【12月16日】THUCTC实现基于支持向量机中文文本分类
基于支持向量机实现中文文本分类
摘要 支持向量机(简称可看作一种广义的线性分类器,其基本思想是:通过非线性变换将输入空间变换到一个高维的特征空间,并在新空间中寻找最优的线性分界面。
关键词 文本分类 特征提取 支持向量机
1引言
所谓“数据丰富但知识缺乏”的现状导致了数据挖掘(Data Mining)技术研究的兴起,数据挖掘是从海量的结构化信息中抽取或挖掘隐含信息和知识的重要方法和途径。其中文本挖掘就是从文本集中挖掘和发现隐含的归纳知识如关联知识、时问序列信息,甚至科学文献的创新推断和假设等。文本挖掘的具体实现技术主要有:特征提取、主题标引、文本分类、文本聚类、自动摘要等。
文本自动分类任务是对未知类别的文字文档进行自动处理, 判别它们所属预定义类别集中的一个或多个类别。 随着各种电子形式的文本文档以指数级的速度增长,有效的信息检索、内容管理及信息过滤等应用变得越来越重要和困难。 文本自动分类是一个有效的解决办法,已成为一项具有实用价值的关键技术。 近年来, 多种统计理论和机器学习方法被用来进行文本的自动分类,掀起了文本自动分类的研究和应用的热潮。
常见的文本分类算法有Navie Bayes算法,K-近邻算法和支持向量机算法等。
2分类方法概述
2.1 Navie Bayes算法
Navie Bayes是一种以贝叶斯定理为理论基础的统计学的分类方法,是一种在已知先验概率和条件概率的情况下求后验概率的模式识别方法。Navie Bayes分类方法是一种简单有效的分类方法。
Navie Bayes分类方法的基本思想是:在已知先验概率和条件概率的情况下,计算待分类文本属于各个类别的后验概率,然后将待分类文本分到后验概率最大的类别中。其中文本属于某个类别的概率为文本中各个特征词属于该类别概率的综合表达式。
Navie Bayes的一个前提假设是:文本的特征词之间是相互独立的,即文本的一个特征词对分类的影响独立于其他特征词对分类的影响。
朴素贝叶斯分类的正式定义如下:

由于Navie Bayes分类方法是在特征独立性假设的前提下进行文本分类操作的,该假设会影响Navie Bayes的分类结果。本人在weka上使用Navie Bayes分类算法进行文本分类,其准确率只有70%左右,召回率在65%左右,效果很不理想。当然,这和我在前期的数据预处理的阶段采用的方法有一定的关系。但是这和后期采取的支持向量机方法的效果比较起来,差距还是很大的。
2.2 K-近邻算法
K-近邻 (K Neareat Neighbors,简称KNN)分类算法是一种传统的基于统计的分类方法。KNN分类算法的基本思想为:在训练样本集中找到与待分类文本最近的K个文本,看这K个近邻文本中多数属于哪一类。就把待分类文本分到哪一类。其分类的基本步骤如下:
1、根据特征项集合扫描训练文本向量:
2、对待分类文本进行向量表示:
3、在训练文本集合中找到与待分类文本最近的K个近邻,近邻的判别标准一般采用文档向量余弦相似度方法来计算。K值的确定目前还没有好的方法,一般是先设定一个初始值,然后根据实验具体情况再对K值进行调整。
4、依次计算待分类文本的K的近邻文本相对于各个类的权重,计算方法如下: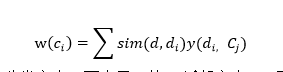
其中,d表示待分类文本。西表示d的K近邻文本,y(西。o)为文档类别判定函数,如果文档西属于类别O则y(西。O)取值为1,否则为0。Sim(d,西)为待分类文本与K近邻文本的相似度,一般采用文档向量余弦相似度计算方法.
5、据各个类的权重计算结果,将待分类文本划分到权重最大的类别中。
KNN分类方法具有分类方法简单、易于实现、分类出错率低的优点。但是由于需要较大的空间来存储训练样本集,而且对于每个待分类的文本。都要计算其与训练样本集中各个文本的相似度,分类开销较大,因此该分类方法并不适用于大规模的数据集,相反在小规模数据集上该分类方法能够取得较好的分类效果。
2.3支持向量机算法
支持向量机(Support Vector Machines,SVM)最早是由Vapnik在1995年提出,并在20世纪90年代中后期得以发展和完善。支持向量机主要是根据统计学理论解决二分类模式识别问题。Joachims最早将SVM方法应用于文本分类。在文本分类问题中,SVM将分类问题转化为一系列二分问题。
支持向量机的基本实现思想是:通过某种事先选择的非线性影射把输入向量x映射到一个高维特征空间Z,在这个空间中构造最优分类超平面。也就是SVM采用输入向量的非线性变换,在特征空间中,在现行决策规则集合上按照正规超平面权值的模构造一个结构,然后选择结构中最好的元素和这个元素中最好的函数,以达到最小化错误率的目标,实现了结构风险最小化原则。支持向量机最初是为了解决两类分类问题的,其基本思路如下:
用(,)表示线性可分样本集,其中∈,为类别标识,∈{+1,-1},为d维欧式空间。用方程g(x)=wx+b表示n维空间线性判别函数,wx+b=0表示分类平面,经过对判别函数进行归一化处理,使得两类中的所有样本满足条件|g(x)|>=1,则两个类别之间的间隔为2/|w|。这样为了满足类别边界沿垂直于超平面方向距离最大的条件,只需要使|w|取值最小即可。为了使分类超平面能够对所有样本正确分类,只需满足条件:
[(w)+b]-1>=0,i=1,2,……,n
|w|取值最小且满足上述条件的分类面就是所要求的最优分类面H。
相对于其他分类器,支持向量机在文本分类方面的优势主要体现在:
1、 支持向量机基于维理论和结构风险最小化原则,能通过输入空间的运算有效地解决文本数据的高维、稀疏问题;
2、 支持向量机对应于二次规划问题,避免了神经网络分类器无法克服的局部最优值问题;
3、 文本向量特征之间有明显的相关性,而诸如朴素贝叶斯等建立在特征独立性假设基础上的算法受该特性影响较大,而支持向量机则对此不敏感;
4、 支持向量机针对有限样本情况得到最优解,并可有力地支持增量学习和主动学习模式,解决文本分类样本收集困难、内容更新快等问题,更符合生产实际。
其不足之处在于:以根据实际问题选择合适的函数、参数调节比较困难、分类比较耗时。在需要指出的是,在本人的实际操作过程中发现,虽然支持向量机算法开销较大,但其只需要相对较小的训练集可以产生准确率和召回率都比较高的分类模型。
3实验过程及结果分析
3.1数据来源
1. 分类语料来自搜狗实验室,包含训练集和测试集两个目录。
(1)训练集
Training Dataset目录下的9个子目录,每个子目录对应一个类别,共包含9个类别的数据,每个类别包含1989篇文本。
类别代号与相应的类别对应关系如下:
C000008 财经
C000010 IT
C000013 健康
C000014 体育
C000016 旅游
C000020 教育
C000022 招聘
C000023 文化
C000024 军事
(2)测试集
Test Dataset目录下的9个待分类的文本。
3.2实验过程
(一)权重计算—TF-IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
(二)特征提取--Chi-square
X2统计衡量的是一个特征t与一个类C之间的相关程度。如果t与 C之间相互独立 ,那么文本特征t的X2统计值为零。对于类别C,文本特征 t的X2统计定义如下:
之所以可以简化,是因为在这里并不关心其具体值的多少,只是关心其值之间的大小关系。
本次实验共选取了55000个特征词。
(三)分类模型训练—支持向量机
本次实验调用THUCTC(THU Chinese Text Classification)工具。THUCTC(THUChinese Text Classification)是由清华大学自然语言处理实验室推出的中文文本分类工具包,能够自动高效地实现用户自定义的文本分类语料的训练、评测、分类功能。
基本参数如下图:

3.3实验结果
各类的训练结果如下:
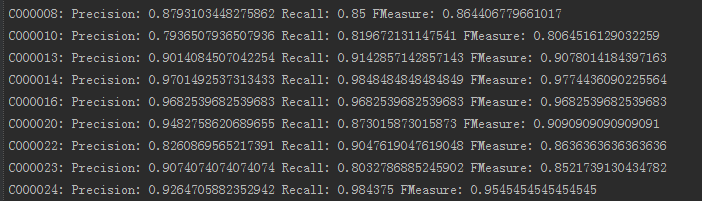
可以看出,在各类别上分类效果都比较好。整体效果如下:

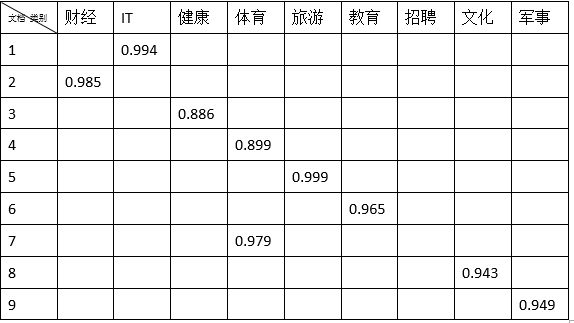
将第一个测试文档输入模型中,并输出三个最可能的类别,结果如下:

显然,该文档最可能属于C000010类,即IT类。对所有的9篇测试文档做相同的处理,将结果整理成表格如下:
4结论与展望
本实验中的测试集只有9个文档,准确率和召回率均为100%。但是测试文档过少,这两项数值也没什么意义了。此外,经测试发现,该方法对短文本分类的支持效果要远远劣于长文本。
参考文献
[1] 刘向东,陈兆乾.一种快速支持向量机分类算法的研究[J].计算机研究与发展.2004,41(8):1327—1331
[2] 都云琪,肖诗斌.基于支持向量机的中文文本自动分类研究I-J].计算机工程,2002,28(11):137—139.
[3] THUCTC: 一个高效的中文文本分类工具包 http://thuctc.thunlp.org/
[4] Jingyang Li, Maosong Sun. Scalable Term Selection forText Categorization. Proc. of the 2007 Joint Conference on Empirical Methods inNatural Language Processing and Computational Natural Language Learning(EMNLP-CoNLL), Prague, Czech Republic, 2007, pp. 774-782.