神经网络在Keras中不work!博士小哥证明何恺明的初始化方法堪比“CNN还魂丹”...
铜灵 发自 凹非寺
量子位 出品 | 公众号 QbitAI
南巴黎电信学院(Télécom SudParis)的在读博士生Nathan Hubens在训练CNN时遇到点难题。
使用在CIFAR10数据集上训练的VGG16模型进行实验的过程中,进行了50次迭代,最后发现模型没有学到任何东西。

可以看出,模型的收敛速度极慢,振荡,过拟合,为什么会这样?
你是不是也有这样的疑惑?
小哥哥这篇分享得到了网友的感谢,启发了不少研究者。量子位整理重点如下:
实验本身
先看一下创建模型的过程:
def ConvBlock(n_conv, n_out, shape, x, is_last=False): for i in range(n_conv): x = Conv2D(n_out, shape, padding='same', activation='relu')(x) if is_last: out = layers.GlobalAveragePooling2D()(x) else: out = MaxPooling2D()(x) return outinput = Input(shape=(32, 32, 3))x = ConvBlock(2, 64, (3,3), input)x = ConvBlock(2, 128, (3,3), x)x = ConvBlock(3, 256, (3,3), x)x = ConvBlock(3, 512, (3,3), x)x = ConvBlock(3, 512, (3,3), x, is_last=True)x = layers.Dense(num_classes, activation='softmax')(x)
for i in range(n_conv):
x = Conv2D(n_out, shape, padding='same', activation='relu')(x)
if is_last: out = layers.GlobalAveragePooling2D()(x)
else: out = MaxPooling2D()(x)
return out
input = Input(shape=(32, 32, 3))
x = ConvBlock(2, 64, (3,3), input)
x = ConvBlock(2, 128, (3,3), x)
x = ConvBlock(3, 256, (3,3), x)
x = ConvBlock(3, 512, (3,3), x)
x = ConvBlock(3, 512, (3,3), x, is_last=True)
x = layers.Dense(num_classes, activation='softmax')(x)
这个模型遵循原始的VGG 16架构,但是大多数全连接层都被移除,因此几乎只剩下卷积层了。
开头的“车祸现场”,可能会受到几个操作步骤的影响。
当模型的学习环节出现问题时,研究人员通常会去检查梯度表现,得到网络每一层的平均值和标准差:
def get_weight_grad(model, data, labels): means = [] stds = [] grads = model.optimizer.get_gradients(model.total_loss, model.trainable_weights) symb_inputs = (model._feed_inputs + model._feed_targets + model._feed_sample_weights) f = K.function(symb_inputs, grads) x, y, sample_weight = model._standardize_user_data(data, labels) output_grad = f(x + y + sample_weight) for layer in range(len(model.layers)): if model.layers[layer].__class__.__name__ == 'Conv2D': means.append(output_grad[layer].mean()) stds.append(output_grad[layer].std()) return means, stds
means = []
stds = []
grads = model.optimizer.get_gradients(model.total_loss, model.trainable_weights)
symb_inputs = (model._feed_inputs + model._feed_targets + model._feed_sample_weights)
f = K.function(symb_inputs, grads)
x, y, sample_weight = model._standardize_user_data(data, labels)
output_grad = f(x + y + sample_weight)
for layer in range(len(model.layers)):
if model.layers[layer].__class__.__name__ == 'Conv2D':
means.append(output_grad[layer].mean())
stds.append(output_grad[layer].std())
return means, stds
看一下最后统计出来的结果:

结果有点出乎意料,也就是说在这个模型中,几乎没有任何梯度。作者表示,或许应该检查激活操作是如何沿着每一层进行的。
通过下面的代码再次得到它们的平均值和标准差:
def get_stats(model, data): means = [] stds = [] for layer in range(len(model.layers)): if model.layers[layer].__class__.__name__ == 'Conv2D': m = Model(model.input, model.layers[layer].output) pred = m.predict(data) means.append(pred.mean()) stds.append(pred.std()) return means, stds
means = []
stds = []
for layer in range(len(model.layers)):
if model.layers[layer].__class__.__name__ == 'Conv2D':
m = Model(model.input, model.layers[layer].output)
pred = m.predict(data)
means.append(pred.mean())
stds.append(pred.std())
return means, stds
结果和之前不一样了:

这不就朝着正轨又迈进一步了。
这一步中,每个卷积层的梯度计算方式如下:

其中Δx和Δy分别表示∂L/∂x和∂L/∂y,这里用反向传播算法和链式法则计算梯度,也就是说,需要从最后一层开始,向后传播到到前面的层中。
如果最后一层激活函数的值接近于0时,梯度在任何地方都趋近于0,因此无法反向传播,网络也无法学习任何东西。
作者认为,因为自己的网络没有批归一化,没有Dropout,也没有数据扩充,所以猜测问题主要出在初始化这一步上。
他读了何恺明此前的论文Delving Deep into Rectifiers: Surpassing Human-Level Performance on ImageNet Classification,想看看能不能解开自己的疑惑。

论文地址:
https://arxiv.org/pdf/1502.01852.pdf
初始化方法
初始化一直是深度学习研究中的重要领域,特别是随着架构和非线性研究的不断发展,一个好的初始化方法可能决定着网络最终的质量。
何恺明的论文中显示了初始化应具备的条件,也就是如何用ReLU激活函数正确将卷积网络初始化。这需要一点点数学基础,但也不难。
先考虑卷积层l的输出方式:

如何将偏差初始化为0,并假设权重w和元素x两者独立并且共享相同的分布,则:

其中n为k的平方乘c,通过独立变量乘积方差公式:

将上述公式变换为:
![]()
如果让权重w使它们的均值变成0,则输出:

利用König-Huygens特性:

最终输出:

因为用的时ReLU激活函数:

因此得到:

上述公式为单个卷积层输出的方差,若考虑网络中的所有层,需要得到它们的乘积:

有了乘积后可以看出,如果每层的方差不接近1,网络就会快速衰减。若小于1,则会朝0消散;若大于1,则激活值将无限增长。
若想拥有良好的ReLU卷积网络,需要遵循以下条件:

作者将标准初始化和使用自己的初始化方法的情况进行对比:

结果发现,使用Xavier/Glorot初始化训练的网络没有学习到任何东西。
在默认情况下,在Keras中,卷积层按Glorot正态分布进行初始化:
keras.layers.Conv2D(filters, kernel_size, strides=(1, 1), padding='valid', data_format=None, dilation_rate=(1, 1), activation=None, use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros', kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None, bias_constraint=None)1), padding='valid',
data_format=None, dilation_rate=(1, 1), activation=None,
use_bias=True, kernel_initializer='glorot_uniform', bias_initializer='zeros',
kernel_regularizer=None, bias_regularizer=None, activity_regularizer=None, kernel_constraint=None,
bias_constraint=None)
如果将这种初始化方法替换成何恺明的方法,会发生什么?
何恺明的初始化方法
先重建VGG 16模型,将初始化改成he_uniform,在训练模型前检查激活和梯度。

通过这种初始化法,激活平均值为0.5,标准偏差为0.8。

有一些梯度出来了,也就是说明网络开始work了。按此方法训练新模型,得到了如下曲线:
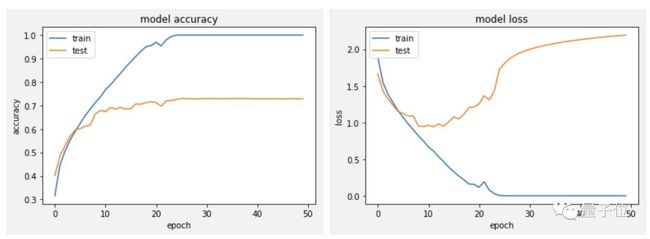
现在还需要考虑下正则化的问题,但总体来说,结果已经比之前好很多了。
结论
在这篇文章中,作者证明了初始化是模型构建中的重要一部分,但在平时的训练过程中往往会被习惯性忽略。
此外还需要注意的是,即使是人气口碑机器学习库Keras,其中的默认设置也不能不加调试就拿来用。
传送门
最后,附上文章原文地址:
https://towardsdatascience.com/why-default-cnn-are-broken-in-keras-and-how-to-fix-them-ce295e5e5f2
— 完 —
AI社群 | 与优秀的人交流

小程序 | 全类别AI学习教程


量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
喜欢就点「在看」吧 !