【Python】利用Python爬虫实现网页图片批量下载

本文爬取的是豆瓣的网站,爬虫有规则,爬虫需谨慎。文章末附效果图
源码下载地址:https://github.com/Seichung/Python/blob/master/Python_Practical/download_allpic.py
# Author Scon
# -*- coding:utf-8 -*-
# help()
# 导入所需模块
import requests
import re
import os
# 根据给出的url进行爬虫
def get_web(url, fname):
r = requests.get(url) # 返回url请求的数据
data = r.content
with open(fname, 'wb') as fobj: # 将数据存储在指定位置
fobj.write(data)
return fname
# 调用 get_web 获得图片的url
def get_picurl(fname):
patt = r'https://[.\w/-]+\.(jpg|jpeg|png|gif)' # 利用正则匹配出图片url
repatt = re.compile(patt)
resutle = [] # 定义空列表存储图片url
with open(fname) as fobj: # 打开爬取的数据
for line in fobj: # 循环读取爬取的数据
data = repatt.search(line) # 进行正则
if data:
resutle.append(data.group())
return resutle
def download_pic(url):
pic_dir = '/mnt/pic_dir' # 创建存储图片的文件夹
if not os.path.exists(pic_dir):
os.mkdir(pic_dir)
for pic_url in url: # 循环读取读取出来的图片url
pic_name = os.path.join(pic_dir, pic_url.split('/')[-1])
try:
get_web(pic_url, pic_name) # 将图片url跟文件回传给get_web执行批量下载
except:
pass
if __name__ == '__main__':
url = 'https://www.douban.com'
fname = '/mnt/douban.html'
get_web(url, fname)
picurl = get_picurl(fname)
download_pic(picurl)
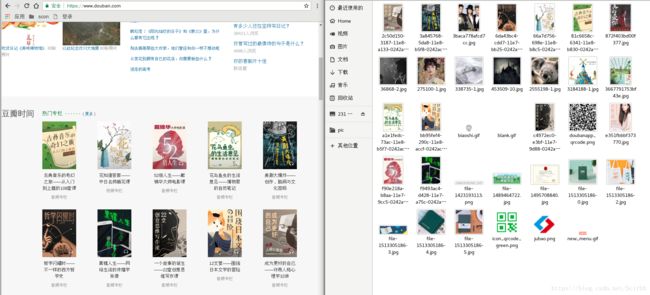
本文旨在提供参考,如有错误,欢迎大家指正。帮助编者不断的改进!