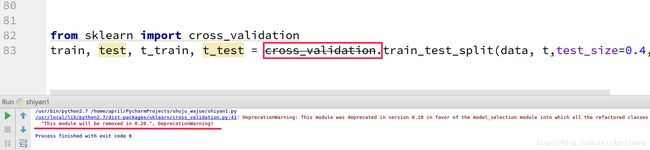
在2.0版本中,这个模块已经停止使用了。
解决方法:
将from sklearn import cross_validation换成from sklearn.model_selection import train_test_split
from sklearn.model_selection import train_test_split
train, test, t_train, t_test =train_test_split(data, t, test_size=0.4, random_state=0)今天先到这里,日后在续!