MIT最新研究:对抗样本才不是bug呢,人家,人家是特征~
大数据文摘出品
来源:gradientscience
编译:Andy
到目前为止,业内对于对抗样本的流行观点是,其源于模型的“怪癖”,一旦训练算法和数据收集方面取得足够的进展,那么它们终将消失。其他常见观点还包括,对抗样本要么是输入空间高维度的结果之一,要么是因为有限样本现象(finite-samplephenomena)。
而近日,来自MIT的几位研究员刚刚完成了一个最近的研究,它提供了一种对抗样本产生原因的新视角,并且,很有文学素养的研究员们尝试通过一个精妙的故事把这个研究讲个大家听。
一起来听听这个关于对抗样本的小故事。
一颗名为Erm的星球
故事始于Erm,这是颗遥远的星球,居住着一群被称为Nets(网)的古老外星人种。
Nets是一个神奇的物种;每个人在社会等级中的位置,取决于将奇怪的32×32像素图像(对Nets族来说毫无意义)分类为十个完全任意类别的能力。
这些图像来自于一个绝密数据集See-Far,除了看这些神奇的像素化图像以外,Nets的生活可以说完全是瞎的。
慢慢的,随着Nets越来越老,越来越聪明,他们开始在See-Far中发现越来越多的信号模式。他们发现的每个新模式都能帮他们更准确地对数据集进行分类。由于提高分类准确度的巨大社会价值,于是外星人们给最具预测性的图像模式都起了名,比如下图:

TOOGIT,一个高度指示“1”的图像,Nets们对TOOGIT异常敏感。
最强大的外星人非常善于发现这些模式,因此对这些模式在See-Far图像中的出现也很敏感。
不知何故(也许正在寻找See-Far分类提示),一些外星人获得了人类编写的机器学习论文,特别是其中一张图吸引住了外星人的眼球:

一个对抗样本?
这张图还是比较简单的,他们想:左边是“2”,然后中间有个GAB图案,大家都知道它表示“4”。于是不出意料的话,左边的图像上加上一个GAB产生一张新图像,这张图(对Nets来说)看起来和对应于“4”类别的图像完全相同。
但是Nets们无法理解为什么明明原始和最终图像完全不同,但根据论文的话它们应该是相同分类。带着疑惑,Nets们把论文看了个遍,想知道人类到底是忘了什么其他有用的模式......
我们从Erm中学到什么
正如故事中名字所暗示的,这个故事不仅仅是讲外星人和其神奇的社会结构:Nets的发展方式正是要让我们联想到机器学习模型是如何训练的。特别是其中,我们尽量地提高准确率,但却没有加入关于分类所在物理世界或其他人类相关概念的背景知识。故事的结果是,外星人意识到人类认为无意义的对抗性扰动,实际上是对See-Far分类至关重要的模式。因此,Nets的故事应该让我们思考:
对抗性样本真的是不自然且无意义的吗?
一个简单的实验
要搞明白这个问题,我们首先来进行一个简单的实验:
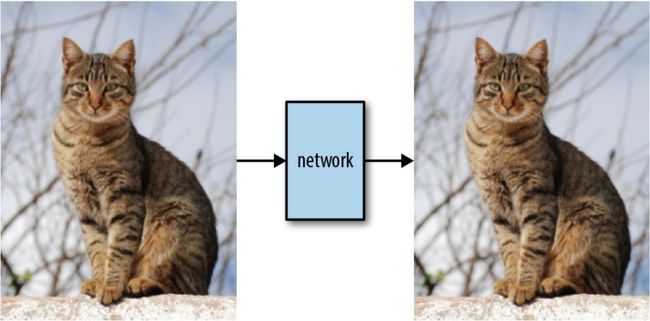
先从标准数据集(例如CIFAR10)的训练集中的一张图片开始:
我们通过合成有针对性的对抗样本(在一个标准预训练模型上),将每个(x,y)样本目标改到下一个类“y+1”(如果y是最后一个类,则为0):
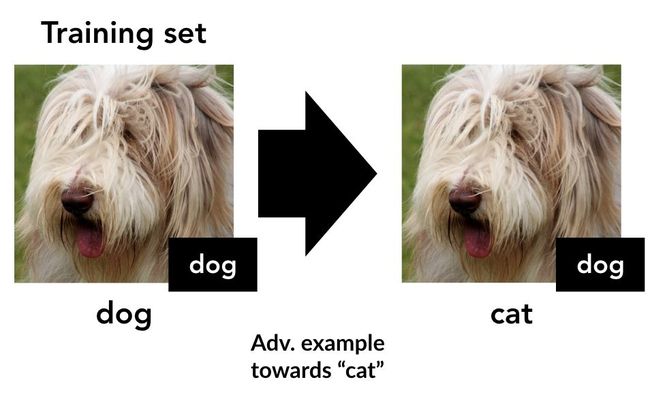
于是通过这样改变样本目标就构建出了一个新训练集:

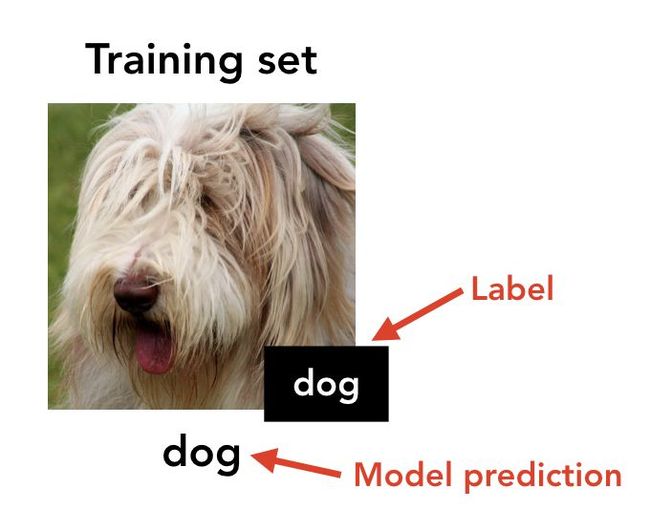
现在,由此产生的训练集只是对原始数据集轻微扰动得来,标签也改变了——但对于人来说它的标签完全都是错的。实际上,这种错误标签和“置换”假设一致(即每只狗被标记为猫,每只猫被标记为鸟这样)。
接着,我们在这个错误标记的数据集上训练一个新分类器(不一定与第一个具有相同结构)。那么该分类器在原始(未改变的)测试集(即标准CIFAR-10测试集)上表现会怎么样呢?
让人惊讶的是,结果发现新分类器在测试集上有着还算不错的精度(CIFAR上为44%)!尽管训练输入仅通过轻微扰动与其“真”标签相关联,而通过所有可见特征与一个不同的标签(现在是不正确的)相关。
这是为什么呢?
我们的对抗样本概念模型
在刚刚描述的实验中,我们将标准模型的对抗扰动作为目标类预测模式而获得一些泛化性。也就是说,仅训练集中的对抗性扰动就能对测试集进行适度准确的预测。有鉴于此,人们可能会想:也许这些模式与人类用来分类图像的模式(例如耳朵,胡须,鼻子)并无本质区别!这正是我们的假设:很多输入特征都能用来预测标签,但其中只有一些特征是人类可察觉的。
更准确说,我们认为数据的预测特征可分为稳健和不稳健特征。稳健特征对应于能预测真实标签的模式,即使在一些人类定义的扰动集(比如ℓ2ball)下的对抗性扰动。相反,非稳健特征对应于预测时可以被预先设定的扰动集对抗“翻转”过来以指示错误类别的特征。
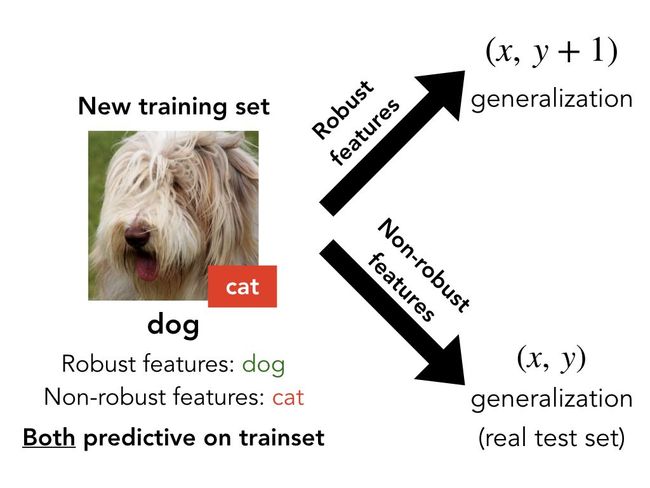
因为我们始终只考虑不影响人类分类的扰动集,于是希望人类完全依赖稳健特征来判断。然而,当目标是最大化(标准)测试集精度时,非稳健特征却可以像稳健特征一样有用——事实上,这两种类型的特征是完全可互换的。如下图所示:
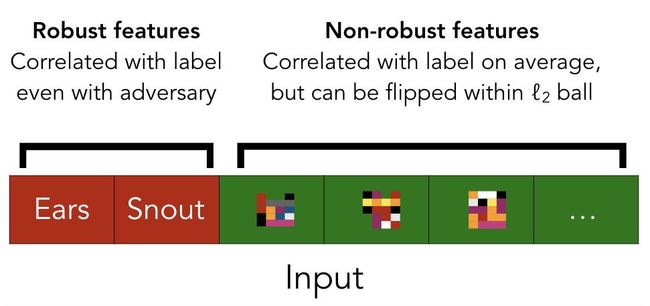
从这个角度来看,上述实验其实很简单。也就是,在原始训练集中,输入稳健特征和非稳健特征都可以用来预测标签。而当进行了细微对抗扰动时,不会显着地影响稳健特征(根据定义),但仍可能翻转非稳健特征。
例如,每只狗的图像都保留了狗的稳健特征(因此在我们看来还是狗),但具有猫的非强健特征。在重新标记训练集之后,使得稳健特征实际指向了错误方向(即具有稳健“狗”特征图片被标记为猫),因此就只有非稳健特征在实际泛化中提供了正确指导。
总之,稳健和非稳健特征都可以预测训练集,但只有非健壮特征才会产生对原始测试集的泛化:
因此,在该数据集上训练模型能推广到标准测试集的事实表明(a)存在非稳健特征并能实现较好的泛化(b)深度神经网络确实依赖于这些非稳健特征,即使有同样可用于预测的稳健特征。
稳健的模型能否学习稳健的特征?
实验表明,对抗性扰动不是毫无意义的人造物,而是直接与对泛化至关重要的扰动特征相关。与此同时,我们之前关于对抗样本的博客文章显示,通过使用稳健优化(robustoptimization),可以获得更不易受对抗样本影响的稳健模型。
因此,自然要问:能否验证稳健模型实际上就是依赖于稳健特征?为了验证这一点,我们提出了一种方法,尽量限制输入的是模型敏感的特征(对于深度神经网络,对应于倒数第二层的激活特征)。使用该方法,我们创建了一个新的训练集,该训练集仅包含已训练过的稳健模型使用的特征:

之后,在获得数据集上训练一个模型,不进行对抗训练。结果发现获得的模型有着很高的准确性和稳健性!这与标准训练集形成鲜明对比,后者导致模型准确但很脆弱。

标准和稳健的准确度,在CIFAR-10测试集(DD)上测试。训练:
左:CIFAR-10正常训练中:CIFAR-10进行对抗训练正确:构建数据集正常训练
结果表明,稳健性(或非稳健性)实际上可以作为数据集本身的属性出现。特别是,当我们从原始训练集中删除非稳健特征时,就可以通过标准(非对抗)训练获得稳健模型。这进一步证明,对抗样本是由于非稳健特征而产生的,并不一定与标准训练框架有关。
可迁移性
这个新视角变化带来的直接后果就是,对抗样本的可迁移性(一直以来的神秘现象:一种模型的扰动通常对其他模型也是对抗的)也就不再需要单独解释了。具体来说,既然把对抗脆弱性看作是从数据集产生特征的直接产物(而不是单个模型训练中的缺陷),于是也就希望类似的表达模型能够找到并使用这些特征,来提高分类准确性。
为了进一步探索,我们研究了不同架构学习类似非稳健特征的倾向如何与它们之间对抗样本的可转移性的相关:
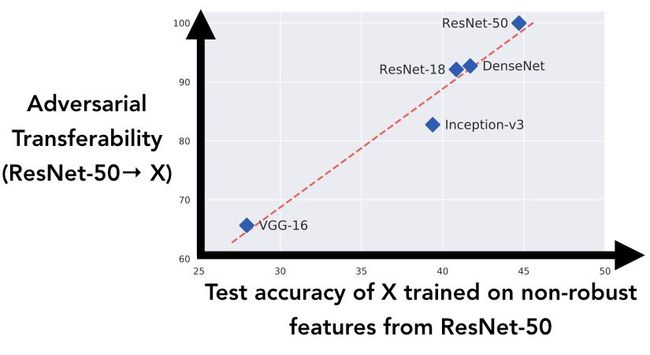
在上图中,我们生成了在第一个实验中描述的数据集(用目标类标记对抗样本的训练集),用ResNet-50构建对抗样本。于是可以将结果数据集视为将所有ResNet-50的非稳健特征“翻转”到目标类。然后,在此数据集上训练上图显示的五种网络模型,并在真实测试集上记录各自的泛化性:也就是模型仅用ResNet-50非稳健特征的泛化性的好坏。
当分析结果时,我们看到,正如对抗模型的新视角所表明的那样,模型能够获得ResNet-50引入的非稳健特征的能力与ResNet-50到各个标准模型之间的对抗迁移性非常相关。
启示
我们的讨论还有实验,确定对抗样本是纯粹以人为中心的现象。因为从分类性能角度来看,模型没有理由更喜欢稳健,而不喜欢非稳健特征。
毕竟,稳健性的概念是针对人类的。因此,如果我们希望模型主要依赖于稳健特征,那就需要通过将先验结合到架构或训练过程中来明确表明这一点。从这个角度来看,对抗性训练(以及更广义的稳健优化)可以说是将所需的不变性结合到学习模型中的方式。例如,稳健优化可以被看作是试图通过不断地“翻转”非鲁棒特征,来破坏它们的预测性,从而引导训练模型不去依赖它们。
同时,在设计可解释性方法时,也需要考虑标准模型对非稳健性(对人类不可理解)特征的依赖性。特别是,对标准训练模型的预测任何“解释”,都应该突出显示这些非稳健特征(对于人类不完全有意义)或隐藏他们(不完全忠于模型决策过程)。因此,如果我们想要既是人类可理解的同时又忠于模型的可解释性方法,那么仅仅靠训练后处理是不够的,还需要在训练时进行干预。
更多精彩尽在论文中
在论文中,我们还描述了一个用于讨论稳健性和非稳健性特征的精确框架,进一步证实了我们的假设。此外还有一个理论模型,能在存在非鲁棒特征时研究稳健性训练。
原文链接:
http://gradientscience.org/adv/
论文链接:
http://gradientscience.org/adv.pdf
相关github数据集:
https://github.com/MadryLab/constructed-datasets