基于预训练词向量的文本相似度计算-word2vec, paddle
文章目录
- 0. 前言
- 1. 余弦相似度算子
- 2. 示例代码并验证
- 3. 基于词向量的文本相似度
- 3.1 读取word2vec文件
- 3.2 定义模型
- 3.3 运行模型
- 3.4 根据分数降序排列
- 3.5 结果
- 4. 完整语料下的实验
- 5. 可能有用的资料
- 6. 完整代码
0. 前言
原本以为这东西很常见,但说实话,在网上很少找到真正想要的东西,所以自己根据原理写了点代码。
【paddlepaddle】tf原理相同
基于预训练词向量的文本相似度计算原理:
用已知单词的向量A 和 其他一组待选向量B 分别计算余弦相似度,再根据结果的大小进行排序。
1. 余弦相似度算子
查看官网:paddle.fluid.layers.cos_sim(X, Y)

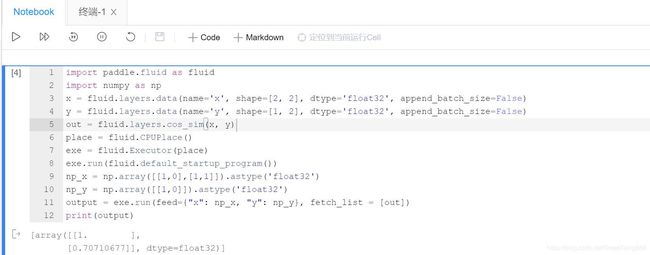
2. 示例代码并验证
验证向量
[1,0]与[1,0]的余弦相似度,(1.0)
[1,1]与[1,0]的余弦相似度。(0.707)
代码:
import paddle.fluid as fluid
import numpy as np
x = fluid.layers.data(name='x', shape=[2, 2], dtype='float32', append_batch_size=False)
y = fluid.layers.data(name='y', shape=[1, 2], dtype='float32', append_batch_size=False)
out = fluid.layers.cos_sim(x, y)
place = fluid.CPUPlace()
exe = fluid.Executor(place)
exe.run(fluid.default_startup_program())
np_x = np.array([[1,0],[1,1]]).astype('float32')
np_y = np.array([[1,0]]).astype('float32')
output = exe.run(feed={"x": np_x, "y": np_y}, fetch_list = [out])
print(output)
结果:
3. 基于词向量的文本相似度
先实验,小文本的词向量。
3.1 读取word2vec文件
见前文:paddlepaddle加载预训练词向量
数据:
test300d.txt:
3 300
, -0.225854 0.107560 0.197237 -0.163468 0.090813 0.040628 0.176729 -0.011261 -0.053033 0.037572 -0.155545 0.053847 0.131007 0.250081 -0.071398 -0.089812 -0.034247 0.078562 0.023870 0.159746 0.100427 0.021786 0.266321 0.004339 0.105988 -0.002758 0.119828 0.004190 -0.154152 0.087963 0.179135 0.041696 -0.150765 0.112602 -0.003246 -0.115960 0.042190 0.108845 0.138592 -0.270801 0.276069 -0.377507 -0.133841 0.225290 -0.084972 -0.046473 -0.163377 -0.129677 0.178721 -0.008124 -0.037467 0.291655 0.144279 -0.118583 0.046584 0.021907 0.126214 0.054273 0.048182 0.079335 -0.126211 0.045360 -0.099212 -0.016365 -0.009512 -0.038277 -0.152457 0.013738 -0.210855 -0.151658 0.068768 0.310373 0.086278 0.065519 0.089834 0.264020 0.206357 -0.046300 0.111625 -0.112923 0.025023 0.266332 0.238958 -0.112658 0.037161 -0.228547 0.048586 0.243026 -0.143488 0.045040 0.028236 0.096553 0.011036 0.119268 0.068397 -0.000245 -0.011066 -0.096202 -0.020504 -0.104224 -0.152824 -0.126277 0.003383 0.146738 0.034192 -0.063062 -0.100550 0.081958 0.297142 -0.095431 0.047876 0.045076 0.061213 -0.103860 -0.046096 -0.108332 0.083888 -0.170114 0.091852 -0.111302 0.036355 0.048322 0.048027 -0.133125 -0.173485 -0.062455 0.133545 0.264515 -0.199027 -0.134663 -0.176003 -0.073278 -0.071808 -0.067675 0.065894 -0.061778 -0.207889 -0.035713 0.129135 0.160631 0.064196 0.036111 -0.037556 -0.123741 0.070222 -0.011605 0.095488 -0.026130 0.176827 0.135286 -0.091638 -0.196278 0.135840 -0.067259 -0.066008 -0.207676 -0.178852 -0.009413 -0.113950 0.196629 -0.114693 -0.026324 -0.141586 0.197364 -0.078522 -0.162726 0.052150 0.003707 0.034934 -0.067691 -0.014802 0.025208 -0.012278 0.014441 0.015678 0.044566 0.007233 -0.030680 -0.075503 0.143719 0.075201 0.141424 -0.038741 0.120257 0.066381 0.028938 -0.026662 0.052459 0.103320 -0.057982 0.058221 0.058726 -0.196115 -0.118826 -0.017446 0.047007 0.301567 0.037915 -0.147273 0.340786 -0.015451 -0.004354 0.009008 -0.036533 0.171037 0.224140 -0.119820 0.302488 -0.036199 -0.200074 0.108383 0.048416 0.059023 0.092124 0.024632 0.049616 -0.205193 0.018068 -0.330599 0.047790 -0.031321 -0.066260 -0.077764 0.274229 -0.157499 -0.090307 -0.057102 0.099106 0.094118 -0.152254 -0.012646 0.065620 0.032115 0.122921 0.051477 0.019677 0.321413 0.100348 -0.195362 0.033550 0.171877 -0.054965 -0.090468 -0.046022 -0.023165 0.142064 0.160361 -0.100200 0.114204 -0.251116 -0.020862 0.259914 0.010826 -0.333081 -0.029773 -0.106668 -0.066178 -0.055028 0.032080 0.081552 0.237320 0.034470 0.116792 -0.054930 0.035778 -0.171559 -0.077482 0.091026 -0.050017 0.080905 -0.356599 -0.044822 -0.058992 0.191774 0.001098 0.036497 -0.047119 -0.051166 0.028191 0.230730 -0.093177 -0.086363 -0.153171 -0.000628 0.028436 -0.117305 -0.154677 -0.030172 -0.073724 0.022715 -0.036977 0.059616 0.153312 -0.103805 0.231885 0.247361 -0.134653 0.142064 0.144121 0.005673
的 -0.242538 0.100439 0.129818 -0.104647 -0.028103 0.058042 0.190883 0.153426 0.034308 0.071330 -0.000116 0.113657 0.097657 0.030841 0.060856 0.056382 -0.195434 0.031622 0.003772 0.059192 -0.021331 -0.109444 0.192544 0.012395 0.107907 0.179732 0.216159 -0.004080 -0.127886 0.022992 0.169664 0.191425 -0.022217 -0.095708 0.075299 -0.169385 0.042564 0.002497 0.033388 -0.279786 0.135520 0.028730 -0.006901 0.183539 0.175054 0.166405 0.106541 -0.030475 0.122642 -0.196793 0.247228 0.058643 0.177309 -0.197690 -0.088260 0.094268 0.117994 0.031037 0.069194 0.000642 -0.066777 0.101824 -0.002390 0.094974 0.121026 0.153325 -0.304356 0.173549 -0.093552 0.029033 0.101660 0.149433 0.072934 0.143490 0.083457 0.241503 -0.070801 -0.088046 0.003713 -0.280668 -0.001448 0.003456 0.101584 0.131760 -0.223845 -0.309329 0.016964 0.347164 0.132431 -0.111628 -0.138338 -0.064733 0.007556 0.122302 0.184578 -0.078595 -0.140727 -0.192051 -0.086686 -0.038096 -0.097754 -0.052457 -0.018865 0.045217 0.132015 0.010384 -0.070730 -0.116558 0.109532 -0.159887 -0.024422 0.011281 -0.006494 0.021118 -0.021956 0.045676 0.285816 -0.096120 0.045639 0.046192 -0.194560 0.143332 0.013284 0.181637 -0.135146 -0.213470 -0.122927 0.139591 -0.174840 -0.230727 -0.336673 0.028399 0.133554 -0.022328 0.263509 -0.135144 -0.085525 -0.068479 0.147214 0.148020 -0.165846 0.096487 0.216477 -0.130104 0.220343 0.022198 0.081715 0.190736 -0.112020 0.124746 -0.042398 -0.100392 0.217173 -0.025453 -0.261025 -0.122996 -0.065484 0.169312 -0.274064 0.073796 -0.042404 0.003309 -0.026870 0.224915 -0.086456 -0.116525 0.077721 -0.003964 0.094634 -0.345002 -0.055975 0.189918 -0.206350 -0.058314 0.003844 -0.008447 -0.021032 0.057915 0.084640 0.098421 0.103423 0.139302 0.069879 0.235352 -0.012435 -0.214576 0.140327 -0.096340 -0.000419 0.145002 -0.118673 -0.067662 -0.314651 0.103676 0.213736 0.119828 -0.093621 0.300272 -0.054337 0.236886 -0.066297 0.070531 0.055797 -0.052518 -0.042077 0.220657 -0.085996 0.439905 0.213758 -0.013311 0.172127 -0.072370 0.025413 0.129522 0.082697 0.258775 -0.146191 -0.015176 -0.039916 0.097016 0.134828 -0.051018 0.105613 0.200699 -0.085717 -0.149180 -0.140295 -0.099351 -0.072185 0.008729 0.114468 -0.014246 0.211366 0.059199 0.042156 0.000897 0.234377 0.119545 -0.052635 -0.034904 -0.053223 -0.105491 -0.097634 -0.044138 0.039147 0.025329 0.121565 0.042493 0.119284 0.007208 0.110501 0.105863 0.014750 -0.279106 -0.178406 0.028334 -0.144416 0.213126 0.025383 0.247148 0.346476 -0.046433 0.199948 0.019231 0.053996 -0.044669 -0.117902 -0.048377 -0.114109 0.047294 -0.266003 -0.155737 0.022962 -0.032529 -0.112454 0.065954 0.005879 0.160480 -0.098461 0.098248 -0.110154 -0.067323 -0.102438 -0.100263 -0.001491 -0.205655 -0.219179 0.047583 -0.187761 0.135312 0.035478 0.002708 0.039958 -0.083279 0.195324 0.142303 -0.079450 0.133499 0.202978 -0.277668
。 -0.283826 -0.052346 0.080995 -0.139234 0.153747 0.052080 0.152875 0.159906 -0.100812 0.051320 -0.103536 -0.089473 0.056333 0.140998 -0.062160 -0.124558 -0.066892 -0.009883 0.091323 0.173555 -0.096824 0.053216 0.320953 -0.072564 0.084597 -0.016583 0.137165 0.005142 -0.181158 0.144163 0.155581 0.165243 -0.017603 -0.001569 -0.008859 -0.074905 0.062937 -0.126123 0.157542 -0.174461 0.277550 -0.226569 0.105378 0.384084 0.012730 0.064785 0.061948 0.034733 0.245869 -0.052040 -0.061160 0.229989 0.137800 0.058283 0.062240 0.165518 0.029029 0.008543 0.159878 0.128581 -0.132286 -0.042042 -0.064327 -0.029669 -0.012382 0.171713 -0.170834 -0.030781 -0.156063 -0.166197 0.083500 0.245971 0.158185 0.124231 0.016966 0.098247 0.108287 -0.033103 0.110902 0.085093 -0.012798 0.059657 0.207193 0.008308 -0.073832 -0.165532 0.103812 0.138122 -0.223544 -0.129617 0.024598 0.118812 0.023367 0.241243 0.167620 0.045504 0.004117 -0.133555 -0.034388 -0.069076 -0.219639 -0.210766 0.192454 0.116632 -0.013204 -0.170307 -0.193683 0.075764 0.209414 -0.036529 -0.005920 0.164980 0.069390 -0.044813 0.209077 -0.192445 0.179965 -0.183163 0.145443 -0.115985 0.078686 0.064413 0.106028 0.040743 0.007855 -0.077971 0.019152 0.060632 -0.025784 -0.157173 -0.069382 0.041079 0.079359 -0.061446 0.156869 -0.041106 -0.239221 -0.040970 -0.000015 0.099060 -0.247002 -0.020837 0.050309 0.002642 0.118486 -0.029898 0.186345 0.085188 0.178551 0.096495 -0.075727 -0.120875 0.101078 0.074043 -0.114990 -0.139079 -0.132218 0.178934 -0.198598 0.116678 0.085819 -0.047442 -0.343870 -0.023334 -0.127745 -0.187099 0.153834 -0.065911 0.212171 -0.226741 0.007796 0.170214 -0.123449 0.030632 -0.134519 0.026184 0.060357 0.023709 -0.105402 0.059923 -0.054748 0.163454 -0.021259 0.143792 0.039344 -0.113686 0.095763 0.047529 0.053945 -0.024458 -0.035755 -0.034898 -0.117274 -0.140923 -0.051384 0.073058 0.142643 0.218760 -0.172208 0.232220 0.078158 0.015812 0.180485 -0.130071 0.163176 0.193347 0.036909 0.212062 -0.014643 -0.164350 0.269914 -0.020742 0.139275 0.116478 -0.010222 0.046338 -0.163462 0.078293 -0.194750 0.146771 -0.066055 0.023407 -0.031146 0.323978 -0.104894 -0.062218 -0.067920 -0.058051 -0.007136 -0.065643 0.057267 0.005363 0.113890 0.194012 0.130181 0.081436 0.086198 0.065030 -0.172616 0.074657 0.038350 -0.150484 -0.019897 -0.079627 0.163732 0.090669 0.121193 -0.269247 0.119581 -0.304608 0.071850 0.088829 0.151985 -0.040556 -0.166373 -0.112855 -0.022780 0.054751 -0.004542 -0.012059 0.113281 -0.085975 0.213007 0.050355 0.042661 -0.188214 -0.074528 0.242681 -0.223175 0.019245 -0.291517 -0.086909 0.100913 0.090165 0.080523 0.154252 0.056052 0.049938 0.099428 0.266409 -0.078517 -0.211588 -0.247789 -0.061397 0.011922 -0.010878 -0.138854 -0.032372 -0.191472 0.056607 0.051876 0.045863 0.213666 -0.076109 0.197351 0.265458 -0.068780 0.057721 0.142923 -0.091333
cmp_words_test.txt:
2 的
3 。
1 ,
2 的
3.2 定义模型
#定义模型
import paddle.fluid as fluid
source_emd_placeholder = fluid.layers.data(name="source_emd_placeholder", shape=[1], dtype="int64")
targets_emd_placeholder = fluid.layers.data(name="targets_emd_placeholder", shape=[len(targets)], dtype="int64")
#加载用户自定义或预训练的词向量
w_param_attrs = fluid.ParamAttr(
name="w_param_attrs",
initializer=fluid.initializer.NumpyArrayInitializer(embedding),
trainable=False)
#分别查询找到对应的向量
source_emd = fluid.embedding(input=source_emd_placeholder, size=(vocab_size, embedding_dim), param_attr=w_param_attrs, dtype='float32')
targets_emd = fluid.embedding(input=targets_emd_placeholder, size=(vocab_size, embedding_dim), param_attr=w_param_attrs, dtype='float32')
#计算余弦相似度
out = fluid.layers.cos_sim(targets_emd, source_emd)
3.3 运行模型
#运行模型
cpu = fluid.CPUPlace() # 定义运算场所
exe = fluid.Executor(cpu) # 创建执行器
exe.run(fluid.default_startup_program()) # 网络参数初始化
source_data = np.array([source])
targets_data = np.array(targets)
out = exe.run(feed={'source_emd_placeholder':source_data, "targets_emd_placeholder":targets_data},
fetch_list=[out.name])
print(out)
也是不容易啊,debug了好久,可能不熟悉吧。
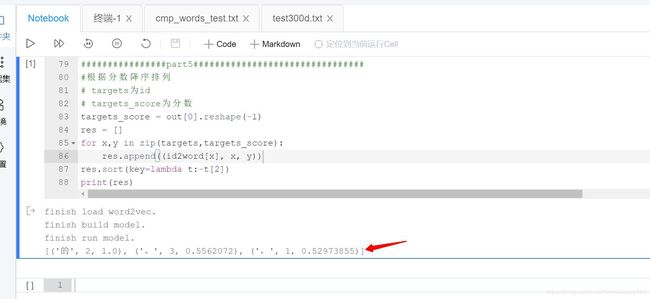
3.4 根据分数降序排列
#根据分数降序排列
# targets为id
# targets_score为分数
targets_score = out[0].reshape(-1)
res = []
for x,y in zip(targets,targets_score):
res.append((id2word[x], x, y))
res.sort(key=lambda t:-t[2])
print(res)
3.5 结果
4. 完整语料下的实验

要占用很大内存:

格式化输出结果:
词汇,id,分数
氨基酸 4002 1.0
必需氨基酸 44271 0.7755669
氨基酸组成 62001 0.73418504
氨基 12738 0.6729062
藻朊酸 596838 0.6598432
胱胺酸 577302 0.6576457
氨基酸态氮 279853 0.64384013
脱辅基 546795 0.6278332
疏基 610569 0.62271315
酸 3998 0.61667526
烟碱酸 281749 0.6043651
氨 11541 0.5966518
二乙氨基乙醇 454456 0.5954937
酮酸 150300 0.59485847
氨基脲 446369 0.5939675
酰基 73607 0.59345376
丙醇二酸 254139 0.592948
植酸 142718 0.59002274
乳清酸 265466 0.5874157
醛基 149175 0.5858586
氨基糖 135819 0.5822417
.
.
.
弘基 267360 0.12416998
朱瞻基 103000 0.12336008
孔柏基 246312 0.11818059
基博 158634 0.11706591
新基 188250 0.11511261
长基 235000 0.101953
德基 127653 0.09511084
建基 206050 0.07800212
排在前面的,非常相似;
排在最后的,几乎没关。
5. 可能有用的资料
1, word2vec词向量训练及中文文本相似度计算 - Eastmount
2, 利用word2vec对关键词进行聚类 - Felven
3, word2vec 词向量工具 - 百度文库
4, Windows下使用Word2vec继续词向量训练 - 一只鸟的天空
5, 使用余弦相似度算法计算文本相似度
6, PaddlePaddle报错解决-holder_ should not be null - GT_Zhang
6. 完整代码
import numpy as np
################part1################################
#加载word2vec文件
filename = "work/test300d.txt"
def loadWord2Vec(filename):
vocab = []
embd = []
cnt = 0
fr = open(filename, 'r', encoding="utf-8")
line = fr.readline().strip()
#print(line) #3 300
word_dim = int(line.split(' ')[1])
vocab.append("unk")
embd.append([0]*word_dim)
for line in fr :
row = line.strip().split(' ')
vocab.append(row[0]) #把第一个字/词加入vocab中
embd.append([np.float32(x) for x in row[1:]]) #把后面一长串加入embd中. 将字符转换成float32
print("finish load word2vec.")
fr.close()
return vocab,embd
vocab,embd = loadWord2Vec(filename)
vocab_size = len(vocab) #1+3
embedding_dim = len(embd[0]) #300
embedding = np.asarray(embd) # numpy格式的词向量数据
################part2################################
#加一个相互索引的词典
id2word = {i:word for i,word in enumerate(vocab)}
word2id = {word:i for i,word in enumerate(vocab)}
#读取待计算的词汇id
path = "work/cmp_words_test.txt"
with open(path, 'r', encoding="utf-8") as f:
source_line = f.readline()
tmp1 = source_line.strip().split("\t")[0]
source = int(tmp1)
targets = []
for item in f.readlines():
tmp2 = item.strip().split('\t')[0]
targets.append(int(tmp2))
# print(source)
# print(targets)
################part3################################
#定义模型
import paddle.fluid as fluid
source_emd_placeholder = fluid.layers.data(name="source_emd_placeholder", shape=[1], dtype="int64")
targets_emd_placeholder = fluid.layers.data(name="targets_emd_placeholder", shape=[len(targets)], dtype="int64")
#加载用户自定义或预训练的词向量
w_param_attrs = fluid.ParamAttr(
name="w_param_attrs",
initializer=fluid.initializer.NumpyArrayInitializer(embedding),
trainable=False)
#分别查询找到对应的向量
source_emd = fluid.embedding(input=source_emd_placeholder, size=(vocab_size, embedding_dim), param_attr=w_param_attrs, dtype='float32')
targets_emd = fluid.embedding(input=targets_emd_placeholder, size=(vocab_size, embedding_dim), param_attr=w_param_attrs, dtype='float32')
#计算余弦相似度
out = fluid.layers.cos_sim(targets_emd, source_emd)
print("finish build model.")
################part4################################
#运行模型
GPU = True
place = fluid.CUDAPlace(0) if GPU else fluid.CPUPlace() # 定义运算场所
exe = fluid.Executor(place) # 创建执行器
exe.run(fluid.default_startup_program()) # 网络参数初始化
source_data = np.array([source])
targets_data = np.array(targets)
out = exe.run(feed={'source_emd_placeholder':source_data, "targets_emd_placeholder":targets_data},
fetch_list=[out.name])
print("finish run model.")
################part5################################
#根据分数降序排列
# targets为id
# targets_score为分数
targets_score = out[0].reshape(-1)
res = []
for x,y in zip(targets,targets_score):
res.append((id2word[x], x, y))
res.sort(key=lambda t:-t[2])
print(res)
点赞+关注,嘿嘿嘿。