基于TensorFlow.NET的神经网络
在本文中,我们将学习如何在C#中构建神经网络模型图。与线性分类器相比,神经网络的关键优势在于它可以分类非不可线性分布的数据。我们将实现此模型来对来自于MNIST的手写数字图像数据集的进行分类。
我们要构建的神经网络的结构如下。 MNIST数据的手写数字图像有10个类(从0到9)。该网络具有2个隐藏层:第一层具有200个隐藏单元(神经元),第二层具有10个神经元(称为分类器层)。
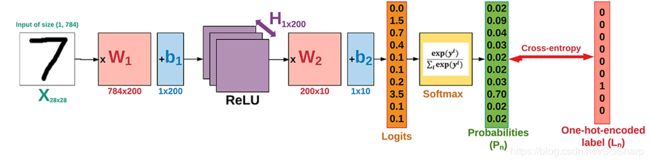
让我们一步一步地开始实施:
1.准备数据
MNIST是手写数字的数据集,包含55,000个用于训练的示例,5,000个用于验证的示例和10,000个用于测试的示例。这些数字已经过标准化,并且以固定尺寸的图像(28 x 28像素)为中心,其值为0和1.每个图像已被展平并转换为784个特征的1-D阵列。它也是深度学习数据集的基准。

我们定义一些变量使以后更容易修改它们。值得注意的是,在线性模型中,我们必须将输入图像展平为矢量。
using System;
using NumSharp;
using Tensorflow;
using TensorFlowNET.Examples.Utility;
using static Tensorflow.Python;
const int img_h = 28;
const int img_w = 28;
int img_size_flat = img_h * img_w; // 784, the total number of pixels
int n_classes = 10; // Number of classes, one class per digit
我们将编写自动加载MNIST数据的函数,并以我们想要的形状和格式返回它。有一个MNIST数据助手可以让操作更轻松。
数据集mnist;
public void PrepareData()
{
mnist = MnistDataSet.read_data_sets(“mnist”,one_hot:true);
}
除了加载图像和相应标签的功能外,我们还需要两个功能:
randomize:随机化图像及其标签的顺序。在每个epoch的开始,我们将重新随机化数据样本的顺序,以确保训练的模型对数据的顺序不敏感。
private(NDArray,NDArray)随机化(NDArray x,NDArray y)
{
var perm = np.random.permutation(y.shape [0]);
np.random.shuffle(烫发);
return(mnist.train.images [perm],mnist.train.labels [perm]);
}
get_next_batch:仅选择由batch_size变量确定的少量图像(根据Stochastic Gradient Descent方法)。
private(NDArray,NDArray)get_next_batch(NDArray x,NDArray y,int start,int end)
{
var x_batch = x [ “ s t a r t : e n d ” ] ; v a r y b a t c h = y [ “{start}:{end}”]; var y_batch = y [ “start:end”];varybatch=y[“{start}:{end}”];
return(x_batch,y_batch);
}
2.设置Hyperparameters
在训练集中有大约55,000个图像,使用所有图像计算模型的梯度需要很长时间。因此,我们通过随机梯度下降在优化器的每次迭代中使用一小批图像。
int epochs = 10;
int batch_size = 100;//批量大小
float learning_rate = 0.001f;
int h1 = 200; //第一个隐藏层中的节点数
3.构建神经网络
让我们做一些函数来帮助构建计算图。
变量:我们需要定义两个变量W和b来构造我们的线性模型。我们使用适当大小和初始化的Tensorflow变量来定义它们。
// weight_variable
var in_dim = x.shape[1];
var initer = tf.truncated_normal_initializer(stddev: 0.01f);
var W = tf.get_variable("W_" + name,
dtype: tf.float32,
shape: (in_dim, num_units),
initializer: initer);
// bias_variable
var initial = tf.constant(0f, num_units);
var b = tf.get_variable("b_" + name,
dtype: tf.float32,
initializer: initial);
完全连接层:神经网络由完全连接(密集)层的堆栈组成。具有权重(W)和偏差(b)变量,完全连接的层被定义为激活(W x X + b)。完整的fc_layer函数如下:
private Tensor fc_layer(Tensor x, int num_units, string name, bool use_relu = true)
{
var in_dim = x.shape[1];
var initer = tf.truncated_normal_initializer(stddev: 0.01f);
var W = tf.get_variable("W_" + name,
dtype: tf.float32,
shape: (in_dim, num_units),
initializer: initer);
var initial = tf.constant(0f, num_units);
var b = tf.get_variable("b_" + name,
dtype: tf.float32,
initializer: initial);
var layer = tf.matmul(x, W) + b;
if (use_relu)
layer = tf.nn.relu(layer);
return layer;
}
}
输入:现在我们需要定义适当的张量来输入我们的模型。占位符变量是输入图像和相应标签的合适选择。这允许我们将输入(图像和标签)更改为TensorFlow图。
// Placeholders for inputs (x) and outputs(y)
x = tf.placeholder(tf.float32, shape: (-1, img_size_flat), name: "X");
y = tf.placeholder(tf.float32, shape: (-1, n_classes), name: "Y");
占位符x是为图像定义的,形状设置为[None,img_size_flat],其中None表示张量可以保持任意数量的图像,每个图像是长度为img_size_flat的向量。
占位符y是与占位符变量x中输入的图像关联的真实标签的变量。它包含任意数量的标签,每个标签是长度为num_classes的向量,为10。
网络层:在创建适当的输入后,我们必须将它传递给我们的模型。由于我们有神经网络,我们可以使用fc_layer方法堆叠多个完全连接的层。请注意,我们不会在最后一层使用任何激活函数(use_relu = false)。原因是我们可以使用tf.nn.softmax_cross_entropy_with_logits来计算损失。
// Create a fully-connected layer with h1 nodes as hidden layer
var fc1 = fc_layer(x, h1, "FC1", use_relu: true);
// Create a fully-connected layer with n_classes nodes as output layer
var output_logits = fc_layer(fc1, n_classes, "OUT", use_relu: false);
//
损失函数:创建网络后,我们必须计算损失并对其进行优化,我们必须计算正确的预测和准确性。
// Define the loss function, optimizer, and accuracy
var logits = tf.nn.softmax_cross_entropy_with_logits(labels: y, logits: output_logits);
loss = tf.reduce_mean(logits, name: "loss");
optimizer = tf.train.AdamOptimizer(learning_rate: learning_rate, name: "Adam-op").minimize(loss);
var correct_prediction = tf.equal(tf.argmax(output_logits, 1), tf.argmax(y, 1), name: "correct_pred");
accuracy = tf.reduce_mean(tf.cast(correct_prediction, tf.float32), name: "accuracy");
完整的计算图如下所示:
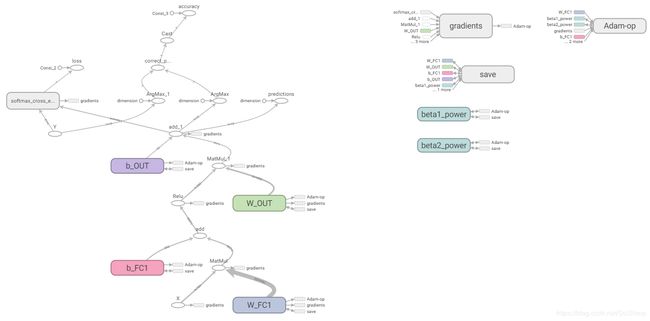
4. 训练
创建图表后,我们可以训练我们的模型。为了训练模型,我们必须创建一个会话并在会话中运行图形。
// Number of training iterations in each epoch
var num_tr_iter = mnist.train.labels.len / batch_size;
with(tf.Session(), sess =>
{
sess.run(init);
float loss_val = 100.0f;
float accuracy_val = 0f;
foreach (var epoch in range(epochs))
{
print($"Training epoch: {epoch + 1}");
// Randomly shuffle the training data at the beginning of each epoch
var (x_train, y_train) = randomize(mnist.train.images, mnist.train.labels);
foreach (var iteration in range(num_tr_iter))
{
var start = iteration * batch_size;
var end = (iteration + 1) * batch_size;
var (x_batch, y_batch) = get_next_batch(x_train, y_train, start, end);
// Run optimization op (backprop)
sess.run(optimizer, new FeedItem(x, x_batch), new FeedItem(y, y_batch));
if (iteration % display_freq == 0)
{
// Calculate and display the batch loss and accuracy
var result = sess.run(new[] { loss, accuracy }, new FeedItem(x, x_batch), new FeedItem(y, y_batch));
loss_val = result[0];
accuracy_val = result[1];
print($"iter {iteration.ToString("000")}: Loss={loss_val.ToString("0.0000")}, Training Accuracy={accuracy_val.ToString("P")}");
}
}
// Run validation after every epoch
var results1 = sess.run(new[] { loss, accuracy }, new FeedItem(x, mnist.validation.images), new FeedItem(y, mnist.validation.labels));
loss_val = results1[0];
accuracy_val = results1[1];
print("---------------------------------------------------------");
print($"Epoch: {epoch + 1}, validation loss: {loss_val.ToString("0.0000")}, validation accuracy: {accuracy_val.ToString("P")}");
print("---------------------------------------------------------");
}
});
5.测试
培训完成后,我们必须测试我们的模型,看看它在新数据集上的表现如何。
var result = sess.run(new[] { loss, accuracy }, new FeedItem(x, mnist.test.images), new FeedItem(y, mnist.test.labels));
loss_test = result[0];
accuracy_test = result[1];
print("---------------------------------------------------------");
print($"Test loss: {loss_test.ToString("0.0000")}, test accuracy: {accuracy_test.ToString("P")}");
print("---------------------------------------------------------");
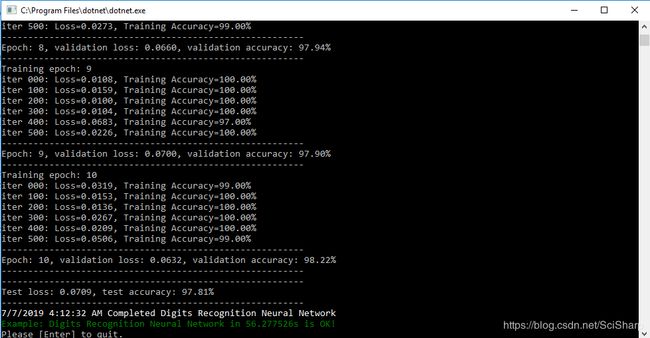
6.绘图
TO DO…
源代码在Github上提供。