论文浅尝 | 基于文本关联的知识图谱的无监督嵌入增强

来源:IJCAI2019
论文链接: https://www.ijcai.org/proceedings/2019/0725.pdf
概述
知识图谱嵌入是从多关系数据中提取数据的工具,最近的嵌入模型对从现有数据库中推断新事实具有很高的效率。然而,这种精确结构的数据通常在数量和范围上都是有限的。因此,要充分优化嵌入,还必须考虑更广泛可用的信息源(如文本)。本文描述了一种通过增加实体嵌入和关联词嵌入来整合文本信息的无监督方法。该方法不修改知识图谱嵌入的优化目标,这允许它与已有的嵌入模型集成。同时考虑了两种不同形式的文本数据,并针对每种情况提出了不同的嵌入增强。在第一种情况下,每个实体都有一个描述它的关联文本文档。在第二种情况下,文本文档不可用,相反,实体以单词或短语的形式出现在非结构化的文本片段语料库中。实验表明,这两种方法在应用于多种不同的知识图嵌入模型时,都能有效地提高连接预测的性能。
模型和方法
嵌入增强方法
在本节中,作者将讨论将文本数据合并到知识图谱嵌入中的新方法。此附加信息允许培训过程学习同时从知识库和相关文本中反映事实的实体表示。根据可用文本数据的形式,我们考虑两种不同的场景:在第一种场景中,每个实体都有一个与之相关的文档来描述或定义实体;例如,欧洲的维基百科条目。这些数据可以从许多来源获得,包括百科全书或字典。在第二个场景中,我们考虑一个非结构化的语料库,它不直接链接到任何实体,但包含在任意位置的实体。例如,一篇提到欧洲的新闻文章可能是这个语料库的一部分。对本文的组织结构没有任何假设,因此它通常可以是从多个文档中收集的句子的集合。这两种形式的数据之间的关键区别在于,在前者中,实体是文档中所有单词的基础主题,而在后者中,实体只是包含未知主题的混合文档中提到的对象。结果,第一种情况包含每个单词以某种方式与已知实体相关的附加信息。对于第二种情况,我们只假设在相同上下文中出现的单词之间存在关联。这一区别如图1所示。
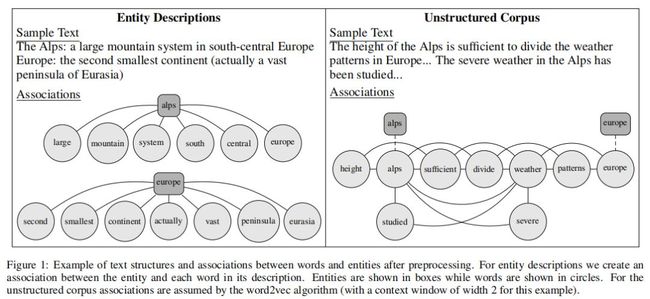
1.1 实体描述的嵌入模型
在本节中,我们为图1中的第一个场景提供了一个模型,其中文本数据可用作实体描述。我们的方法基于[Socher等人,2013]的字向量模型,该模型将实体向量定义为实体名称中字向量的平均值。首先,我们观察到,该思想也可以应用于实体描述,从而强制实体嵌入共享共同的文本特征,如属性或关系词。这将为语义上更相似的实体生成更相似的向量。然后,我们通过添加新参数来控制每个单词对给定关系的实体组成的贡献程度,从而改进了该模型。
我们首先对WordVectors模型进行形式化,我们已经对其进行了调整,以适应实体描述的情况。设文本(ei)=wi,1,wi,2。. . 是与实体ei相关联的单词序列。设W表示词向量的nw×d矩阵,其中nw是词汇表中的词个数,d是嵌入维数。让Ai表示nw维向量,使得Aik是单词wk在文本中出现的次数(ei)。然后,ei的嵌入向量可以表示为
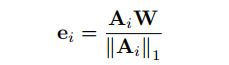
上述等式的一个限制是描述中的所有单词都被同等对待;通常情况下,某些单词比其他单词更适合预测关系。例如,乐器、鼓和职业等词可能比其他词(如女演员或星期六)更能反映音乐团体成员关系。因此,在预测音乐群体成员关系时,应以乐器、鼓、职业等词来表示一个实体。
另一方面,在预测教育等不同关系时,加拿大人、课程或常春藤等词可能更具相关性,因此实体应该更强烈地用这些词来表示。这样,包含“常春藤”一词的实体向量在教育关系上比在音乐团体成员中更为相似。因此,这种模型可以预测两个实体共享前一种关系,而不是后一种关系。
这种行为可以通过引入nr×nw矩阵B来实现,使得Bjk表示单词wk在预测关系rj中的重要性。然后我们可以定义实体ei在关系rj下的表示为
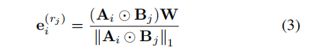
这里⊙表示元素相乘。这样,单词wk对实体向量的总权重是文本中wk的频率(e i)(即Aik)和wk与ri的相关性(即Bjk)的组合。
然而,每个词对于预测每一种关系的意义通常是未知的。因此,我们用B i j=1对所有i,j初始化B,并通过梯度下降来学习这些参数。如第4节所示,该程序能够自动学习单词与不同关系的关联,而无需任何监督。
我们可以用公式3代替表1中的ei,将文本信息合并到任何知识图嵌入模型中。例如,扩展的TranSE模型是
![]()
我们称这种方法为加权词向量(WWV)。
1.2 一种参数有效加权方案
如前一节所述,WWV模型的一个潜在缺点是矩阵B中的参数数目为nr×nw,这对于某些数据集来说可能是非常大的。这可以通过允许Bij从较少数量的参数派生而不是将每个参数定义为独立的参数来改进。为此,我们引入nr×d矩阵P,并定义关系ri和单词wj的权重如下:
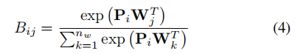
公式4中Pi是单词特征空间中关系ri的表示,与单词向量Wj的特征空间相同。由于Pi和Wj使用相同的特征,PiWTj是ri和Wj之间相似性的度量,它充当它们之间的权重。例如,我们可能期望关系ri=音乐组成员的向量Pi与关系Wj=乐器的向量Wj相似,因为音乐组和乐器的概念在语义上是相关的。
虽然使用softmax函数定义权重Bij在概念上很有吸引力,但实际上不需要标准化因子,因为在等式3中所有权重都再次标准化。因此,我们可以将关系rj下的实体ei表示为:
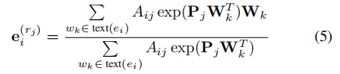
这里我们用展开形式表示了等式3的向量矩阵乘法,以便更清楚地显示单词的加权平均值。因此,可训练参数的数目从nr×nw减少到nr×d。我们将等式5中的模型称为参数有效加权词向量(PE-WWV)。尽管参数较少,但第4节证明了PE-WWV在预测精度上与WWV相当。
1.3训练过程
在训练WWV和PE-WWV模型时,由于单词嵌入参数W和权重B都必须在没有监督的情况下同时学习,因此产生了一个挑战。也就是说,优化器必须为每个关系发现最重要的词,而不必对这些关系或词进行任何理解或描述。由于初始随机性,优化器在训练的早期阶段可能会过分强调不相关的词,然后永远找不到好的解决方案。
我们发现,在前50个训练阶段保持单词权重(B和P)不变,可以大大缓解这个问题。这允许优化器首先学习语义上有意义的单词表示,而不会因为单词权重的变化而中断。然后,在剩余的训练阶段,我们优化所有参数,并能够发现最相关的单词。
1.4非结构化语料库的嵌入模型
在本节中,我们考虑图1中的第二个场景。为了从非结构化数据中获取信息,我们在给定的语料库上训练word2vec模型[Mikolov等人,2013],以学习单词的嵌入向量。Word2vec被训练为将相似的向量分配给通常出现在相同上下文中的单词,这使得它非常适合学习实体向量。例如,句子片段布赖恩琼斯和他的吉他手基思理查兹开发了一个独特的。。。很清楚地说明了布赖恩·琼斯和基思·理查兹之间的关系。由于Brian Jones和Keith Richards在同一个上下文中以单词的形式出现,因此这些实体的word2vec向量将更类似于非结构化语料库的嵌入模型。
word2vec向量还可以捕获显示为属性而不是句子对象的特征。在上面的例子中,这个句子还表示布赖恩·琼斯和吉它之间的关联。这对于预测布赖恩·琼斯的其他关系类型(如乐器演奏或音乐团体成员)可能是一个有力的暗示。当给出这个训练语句时,word2vec将学习在Brian Jones的向量中隐式地编码该信息。这使得通过使用word2vec特征向量来增加实体嵌入中的信息成为可能。
整个模型的工作原理如下。让wi表示实体ei的名称的word2vec向量,让ei表示实体向量。我们将实体ei的扩充向量定义为:
![]()
因此,ei中的每个潜在特征都包含原始实体向量和word2vec向量的贡献。和方程式一样。3和5,式6可应用于任何知识图嵌入模型,方法是将表1中的ei替换为ˆei。
由于word2vec在知识图嵌入过程中学习了一组不同的潜在特征,因此我们使用矩阵M将word2vec特征空间中的向量映射到实体特征空间。注意,与在SE、TRANSR和RESCAL模型(即R、R(1)和R(2))中操作实体的特定于关系的转换不同,M是所有关系类型通用的全局矩阵。因此,向量wM包含的特征有助于预测三元组,但可以从文本中学习。我们将公式6称为特征和模型。
特征和模型分三个阶段进行训练。首先,在语料库上训练word2vec获得wi向量,然后两个阶段对排序损失目标进行优化(方程1)。最初,M被设置为零并保持不变,而实体和关系参数E和R被优化为100个阶段。最后,包括M和wi在内的所有参数在剩余的训练期间一起训练。
实验
在本节中,我们评估了在Freebase[Bollacker等人,2008]和Wordnet[Miller,1995]的标准子集上提出的嵌入增强方法。我们将这些方法应用于表1中的每个评分函数,证明了它们增强现有嵌入模型的能力。我们首先将链路预测任务中的WWV和PE-WWV模型与包含实体描述的替代方法进行定量比较,然后定性地检查WWV模型,以更好地了解其性能。接下来,我们将FeatureSum模型与使用非结构化文本语料库的替代方法进行比较。
WWV和PE-WWV结果
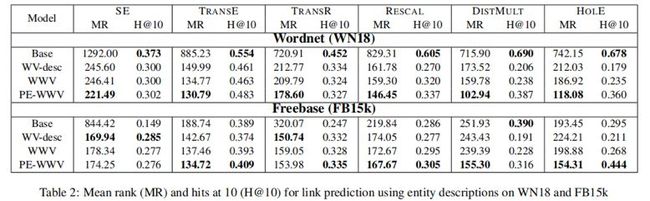
在本节中,我们将评估加权词向量模型的两个变体-WWV和PE-WWV。我们比较了合并格式化为实体描述的文本数据的替代方法,即WordVectors模型,但应用于实体描述而不是名称。我们把这个模型称为WV-desc,我们还考虑了基线方法,称为Base,其中实体向量简单地随机初始化和优化,没有附加文本。
表2给出了这两个数据集的平均rank和命中率@10指标。考虑到WWV是WV的泛化,可以通过简单地在公式2中为每个j,k设置Bjk=1来减少WWV的性能,我们期望WWV的性能应该比WV-desc好。事实上,WWV在大多数情况下的平均秩和命中率都优于WV-desc。
令人有些意外的是,PE-WWV模型的性能至少和WWV一样好,在许多情况下甚至更好。有人可能会认为PE-WWV的性能会更差,因为它的表示容量不大于WWV。通过设置Bjk=exp(PjWTk),可以使WWV等效于PE-WWV,这意味着它在理论上至少也可以执行。经过更深入的研究,我们发现PE-WWV倾向于学习比WWV相对更强的单词权重,这反过来又允许它在不同关系的实体表示之间创建更大的可变性。因此,WWV似乎受到优化算法的限制,而不是其理论性质。
与基线相比,平均排名在大多数情况下都有所提高,而hits@10则显示了Wordnet和Freebase之间的不同结果。对于Wordnet,与任何文本增强方法相比,基线在hits@10上的性能最好,这意味着此数据集中的文本可能并不十分指示关联的实体。不过,对于Freebase来说,这些描述提供了显著的好处,在大多数情况下,平均rank和命中率@10都提高了。
为了更好地理解这种行为,我们检查了Wordnet测试三元组,这些三元组在基线上的排名明显好于WWV-desc。我们观察到,在许多情况下,相关实体由完全不同的文本描述。例如,一个这样的三元组是(千字节,有部分,字),其中主题和对象的Wordnet定义是“单位信息等于字节”和“存储在计算机内存中的字字符串位大型计算机使用字位长”(省略了停止字)。
由于这些定义不包含常用词,因此在WVdesc模型中,它们可能看起来不相关。相比之下,维基百科上关于千字节和单词的摘要包含了诸如unit、digital和memory之类的常用关键字,这可能解释了为什么WV-desc在Freebase上表现得更好。
为了进一步验证这一假设,我们计算了每个三元组中主语和宾语描述之间的平均常用词数量。在Wordnet中,按基数排名的三元组平均包含0.67个常用词,而按WV desc排名的三元组平均包含0.89个常用词。相比之下,Freebase中的三元组平均包含20.0个常用单词。因此,与Wordnet相比,word vectors方法需要更详细的实体描述。
定性结果
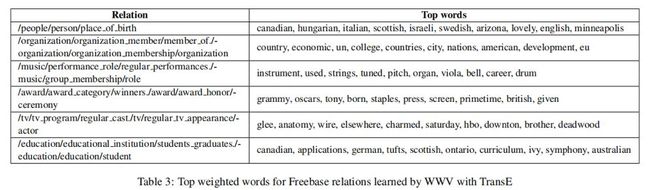
为了更好地理解WWV模型是如何工作的,我们在训练之后检查哪些单词被赋予了每个关系的最大权重。表3列出了使用TransE训练的Freebase中几个关系ri的前10个单词(从Bi中最强的权重中提取)。
我们观察到,许多热门词汇在语义上与关系相似。例如,出生地关系倾向于强调属于民族的词语,而作为音乐团体成员的关系则强调与乐器(如乐器、弦和鼓)有关的词语。这表明,模型的功能正如我们的直觉所暗示的那样,并用最能表明所讨论的关系的词语来表示实体。请注意,此表中单词和关系之间的关联是以完全无监督的方式学习的,只提供文本和训练三元组。
特征和结果
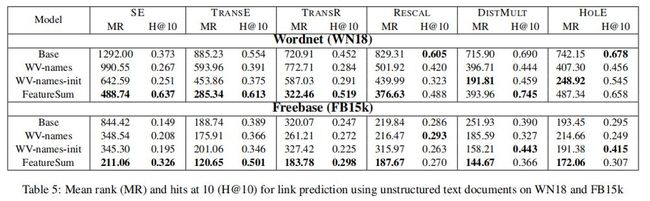
在本节中,我们将FeatureSum模型与其他方法进行比较,以合并来自非结构化文本语料库的信息。每个方法在定义实体向量的方式上都不同。WV name s模型应用了[Socher等人,2013年](等式2)的WordVectors技术,其中每个实体与其名称的组成词相关联。此模型也不使用任何补充文本数据,但可以在基线上进行改进。WV names init模型类似于WV names,但是每个wi都用word2vec vector初始化。该模型通过word2vec向量的训练合并了文本数据,因此是FeatureSum模型的一个关键参考点。
两个数据集的结果见表5。注意,这些结果不能直接与表2进行比较,因为这两组实验使用不同的文本数据。应该在同一个表中跨行进行比较。在这样做时,Wordnet上的平均秩通常表明,仅对实体名称应用WV已经给出了显著的改进,而使用word2vec向量初始化则进一步改进了结果,如[Socher等人,2013]所建议的。对于hits@10,结果是好坏参半的,WVnames方法在某些情况下显示出优势,而在其他情况下则显示出损失。
总结
本文讨论了两种利用文本数据信息扩充知识图中实体嵌入的新方法。第一种方法将实体向量表示为与每个实体相关联的词的直接函数,并且在以实体描述的形式提供文本数据时适用。第二种方法在文本文档上训练word2vec算法,并将它为实体名学习的特征添加到原始实体特征向量中。实验结果表明,如果文本数据具有足够高的质量,那么这两种方法与无文本的嵌入方法和可供选择的文本合并方法相比,可以提高许多不同嵌入模型的链接预测精度。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。