LTR那点事—AUC及其与线上点击率的关联详解
LTR(Learning To Rank)学习排序是一种监督学习(SupervisedLearning)的排序方法,现已经广泛应用于信息索引,内容推荐,自然语言处理等多个领域。以推荐系统为例,推荐一般使用多个子策略,但哪个策略更好?每个策略选出多少候选集?每个候选集呈现的顺序如何排序?这些问题只能根据经验进行选择,随着策略越来越多,上述问题对推荐效果的影响会越来越大。于是乎,人们很自然的想到了用机器学习(Machine Learning)了解决上述问题,至此LTR就出世和大家见面了。发展到现在,LTR已经形成较为成熟的理论基础,并且可以解决数据稀疏、过拟合等多种问题,在实际应用中取得较好的效果。
做过LTR的人都知道AUC是机器学习中非常重要的评估指标,AUC的提升会带来线上点击率的提升,其值越高越好,最大值为1。那么AUC到底是个什么东东呢?为什么AUC的提升就一定会带来点击率的提升?本文就带大家一起了解下AUC的概念及其与线上点击率的关联。
一、AUC概念与计算方法
AUC是Area Under Curve的缩写,实际就是曲线下的面积。那么这条曲线是什么呢?AUC又要怎么求呢?别急,听我细细道来。
通常在训练模型时,我们需要从日志里获得某一天或者某几天的数据作为训练集,选取另外某一天或者某几天的作为验证集(通常训练集时间先于验证集时间)。日志里是一条一条的记录(通常包括用户标识、item标识、操作时间、操作类型等等),对于某一条记录,有用户点击的我们标记为1,代表用户对当前的item感兴趣,点击观看了(当然不考虑手抽点到的);对于展示但是用户未点击的我们标记为0,代表用户不感兴趣。在LTR中,根据训练集对模型进行训练,训练好的模型会为验证集的每一条记录打分,那么对于用户行为是点击的记录,我们希望得分高一些;而对于用户行为是不点击的记录,我们希望得分低一些,这样预测分数就可以代表用户对当前item的兴趣大小。AUC就是用来比较有点击记录的得分与无点击记录的得分是否满足上述关系的指标。这里需要强调的是AUC仅仅用来比较有点击与无点击的记录,不用来比较有点击之间或者无点击之间的关系(比如A记录中用户点击并且对该次展示极感兴趣,而B记录中用户对该次展示没有兴趣只是不小心点到,所以A记录得分理应高于B,但这不属于AUC的考虑范围)。
说了这么多,大家可能还不是很明白,到底AUC怎么计算呢?举个例子如下:
下表中有如下6条记录:

这里我们无法预知同为用户点击过的A和D两条记录到底谁的得分更应该高一些,也无法预知其余四条未点击的记录谁的得分应该更低一些。但是根据AUC的概念,A和D的得分应该高于其余四条记录中的任意一条。下面开始计算AUC的流程:
我们需要将记录A、D分别与另外四条记录比较,一共有8组对比。这里计算AUC的分母就是8;那么共有多少组对比是满足要求的呢?记录A比另外四组(B、C、E、F)得分都高,记录D只比另外二组(E、F)得分都高,所以八组对比中满足条件的只有6组,那么分子就是6。所以我们计算得到的AUC就是6/8 = 0.75。简单吧?好像确实不是很难耶!
下面对AUC的计算做一个简单总结:通过模型对验证集中的每条记录做一个预测。这些记录中有点击行为的记录数为M,未点击的记录数为N,则用有M*N组对比。对于有点击的M条记录分别记为p1、p2、……pM,对于其中任意一条记录Pi,其预测分数高于未点击记录的个数为记做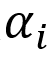 ,则满足条件的对比组为
,则满足条件的对比组为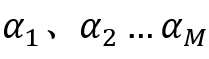 的累积和,除以M*N就是本次记录组中AUC的结果。我们需要对比有点击行为的记录与无点击行为的记录,要求有点击行为记录的预测分数高于无点击行为记录的预测分数,AUC就是衡量满足要求的对比数占总对比数的指标。
的累积和,除以M*N就是本次记录组中AUC的结果。我们需要对比有点击行为的记录与无点击行为的记录,要求有点击行为记录的预测分数高于无点击行为记录的预测分数,AUC就是衡量满足要求的对比数占总对比数的指标。
二、小样,穿个马甲就不认识你了?!
上一小节中介绍了如何计算AUC,相信大家已经掌握了原理和计算方法。其实网上大部分介绍AUC的文章如出一辙,但是好像都不是上述方法,二者一样吗?难不成AUC有两种计算方式?下面就进行一下对比,看看到底咋回事。
看过网上介绍AUC的同学一定都知道下面四个概念:
True negative(TN),称为真阴,表明实际是负样本预测成负样本的样本数
False positive(FP),称为假阳,表明实际是负样本预测成正样本的样本数
False negative(FN),称为假阴,表明实际是正样本预测成负样本的样本数
True positive(TP),称为真阳,表明实际是正样本预测成正样本的样本数
大家可能看的有点头晕,下面在用更通俗的语言描述下:
-
TN,预测是负样本,预测对了
-
FP,预测是正样本,预测错了
-
FN,预测是负样本,预测错了
-
TP,预测是正样本,预测对了
前文已经说了AUC实际是曲线下的面积,那么这条曲线是什么呢?有了上述概念我们就可以画出这条曲线了,其横坐标是False Positive Rate(假阳率,FPR),纵坐标是True Positive Rate(真阳率,TPR),那这两个指标怎么算呢?公式如下:
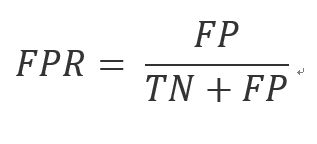
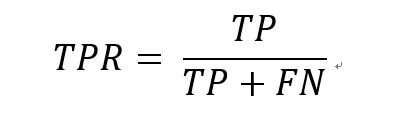
到现在为止,基本画AUC曲线所需要了解的概念都描述了,大家晕了吗?反正我是晕了,这和上一节介绍的计算AUC的方法是一样的吗?
答案直接而有坚定:是!!!
那么该如何理解呢?说到这里就不得不提阀值的概念。对于某个二分类分类器来说,涉及最多的阀值就是0.5了,对于每一次预测大于0.5的认为是正样本,小于0.5的认为是负样本。那么AUC曲线中阀值是多少呢?这里的阈值很多,我们可以把下述曲线理解成一个个小长方形,每一个长方形对应于每一个阀值。下面描述如何选取阀值与画出这些小长方形。
这里仍然假定共M有个正样本(用户点击)与N个负样本(用户未点击),分别对个M正样本与N个负样本的预测分数进行降序排列,对应的序号分别为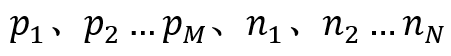 ,对应的预测分数分别为
,对应的预测分数分别为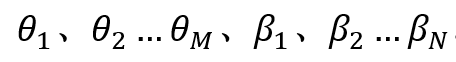 。这里阈值就是负样本分数
。这里阈值就是负样本分数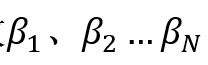 。首先选取作为阀值(分数>=阀值为正样本,<阀值为负样本),则此时负样本中仅有的p1满足预测分数大于等于阀值(实际是等于),故假阳率为
。首先选取作为阀值(分数>=阀值为正样本,<阀值为负样本),则此时负样本中仅有的p1满足预测分数大于等于阀值(实际是等于),故假阳率为![]() ;对应的正样本预测分数有
;对应的正样本预测分数有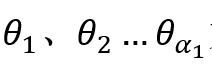 大于等于阀值,共
大于等于阀值,共![]() 个,真阳率
个,真阳率![]() ,对应的第一个长方形的面积
,对应的第一个长方形的面积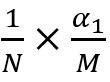 。接着选
。接着选![]() 作为阀值,此时假阳率
作为阀值,此时假阳率![]() ,但对应于第二个长方形的宽还是
,但对应于第二个长方形的宽还是![]() (需减去前一个长方形的宽),正样本预测分数中
(需减去前一个长方形的宽),正样本预测分数中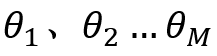 大于阀值共
大于阀值共![]() 个。由于
个。由于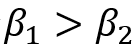 ,则必有
,则必有 ,这也解释了曲线中y随着x的增大而增大。此时真阳率
,这也解释了曲线中y随着x的增大而增大。此时真阳率![]() ,对应的第二个长方形的面积为
,对应的第二个长方形的面积为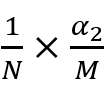 ……将根据阈值划分的各小长方形累加得到曲线下的面积也就是AUC,其表达形式为
……将根据阈值划分的各小长方形累加得到曲线下的面积也就是AUC,其表达形式为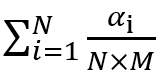 ,分子是满足条件的对比组,分母是总对比组,形式与第一节介绍的计算AUC的表达式一模一样!
,分子是满足条件的对比组,分母是总对比组,形式与第一节介绍的计算AUC的表达式一模一样!
这里我们选取负样本的得分作为阀值,当然也可以选取正样本的分数作为阀值。则横坐标是False negative Rate(假阴率,FNR)纵坐标是True Negative Rate(真阴率,TNR),对应公式如下:
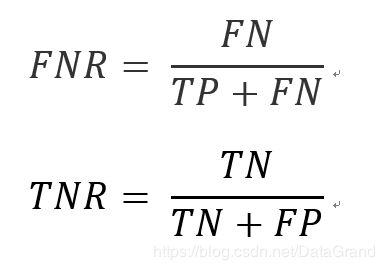
对正负样本预测分数进行升序排列,依次选取正样本的分数作为阀值,最后得到的结果与上述表达式一致。
至此,我们已经详细描述了如何计算AUC,最后补上AUC的一般判断标准
0.5~0.7:效果较低
0.7~0.9:效果不错,可用于上线
0.9~1.0:效果超级好,但是一般情形下很难达到
三、AUC与线上点击率的关联
晚上加班回家洗完澡,打开**头条,翻到推荐页面,映入眼帘的几条推荐内容都是我特别感兴趣的,好了不往下面翻了,把当前页面的看完再说;翻着翻着,没啥意思了,再看看时间不早了,算了睡吧明天还要早起呢。不看了睡觉吧 zzz。
通过上述可以看出大家对于推荐栏靠前的内容更容易点击,当然不排除有些人喜欢先翻个几下子在看的,如果这样那么LTR可能反而会降低客户体验,所以LTR优化时我们是不考虑这部分用户。LTR就是对于某一个特定用户,根据模型对召回的不同item的预测分数进行降序排列,如果AUC足够高,则根据预测分数进行排序的结果与用户真实兴趣排序的结果相符,这也是为什么我们要提高AUC的原因。将用户感兴趣的item优先展示,可以提高用户的点击数同时降低入屏但是不点击的数目,从而提高点击率,产生较好的用户体验。
四、AUC真的好吗?
通过上面我们可以看出,AUC正比于线上点击率。现在市面上各种app都在追求用户流量,高质量的推荐内容可以获得更好的用户体验从而获得更多的用户流量。所以线下训练模型是一般追求AUC的提升,但AUC高就一定好吗,请看下面两组数据对比:
第一组:
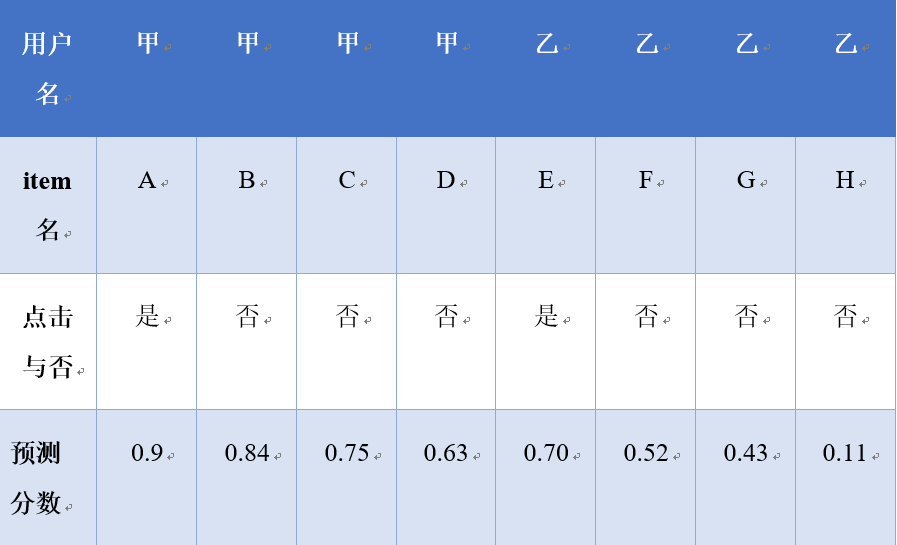
根据之前介绍的AUC计算方式可以得到这一组数据的AUC为![]()
第二组:

根据之前介绍的AUC计算方式可以得到这一组数据的AUC为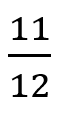
通过对比AUC大家显然觉得第二组数据对应的模型性能更好。
真的吗?
真的是这样吗?
对于第一组数据,表中分别包含甲乙两个用户,对于这两个用户而言,预测分数大小关系完全符合用户点击行为与否,故模型在这两个用户上已不需要优化。对于第二组数据,丁用户各条记录的预测分数大小关系不完全符合用户点击行为(有点击行为的E预测分数低于无点击行为的F),故第二组数据对应的模型还需要优化。对比之前AUC,第二组的模型优于第一组,这里矛盾到底在哪里呢?分析如下:
第一组数据中共有2个正样本,6个负样本共12组对比,不满足条件的共两组(用户甲-itemB,用户乙-itemE), (用户甲-itemC,用户乙-itemE),可以发现这两组数据都是比较不同的用户,我们做LTR的目的是为了对每个用户推荐的item正确排序,不必理会不同用户间的item。表1可以看出用户甲的预测分数普遍偏高而用户乙的分数普遍偏低,这种趋势与item无关,仅仅取决于用户,所以比较不同用户之间的预测分数是没有意义的。如果我们用AUC来作为最终的判断标准会出现表1的情形,用户甲乙都满足LTR的排序,但是整体的AUC还是小于1。
上面说明了AUC作为LTR的指标的局限性,那么该如何选取呢。还是以表1为例,单独看甲乙两个用户,用户甲的AUC是1,用户乙的AUC也是1,则总体AUC肯定是1。这里阿里巴巴提出了GAUC的概念,g是group的缩写,顾名思义就是分组AUC,分组的依据是用户名,根据不同的用户名分组得到不同用户的AUC,然后在加权平均得到最终的GAUC。这样就避免了不同用户之间的比较,消除了用户间差异。
现在剩下最后一个问题了,算出了不同用户的AUC如何进行加权得到GAUC呢。这里阿里巴巴也没有给出确切的公式,可以依据各用户的点击数或者是各用户的展示数。下面做一个简单的公式推导:
以推荐系统来说,LTR是为了提高用户的点击率,这里用户点击用![]() 表示,展示数目用
表示,展示数目用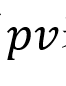 表示。假设有三个用户,点击数分别为
表示。假设有三个用户,点击数分别为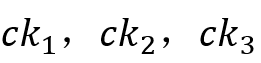 ,展示数目分别为
,展示数目分别为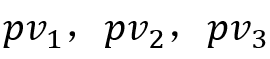 点击率分别为
点击率分别为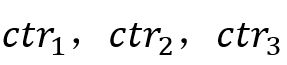 ,则总体可表示为
,则总体可表示为
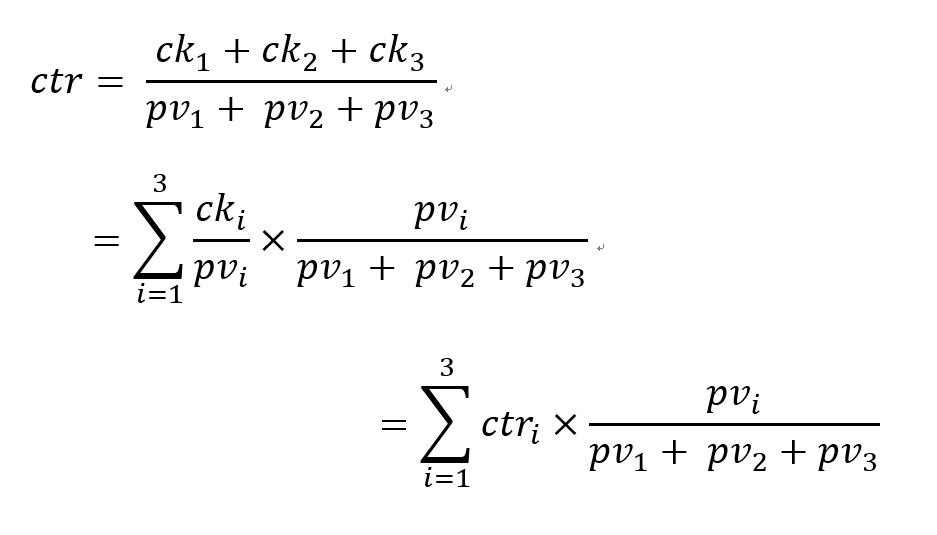
可以看出总体点击率是不同用户的根据展示数进行加权得到的,所以不同用户根据展示数加权得到GAUC是合理的。
但是这里不能忽略一个问题,AUC是预测分数满足大小关系的正负对占总的正负对的比值,对比数越多,AUC就越准确。假如两个用户都展示了10条,其中一个用户点击了1条,那么该用户对应的AUC有9组对比;另一个用户点击了5条,那么该用户对应的AUC有25组对比,显然计算GAUC时后一个用户对应的AUC的权重应该大一点。这里全球领先的文本职能处理专家—达观数据公司提出从从AUC的定义出发来计算GAUC。这里将各用户计算AUC的分子相加作为计算GAUC的分子,各用户计算AUC的分母相加作为计算GAUC的分母,由于模型不会偏向于任意用户,故这种计算GAUC的方法是较为准确的。大家也可以在实际工程中应用。
总结
本文首先介绍了AUC的基本概念和计算方法,同时对比了两种计算AUC的方法,其不过是最终表达式的两种展现形式。接着描述了AUC与线上点击率的关联。最后补充了AUC的不足同时引出了GAUC,用以消除用户间的差异,同时提出了一种新的计算GAUC的方法。
关于作者
徐祥:达观数据智能推荐算法工程师,负责达观数据智能推荐算法中模型的优化,对策略召回的结果进行重排序。对特征工程,模型优化有深入研究。