NumPy高级应用与python高级数组操作
目录
ndarray对象的内部机理
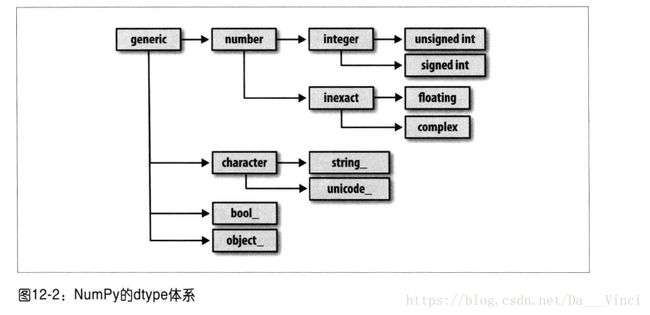
NumPy数据类型体系
高级数组操作--数组重塑
数组的合并和拆分
堆叠辅助类:r_和c_
元素的重复操作:tile和repeat
花式索引的等价函数:take和put
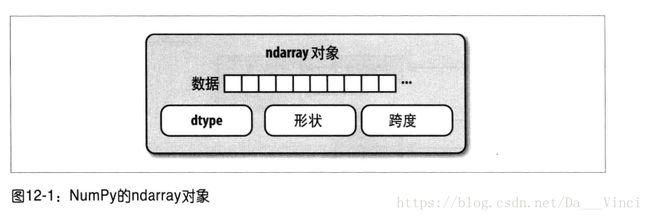
ndarray对象的内部机理
Numpy的ndarray提高了一种将同质数据块(可以是连续的跨越的)解释为多维数组的对象的方式。正如你之前所看到的那样,数据类型决定了数据的解释方式,比如浮点数,整数,布尔值等等。
ndarray如此强大的一个原因是所有的数组对象都是数据块的一个跨度视图。(strided view),ndarray不止是一块内存和dtype,它还有跨度信息,这使得数组能够以各种幅度在内存中移动,更准确的讲,ndarray内部由以下内容组成:
*一个指向数组(一个系统内存)的指针。
*数据类型或dtype
*一个表示数组类型(shape)的元组,例如,一个10*5的数组,其形状为(10,5)
*一个跨度元组(stride),其中的整数指的是为了前进到当前纬度下一元素需要跨过的字节数,例如,一个典型的3*4*5的float数组,其跨度为(160,40,8)
NumPy数据类型体系
>>> import numpy as np
>>> ints = np.ones(10,dtype=np.uint16)
>>> ints
array([1, 1, 1, 1, 1, 1, 1, 1, 1, 1], dtype=uint16)
>>> float = np.ones(10,dtype = np.uint32)
>>> float = np.ones(10,dtype = np.float32)
>>> float
array([1., 1., 1., 1., 1., 1., 1., 1., 1., 1.], dtype=float32)
>>> np.issubdtype(ints.dtype,np.integer)
True
>>> np.issubdtype(float.dtype,np.float32)
True
>>> np.issubdtype(float.dtype,np.float)
True查看所有父类
>>> np.float64.mro()
[, , , , , , ]
高级数组操作--数组重塑
改变数组的形状
>>> arr = np.arange(8)
>>> arr
array([0, 1, 2, 3, 4, 5, 6, 7])
>>> arr.reshape((4,2))
array([[0, 1],
[2, 3],
[4, 5],
[6, 7]])
>>> arr.reshape((4,2)).reshape((2,4))
array([[0, 1, 2, 3],
[4, 5, 6, 7]])
作为参数的纬度可以是-1,它表示纬度大小有数据本身推断出来
>>> arr = np.arange(15)
>>> arr.reshape((5,-1))
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]])
>>> arr.reshape((3,-1))
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])
由于数组的shape属性是一个元组,因此他也可以被传入reshape:
>>> other_arr = np.ones((3,5))
>>> other_arr.shape
(3L, 5L)
>>> arr.reshape(other_arr.shape)
array([[ 0, 1, 2, 3, 4],
[ 5, 6, 7, 8, 9],
[10, 11, 12, 13, 14]])将多维数组展开的运算过程称为扁平化---降维打击
>>> arr = np.arange(15).reshape((5,3))
>>> arr
array([[ 0, 1, 2],
[ 3, 4, 5],
[ 6, 7, 8],
[ 9, 10, 11],
[12, 13, 14]])
>>> arr.ravel()
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14])
C和ForTran顺序
与其他科学计算环境相反,NumPy允许你更为灵活地控制在内存中的布局。
默认情况下NumPy是按行优先顺序创建的,在空间方面,这就意味着,对于一个二维数组,每行的数据是存在相邻的行上,另一种是按列优先存放的
C成为行优先,Fortran成为列优先。
>>> arr = np.arange(12).reshape((3,4))
>>> arr
array([[ 0, 1, 2, 3],
[ 4, 5, 6, 7],
[ 8, 9, 10, 11]])
>>> arr.ravel()
array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11])
>>> arr.ravel('F')
array([ 0, 4, 8, 1, 5, 9, 2, 6, 10, 3, 7, 11])
C/行优先顺序:现经过更高的纬度,例如轴1会优先于轴0被处理
Fortran/列优先顺序:后经过更高的纬度,例如,轴0会先于轴1被处理。
数组的合并和拆分
>>> import numpy as np
>>> arr1 = np.array([[1,2,3],[4,5,6]])
>>> arr2 = np.array([[7,8,9],[10,11,12]])
>>> np.concatenate([arr1,arr2],axis=0)
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
>>> np.concatenate([arr1,arr2],axis=1)
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]])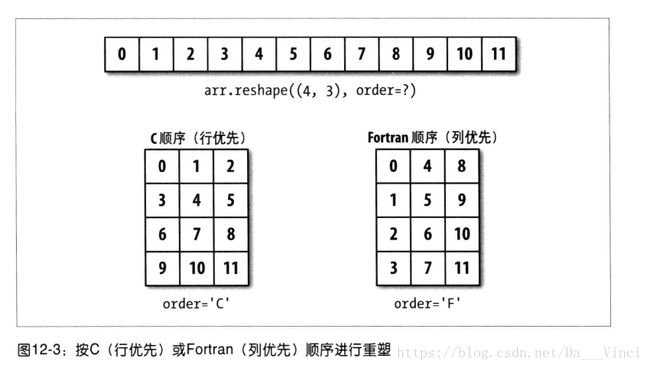
其他方法
>>> np.vstack((arr1,arr2))
array([[ 1, 2, 3],
[ 4, 5, 6],
[ 7, 8, 9],
[10, 11, 12]])
>>> np.hstack((arr1,arr2))
array([[ 1, 2, 3, 7, 8, 9],
[ 4, 5, 6, 10, 11, 12]])拆份矩阵
>>> from numpy.random import randn
>>> arr = randn(5,2)
>>> arr
array([[ 0.97856788, -1.37528149],
[ 0.55720216, -0.58241076],
[-0.26465266, -1.46150681],
[ 0.11445839, -0.66410352],
[ 0.44568727, -1.0911138 ]])
>>> first,second,third = np.split(arr,[1,3])
>>> first
array([[ 0.97856788, -1.37528149]])
>>> second
array([[ 0.55720216, -0.58241076],
[-0.26465266, -1.46150681]])
>>> third
array([[ 0.11445839, -0.66410352],
[ 0.44568727, -1.0911138 ]])

堆叠辅助类:r_和c_
Numpy命名空间中有两个特殊对象---r_和c_,他们可以使数组的堆叠操作更为简洁:
>>> arr = np.arange(6)
>>> arr1 = arr.reshape((3,2))
>>> arr2 = randn(3,2)
>>> np.r_[arr1,arr2]
array([[ 0. , 1. ],
[ 2. , 3. ],
[ 4. , 5. ],
[-0.32236699, 0.87641534],
[-1.10413826, -0.84423609],
[ 1.52870818, -1.63998148]])
>>> np.c_[arr1,arr2]
array([[ 0. , 1. , -0.32236699, 0.87641534],
[ 2. , 3. , -1.10413826, -0.84423609],
[ 4. , 5. , 1.52870818, -1.63998148]])
>>> np.c_[np.r_[arr1,arr2],arr]
array([[ 0. , 1. , 0. ],
[ 2. , 3. , 1. ],
[ 4. , 5. , 2. ],
[-0.32236699, 0.87641534, 3. ],
[-1.10413826, -0.84423609, 4. ],
[ 1.52870818, -1.63998148, 5. ]])
>>> np.c_[1:6,-10:-5]
array([[ 1, -10],
[ 2, -9],
[ 3, -8],
[ 4, -7],
[ 5, -6]])元素的重复操作:tile和repeat
repeat会将数组每个元素重复一定次数,从而产生一个更大的数组
>>> arr = np.arange(3)
>>> arr.repeat(3)
array([0, 0, 0, 1, 1, 1, 2, 2, 2])参数为数组,次数就为数组内元素
>>> arr.repeat([2,5,1])
array([0, 0, 1, 1, 1, 1, 1, 2])>>> arr = randn(2,2)
>>> arr
array([[ 0.62378524, 0.58608875],
[-2.102162 , -0.20826398]])
>>> arr.repeat(2,axis=0)
array([[ 0.62378524, 0.58608875],
[ 0.62378524, 0.58608875],
[-2.102162 , -0.20826398],
[-2.102162 , -0.20826398]])
>>> arr.repeat(3,axis=1)
array([[ 0.62378524, 0.62378524, 0.62378524, 0.58608875, 0.58608875,
0.58608875],
[-2.102162 , -2.102162 , -2.102162 , -0.20826398, -0.20826398,
-0.20826398]])
tile的功能是沿指定轴向堆叠数组的副本。你可以形象的将其想象成‘铺瓷砖’
>>> np.tile(arr,2)
array([[ 0.62378524, 0.58608875, 0.62378524, 0.58608875],
[-2.102162 , -0.20826398, -2.102162 , -0.20826398]])
>>> np.tile(arr,(3,2))
array([[ 0.62378524, 0.58608875, 0.62378524, 0.58608875],
[-2.102162 , -0.20826398, -2.102162 , -0.20826398],
[ 0.62378524, 0.58608875, 0.62378524, 0.58608875],
[-2.102162 , -0.20826398, -2.102162 , -0.20826398],
[ 0.62378524, 0.58608875, 0.62378524, 0.58608875],
[-2.102162 , -0.20826398, -2.102162 , -0.20826398]])
花式索引的等价函数:take和put
>>> arr = np.arange(10)*100
>>> inds = [7,1,2,6]
>>> arr
array([ 0, 100, 200, 300, 400, 500, 600, 700, 800, 900])
>>> arr[inds]
array([700, 100, 200, 600])
ndarray有两个专门用于获取和设置单个轴向上的选区:
>>> arr.take(inds)
array([700, 100, 200, 600])
>>> arr.put(inds,42)
>>> arr
array([ 0, 42, 42, 300, 400, 500, 42, 42, 800, 900])
>>> arr.put(inds,[1,111,11111,222222])
>>> arr
array([ 0, 111, 11111, 300, 400, 500, 222222, 1,
800, 900])在其他轴上使用take,只需传入axis关键字即可:
[2,0,2,1]对应数组第一行的坐标,即是无参数是使用自己的元素填充
>>> inds=[2,0,2,1]
>>> arr = randn(2,4)
>>> arr
array([[ 0.37017406, 0.83873575, -1.49859514, 0.03938596],
[ 0.03290924, -0.1093802 , -0.17473124, 0.0457244 ]])
>>> arr.take(inds,axis=1)
array([[-1.49859514, 0.37017406, -1.49859514, 0.83873575],
[-0.17473124, 0.03290924, -0.17473124, -0.1093802 ]])