使用CRF++实现命名实体识别
【定义】
CRF++是著名的条件随机场的开源工具,也是目前综合性能最佳的CRF工具,采用C++语言编写而成。其最重要的功能是采用了特征模板。这样就可以自动生成一系列的特征函数,而不用我们自己生成特征函数,我们要做的就是寻找特征,比如词性等。
【安装】
在Windows中CRF++不需要安装,下载解压CRF++0.58文件即可以使用
【语料】
需要注意字与标签之间的分隔符为制表符\t
played VBD O
on IN O
Monday NNP O
( ( O
home NN O
team NN O
in IN O
CAPS NNP O
【特征模板】
模板是使用CRF++的关键,它能帮助我们自动生成一系列的特征函数,而不用我们自己生成特征函数,而特征函数正是CRF算法的核心概念之一。

【训练】

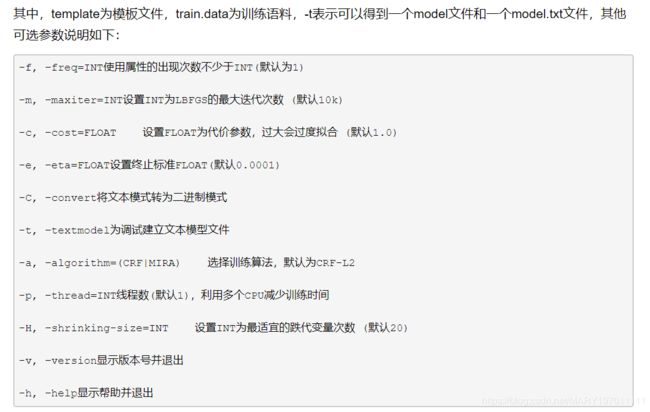

【预测】

【实例】
该语料库一共42000行,每三行为一组,其中,第一行为英语句子,第二行为句子中每个单词的词性,第三行为NER系统的标注,共分4个标注类别:PER(人名),LOC(位置),ORG(组织)以及MISC,其中B表示开始,I表示中间,O表示单字词,不计入NER,sO表示特殊单字词。首先我们将该语料分为训练集和测试集,比例为9:1。
# -*- coding: utf-8 -*-
# NER预料train.txt所在的路径
dir = "/Users/Shared/CRF_4_NER/CRF_TEST"
with open("%s/train.txt" % dir, "r") as f:
sents = [line.strip() for line in f.readlines()]
# 训练集与测试集的比例为9:1
RATIO = 0.9
train_num = int((len(sents)//3)*RATIO)
# 将文件分为训练集与测试集
with open("%s/NER_train.data" % dir, "w") as g:
for i in range(train_num):
words = sents[3*i].split('\t')
postags = sents[3*i+1].split('\t')
tags = sents[3*i+2].split('\t')
for word, postag, tag in zip(words, postags, tags):
g.write(word+' '+postag+' '+tag+'\n')
g.write('\n')
with open("%s/NER_test.data" % dir, "w") as h:
for i in range(train_num+1, len(sents)//3):
words = sents[3*i].split('\t')
postags = sents[3*i+1].split('\t')
tags = sents[3*i+2].split('\t')
for word, postag, tag in zip(words, postags, tags):
h.write(word+' '+postag+' '+tag+'\n')
h.write('\n')
print('OK!')
模板文件template内容如下
# Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
U05:%x[-1,0]/%x[0,0]
U06:%x[0,0]/%x[1,0]
U10:%x[-2,1]
U11:%x[-1,1]
U12:%x[0,1]
U13:%x[1,1]
U14:%x[2,1]
U15:%x[-2,1]/%x[-1,1]
U16:%x[-1,1]/%x[0,1]
U17:%x[0,1]/%x[1,1]
U18:%x[1,1]/%x[2,1]
U20:%x[-2,1]/%x[-1,1]/%x[0,1]
U21:%x[-1,1]/%x[0,1]/%x[1,1]
U22:%x[0,1]/%x[1,1]/%x[2,1]
# Bigram
B
训练该数据
crf_learn -c 3.0 template NER_train.data model -t
在测试集上对该模型的预测表现做评估
crf_test -m model NER_test.data > result.txt
使用Python脚本统计预测的准确率
# -*- coding: utf-8 -*-
dir = "/Users/Shared/CRF_4_NER/CRF_TEST"
with open("%s/result.txt" % dir, "r") as f:
sents = [line.strip() for line in f.readlines() if line.strip()]
total = len(sents)
print(total)
count = 0
for sent in sents:
words = sent.split()
# print(words)
if words[-1] == words[-2]:
count += 1
print("Accuracy: %.4f" %(count/total))
看看模型在新数据上的识别效果
# -*- coding: utf-8 -*-
import os
import nltk
dir = "/Users/Shared/CRF_4_NER/CRF_TEST"
sentence = "Venezuelan opposition leader and self-proclaimed interim president Juan Guaidó said Thursday he will return to his country by Monday, and that a dialogue with President Nicolas Maduro won't be possible without discussing elections."
#sentence = "Real Madrid's season on the brink after 3-0 Barcelona defeat"
# sentence = "British artist David Hockney is known as a voracious smoker, but the habit got him into a scrape in Amsterdam on Wednesday."
# sentence = "India is waiting for the release of an pilot who has been in Pakistani custody since he was shot down over Kashmir on Wednesday, a goodwill gesture which could defuse the gravest crisis in the disputed border region in years."
# sentence = "Instead, President Donald Trump's second meeting with North Korean despot Kim Jong Un ended in a most uncharacteristic fashion for a showman commander in chief: fizzle."
# sentence = "And in a press conference at the Civic Leadership Academy in Queens, de Blasio said the program is already working."
#sentence = "The United States is a founding member of the United Nations, World Bank, International Monetary Fund."
default_wt = nltk.word_tokenize # 分词
words = default_wt(sentence)
print(words)
postags = nltk.pos_tag(words)
print(postags)
with open("%s/NER_predict.data" % dir, 'w', encoding='utf-8') as f:
for item in postags:
f.write(item[0]+' '+item[1]+' O\n')
print("write successfully!")
os.chdir(dir)
os.system("crf_test -m model NER_predict.data > predict.txt")
print("get predict file!")
# 读取预测文件redict.txt
with open("%s/predict.txt" % dir, 'r', encoding='utf-8') as f:
sents = [line.strip() for line in f.readlines() if line.strip()]
word = []
predict = []
for sent in sents:
words = sent.split()
word.append(words[0])
predict.append(words[-1])
# print(word)
# print(predict)
# 去掉NER标注为O的元素
ner_reg_list = []
for word, tag in zip(word, predict):
if tag != 'O':
ner_reg_list.append((word, tag))
# 输出模型的NER识别结果
print("NER识别结果:")
if ner_reg_list:
for i, item in enumerate(ner_reg_list):
if item[1].startswith('B'):
end = i+1
while end <= len(ner_reg_list)-1 and ner_reg_list[end][1].startswith('I'):
end += 1
ner_type = item[1].split('-')[1]
ner_type_dict = {'PER': 'PERSON: ',
'LOC': 'LOCATION: ',
'ORG': 'ORGANIZATION: ',
'MISC': 'MISC: '
}
print(ner_type_dict[ner_type], ' '.join([item[0] for item in ner_reg_list[i:end]]))