python学习笔记分享(四十)网络爬虫(7)反爬虫问题,解决中文乱码,登陆和验证码处理
网络爬虫深度知识
- 一.反爬虫问题
- (一)反爬虫原因
- 1.网络爬虫浪费了网站的流量
- 2.数据是私有资源
- 3.爬虫协议与原则
- (二)反爬虫方式
- (三)反反爬虫
- 1.原理
- 2.三种方法
- 二.解决中文乱码
- (一)编码简介:
- (二)python中编码
- 1.str和bytes
- 2.encode和decode
- (三)解决中文编码问题
- 1.获取网站的中文显示乱码
- 2.非法字符抛出异常
- 3.网页使用gzip压缩
- 4.读写文件中的中文乱码
- 三.登录和验证码处理
- (一)处理登录表单
- 1.构造参数字典
- 2.处理cookie让网页记住登录
- (二)验证码处理
- 1.人工方法处理验证码
- 2.用OCR简单识别验证码图片
一.反爬虫问题
在进行网络爬虫时,反爬虫和反反爬虫是经常会遇到的问题。
(一)反爬虫原因
对于经常用爬虫程序获取网页数据的人来说,遇到反爬虫问题是非常常见的。那么为什么要有反爬虫呢>
1.网络爬虫浪费了网站的流量
由于网络爬虫并不是真正用户的流量。而且不会知道累,会给服务器增加负担,在后面要讲的分布式的多台机器爬取,会造成网站浏览量增高,浪费网站流量。
2.数据是私有资源
数据的价值在如今的时代越来越重要,如果其他人能够很轻易进行获取的话,就会不利于数据所拥有的公司的将来发展。
因此,很多大公司便开始利用技术手段进行反爬虫,不过有时候还必须从他们那里进行数据爬取,因此就有了对付反爬虫的技术–反反爬虫。
3.爬虫协议与原则
不过我们不能够想爬什么就爬什么,那些公司为我们带来了遍历,我们不应当恶意用程序破坏他们的产品,或者侵犯它们的版权。这里就有一个网络爬虫排除标准,我们应当严格按照该标准,并在用反反爬虫技术时,不要对爬取的网站的服务器进行破坏。
(二)反爬虫方式
网站进行反爬虫有三种方式:
(1)不返回网页:如不返回内容和延迟网页返回时间。网站通过IP访问量,session访问量或者User-Agent判断是爬虫这三种方式进行反爬虫。
(2)返回数据非目标网页:如返回错误页,返回空白页和爬取多页时均返回同一页。
(3)增加获取数据的难度:如登录或者登录后输入验证码才能查看数据。
(三)反反爬虫
1.原理
反反爬虫的原理就是让爬虫程序更像是正常用户的浏览行为。
2.三种方法
就是前面讲到的修改请求头,修改爬虫的间隔时间与使用代理。
文章链接如下: 三种方法进行反反爬虫。
二.解决中文乱码
(一)编码简介:
我们在前面的博客中讲到了编码的分类,大家可以在该篇文章中查找:
编码简介
下面就继续详细讲解:
通过以前的只是可以知道,字符串的编码只有两大类。一种是通用的Unicode编码,一种是将Unicode编码转化成某种类型的编码。
Unicode又称统一码,万国码或单一码。为了节省空间,又有了一些中间格式的字符集,被称为通用转换格式Unicode Transformation Format(UTF),常见的有UTF-8与UTF-16。而UTF-8比较常见,且长度可变,用1-4个字节表示一个符号,英文符号通常被编为一个字节,汉字通常被编为3个字节。
(二)python中编码
1.str和bytes
在python3中,字符串编码使用str和bytes两种类型。
(1)str字符串:使用的是Unicode编码。
(2)bytes字符串:使用将Unicode转化为某种形式的编码。
2.encode和decode
(1)encode是将Unicode编码转换为其他编码的字符串。
(2)decode是将其他编码的字符串转换成Unicode编码。
注:在Python3中,unicode不可以再被解码,不同的非unicode编码之间相互转换时,需要先decode解码为Unicode,在编码为其他字符。
(三)解决中文编码问题
中文乱码问题主要有以下几种:
1.获取网站的中文显示乱码
该种情况产生原因是获得的网页的响应体和网站的编码方式不同。可以用网页对象.encoding查看获取的网页响应体的编码。如果要查看网页真正使用的编码的话,就需要用网页审查元素来进行查看。
由于大多数的网页编码为UTF-8编码,因此Requests会自动进行解码,用其他编码的网页相别而说比较少。
2.非法字符抛出异常
有时候在网页编码的时候可能会混入多种编码,就会出现非法字符。但是出错时却找不到出错的地方,这就很令人头疼。其实我们可以采用ignore忽略这些非法字符。在decode中,其实有两个参数,第二个变量为控制错误处理的方式,默认为strict,遇到非法字符时会抛出异常。我们可以把第二个参数设置为其他变量有以下几种方法:
(1)ignore:忽略其中的非法字符,仅显示有效字符。
(2)replace:使用符号代替非法字符。
(3)xmlcharrefreplace:使用XML字符代替非法字符。
3.网页使用gzip压缩
有时候我们用网页的编码获得的数据的中文部分仍旧是乱码,其实可能是网页使用了gzip进行了压缩,这样就必须将其解码才行。而我们使用content函数会自动解码gzip和deflate进行传输。
4.读写文件中的中文乱码
有时候我们需要在读取文件和保存文件的时候注明文件的编码,用encoding属性就可以指明。
三.登录和验证码处理
有时候网页需要登录后才能进行查看,有时还需要输入验证码。这是我们也可以进行反反爬虫。
有关登录的网站我们用斗鱼直播账号进行分析:
[斗鱼直播]https://www.douyu.com/
(一)处理登录表单
有时候我们需要进行登录才能够查看数据,用程序来讲的话就是提交表单,向网页提交我们登录的信息。
在客户端向服务器提交HTTP请求时,有两种方式,一种是GET,一种是POST。使用GET时,查询字符串是在GET请求的URL中发送的。这样数据就会很清楚地出现在URL中,因此不应该用GET方法处理登录表单。
而POST请求则用于提交数据,查询字符串在进行请求的数据字典中,因此就不会把数据暴露在URL中,也不会保存在浏览器历史或Web服务器日志中。
下面就介绍如何处理登录表单。
1.构造参数字典
我们先用网页的审查元素查看登录和密码输入框:
在输入框代码中,name属性的值是参数字典的键(key),而它的值(value)则是我们要输入的用户名。
同理也可以在密码栏中找到我们需要的东西。
这里要注意的是,这个POST请求并不像我们正常登录的那样,有些key值在浏览器中设置了隐藏(hidden)值,是不会显示出来的,但我们可以在审查元素中找出来。
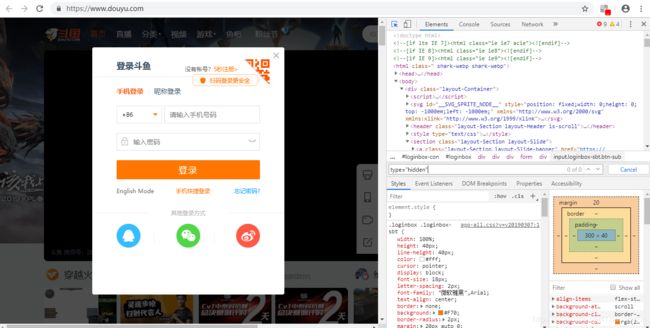
这里我们发现并没有隐藏值,看来斗鱼还是很好的。
有了这些,我们就可以构建POST请求的参数字典,代码如下:
// 参数字典代码
post_data = {
'areaCode' : '+86',
'phoneNum' : '保密',
'password' : '保密',
}
接下来就可以提交表单了,先创建一个session对象:
import requests
session = requests.session()
这里说明一下,session是网站开发中很重要的概念,就是用户在浏览某个网站时,从进入网站到关闭浏览器所经过的这段过程。session对象会存储特定用户进行交互的属性和配置信息。
下面是提交表单的代码:
#coding = UTF-8
import requests
session = requests.session()
url="https://www.douyu.com/"
UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
referer = "https://passport.douyu.com/index/login?passport_reg_callback=PASSPORT_REG_SUCCESS_CALLBACK&passport_login_callback=PASSPORT_LOGIN_SUCCESS_CALLBACK&passport_close_callback=PASSPORT_CLOSE_CALLBACK&passport_dp_callback=PASSPORT_DP_CALLBACK&type=login&client_id=1&state=https%3A%2F%2Fwww.douyu.com%2F&source=click_topnavi_login"
headers = {
"Origin" : "https://passport.douyu.com",
"Referer" : referer,
"User-Agent" : UserAgent,
}
post_data = {
'areaCode' : '+86',
'phoneNum' : '15586537536',
'password' : '191576422q',
}
page = session.post(url,data=post_data,headers=headers)
print(page.status_code)
结果如下:

出现了403信息,这个不是错误,说明了网页禁止访问。下面还有一些常用的网页状态响应码。
| 状态码 | 含义 |
|---|---|
| 303 | 重定向 |
| 400 | 请求错误 |
| 401 | 未授权 |
| 403 | 禁止访问 |
| 404 | 文件未找到 |
| 500 | 服务区错误 |
原来它还需要验证码:
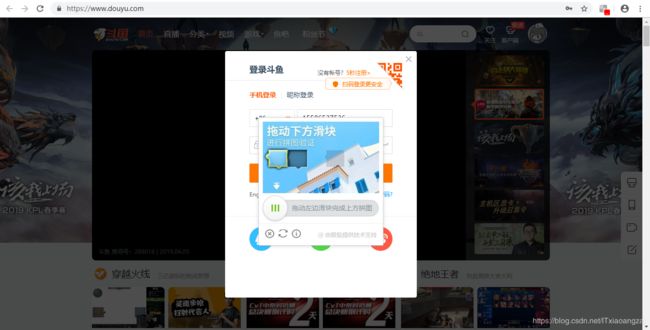
关于验证码的问题,下面会向大家介绍。我们先来一个不需要验证码的登录网页:steam平台
然后我们进行表单登录,代码如下:
#coding = UTF-8
import requests
session = requests.session()
# url="https://www.douyu.com/"
# UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
# referer = "https://passport.douyu.com/index/login?passport_reg_callback=PASSPORT_REG_SUCCESS_CALLBACK&passport_login_callback=PASSPORT_LOGIN_SUCCESS_CALLBACK&passport_close_callback=PASSPORT_CLOSE_CALLBACK&passport_dp_callback=PASSPORT_DP_CALLBACK&type=login&client_id=1&state=https%3A%2F%2Fwww.douyu.com%2F&source=click_topnavi_login"
url = "https://store.steampowered.com/login/?redir=&redir_ssl=1"
UserAgent = "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari/537.36"
referer = "https://store.steampowered.com/login/?redir=&redir_ssl=1"
headers = {
"Referer" : referer,
"User-Agent" : UserAgent,
}
post_data = {
'username' : 保密,
'password' : '保密',
'snr' : '1_60_4__12',
}
page = session.post(url,data=post_data,headers=headers)
print(page.status_code)
结果如下:

2.处理cookie让网页记住登录
网站用session跟踪并将数据存储到本地用户终端上,当之后访问网站时,调用cookie就会是已经登录的状态了。
可以用cookie保存登录的信息,代码如下:
session.cookies.save()
将登录信息存储到本地。
其中,cookies数据是已经加密过的,每一个cookie都会定义四个参数:
| 参数 | 值 |
|---|---|
| Set-Cookie | name=VALUE |
| expires | DATA |
| path | PATH |
| domain | DOMAIN_NAME |
参数说明:
(1)name :cookie的名称,这里一般进行加密处理。
(2)expires :cookie的到期日期和时间。
(3)path:cookie的路径。
(4)domain:cookie所在的域名。
有了保存下来的cookies,我们就可以选择一个登录了。如何登录呢?这里有一个cookiejar库,安装后用下面代码就可以登录了:
import http.cookiejar as coolielib
session = requests.session()
session.cookies = cookielib.LWPCookieJar(filename='cookoes')
try:
session.cookies.load(ignore_discard=True)
except:
print("Cookie未能加载!")
如果Cookie加载成功了,我们就可以进行登录了,这是用get就可以了,不过要在属性中增加一条allow_redirects=False禁止重定向才可以。
(二)验证码处理
验证码是一种区别访问者是否是人类访问,全称是全自动区分计算机和人类的图灵测试,可以防止:恶意破解密码、刷票、论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试。
在网络爬虫中,处理验证码主要有两种方式:
(1)人手输入处理
(2)OCR识别处理
我们通过注册网易邮箱进行讲解。
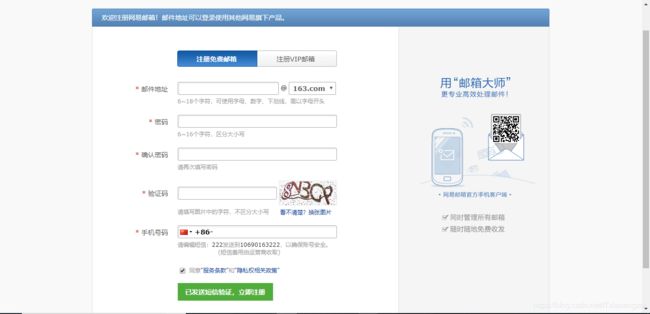
我们发现这里有好多input,这是我们就要找到验证码动态匹配码,然后根据输入的验证码数字与验证码动态匹配码的值进行匹配。
下面分别讲解两种处理方式。
1.人工方法处理验证码
(1)获取验证码动态匹配码
我们可以定义一个函数进入注册页面,用爬虫的知识获得匹配码的值。然后把图片存到源代码所在的地址。
(2)Pillow库将验证码图片打开
这样和手动输入验证码一样,其实效果不大。
2.用OCR简单识别验证码图片
这种方法是通过图像识别技术OCR(光学字符识别)输入验证码的方法。这里需要用到Tesseract库,安装这里就不说了。

先进行去噪
代码如下:
from PIL import Image
import pytesseract
image = Image.open('yanZheng.jpg')
#下面是将彩色图像转化为灰度图像
gray = image.convert('L')
#二值化处理,把大于某个临界灰度值的像素灰度设为灰度极大值,
#把小于某个临界灰度值的像素灰度设为灰度极小值,一般设置为0-1
threshold = 150
table = []
for i in range(256):
if i < threshold:
table.append(0)
else:
table.append(1)
out = gray.point(table,'1')
out.save("chuLii.jpg")
结果如下:

识别代码如下:
import pytesseract
img = Image.open("chuLii.jpg")
print(pytesseract.image_to_string(img))
效果如下: