编译原理期末复习知识点(1)
下一章知识点: https://blog.csdn.net/Jue_Wuu/article/details/106433671
什么是编译
计算机语言分成 高级语言、汇编语言 和 机器语言。计算机只能执行机器语言。从汇编语言到机器语言的过程叫 汇编,从高级语言到汇编语言或直接到机器语言的过程叫 编译。
将高级语言写的源程序转换成可以运行的进程要经历 语言处理系统,编译器只是这个系统中的一环。语言处理系统的典型工作流程为
- 预处理器 将不同文件中源文件聚合到一起,并对宏进行操作;
- 编译器 将处理后的源文件编译为汇编语言程序;
- 汇编器 从汇编语言程序生成可重定位的机器代码(可重定位指在内存中的位置不固定);
- 链接器 会将多个可重定位程序和库连接起来,并处理外部地址(跨文件的引用);
- 加载器 会处理可重定位的地址,变成真实的地址,并将程序装入内存中。
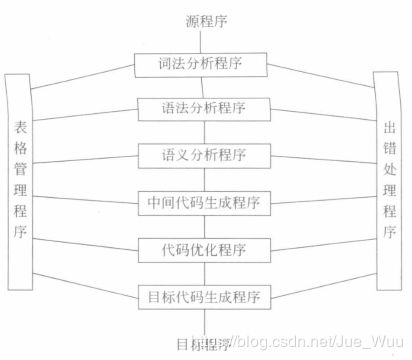
编译系统的结构
编译的本质是翻译,将源语言翻译到目标语言。
假定我们要将一个句子中英文翻译到中文,我们会先尝试了解这个句子的意思,这个意思是独立于任何自然语言的,专业点来说这个叫做 中间语言表示。在这个例子中,为了得到中间语言表示我们需要进行 语义分析;为了进行语义分析需要知道句子中每个短语的成分,这个过程为 语法分析;为了进行语法分析还需要知道每个词的词性,这个过程为 词法分析。
一个典型的编译器的结构可以分成前端和后端。
前端与源语言相关,将源语言翻译为中间表示;
后端语言与目标语言相关,将中间表示翻译为目标语言。
一个完整的编译程序还必须有表格管理程序和出错处理程序
"遍" (趟) 是对源程序或其等价的中间语言程序从头到尾扫描并完成规定任务的规定任务的过程. 多遍比一遍的编译程序少占内存, 逻辑结构更清晰, 但也意味着增加读写中间文件的次数, 势必消耗较多时间, 显然会比一遍的编译程序要慢.
解释程序:
一个个获取, 分析并执行源程序语句, 一旦第一个语句分析完成, 源程序就开始运行并生成结果( 编译程序不把整个程序翻译完,程序无法运行, 把编译和运行独立分开.)
允许在执行时修改程序,
不生成目标代码,直接输出结果.
存储组织不同
程序的解释过程较慢且空间开销较大
词法分析概述
词法分析一般是编译的第一个阶段。
词法分析的主要任务是从左到右扫描扫描源程序字符,识别出各个单词,确定单词的类型,将它们转化成统一的内部表示 词法单元(token)。
每个 token 是一个二元组(种别码,属性值)。其中种别码用来表示这个 token 的类型,属性值作为额外数据进一步表明这个 token 的值。
扫描的过程中可能碰到五类 token,分别为
- 关键词,例如 while、for 这样的。它们的总量是可以枚举的,因此每个关键词都会得到一个种别码,并且属性值可以为空。例如 while 的 token 可能为
- 标识符, 比如变量名、函数名等,这种标识符的总量不可枚举。所有的标识符都是一种种别,例如一个变量 arr 的 token 可能为
- 常量,由于扫描的时候就可以确定常量的类型,尽管常量的取值不可枚举,但是可以按照常量的类型进行分类,并将常量的值作为属性。例如 0.123 的 token 可能为
- 运算符,这个比较简单,和关键词类似,每个运算符都可以分配一个种别码,例如 + 的 token 可能为
- 界定符,这种符号一般是括号、花括号、等号这种作为语句的边界的符号,和运算符的处理类似,不需要属性值。
进行了扫描后,字符流就可以转化为 token 流。
语法分析概述
语法分析一般是编译的第二个阶段。
语法分析的主要任务是根据词法分析器输出的 token 流识别出各类短语,构造 语法分析树(parse tree)。
语法分析树是一棵树,叶结点是各个 token,非叶结点表示的是短语的类型。token 组合起来会形成短语,短语组合起来会形成更大的短语,因此形成了树的形式。
语法分析的过程需要使用到语言的 文法,因为语法分析树的每棵子树中,子树的根结点和它的所有直接子结点正好对应文法中的一个生成式。
进行了语法分析后,token 流就被转化成了多棵语法分析树。
语义分析概述
语义分析的主要任务是收集语义相关的信息。这么说比较抽象,例子是高级语言的语句大多可以分成声明语句和命令语句,对于声明语句,语义分析的任务是收集标识符的属性信息,包括
种属:简单变量、符合变量(数组、结构体等)、函数等
类型:整型、布尔型等
存储的位置和长度
如果是变量的话,变量的 值
作用域
如果是函数的话,参数和返回值类型
这个过程中标识符会被存放到符号表中,符号表中维护了这些标识符的名称以及上述属性信息。
对于命令语句,语义分析可能会进行一些语义检查,例如
变量或过程未定义就使用、或被重复定义
运算分量类型不匹配(数组与过程相加这样的错误)
操作符和操作数之间类型不匹配,例如
数组下标不是整数
使用数组访问操作符访问非数组、使用过程调用操作符调用非过程
过程调用的参数类型或数目不匹配,或者返回值的类型错误
中间代码生成及编译器后端概述
中间代码生成
常用的中间表示有 三地址代码 和 语法结构树(syntax tree)。
语法结构树和前面提到的 parse tree 不是同一个概念。parse tree 是分析树,在语法分析过程后得到,而 syntax tree 是结构树,是一种中间表示。
三地址码
三地址码由类似汇编语言的指令序列构成,每个语句最多只包含三个操作数。
常用的三地址运算符有赋值、复制、条件跳转、无条件跳转、参数传递(类似汇编的 push)、过程调用(类似汇编的 call)、过程返回(类似汇编的 ret)、数组引用、数组赋值、地址及指针的操作等。
三地址码的表示有 四元式、三元式 和 间接三元式。
在四元式中,第一个分量指定语句类型,后三个分量分别是三个操作数,例如 x = y + z 的四元式为 (+, y, z, x)。
因为一句三地址码只能干一件事情,所以 三地址码序列唯一确定了程序的完成顺序。把一个三地址码的序列写出来的话,看上去的效果就跟汇编代码差不多。
代码优化
对前一阶段产生的中间代码进行变换或进行改造, 目的是使生成的目标代码更为高效, 即省时间和省空间
目标代码生成
把中间代码变换成机器上的绝对指令代码或可重位的指令代码或汇编指令代码
Ps.
编译器后端
编译器在 目标代码生成 阶段会将中间表示翻译到目标语言,这个过程中的一个重要任务就是为变量分配合适的寄存器。
编译器可能会进行一些优化,优化可以在两个时间进行
机器无关代码优化,这个优化针对中间表示进行,在目标代码生成过程前完成
机器相关代码优化,这个优化针对目标机器语言进行,在目标代码生成过程后完成