对偶性与KKT条件
在**上一篇文章中,笔者介绍了什么是拉格朗日乘数法以及它的作用。同时在那篇文章中笔者还特意说到,拉格朗日乘数法只能用来求解等式约束条件下**的极值。但是当约束条件为不等式的时候我们又该如何求解呢?
1 广义拉格朗日乘数法
由拉格朗日乘数法可知,对于如下等式条件的约束问题
min w f ( w ) s . t . h i ( w ) = 0 , i = 1 , ⋯ , l . (1) \begin{aligned} \min_{w} \;\;\;f(w)&\\ s.t. \;\;\;h_i(w)&=0,i=1, \cdots,l. \end{aligned}\tag 1 wminf(w)s.t.hi(w)=0,i=1,⋯,l.(1)
其中 w w w是一个向量。
很明显这是一个条件(等式)极值问题,且用拉格朗日乘数法就能解决:
L ( w , β ) = f ( w ) + ∑ i = 1 l β i h i ( w ) (2) \mathcal{L}(w,\beta) = f(w)+\sum^l_{i=1}\beta_ih_i(w)\tag 2 L(w,β)=f(w)+i=1∑lβihi(w)(2)
其中 β i \beta_i βi是拉格朗日乘子;然后对式子中所有的参数求偏导,令其为0便可求解出所有参数。
接着看如下优化问题
min w f ( w ) s . t . g i ( w ) ≤ 0 , i = 1 , ⋯ , k . h i ( w ) = 0 , i = 1 , ⋯ , l . (3) \begin{aligned} \min_{w} \;\;\;f(w)&\\ s.t. \;\;\;g_i(w)&\leq0,i=1, \cdots,k.\\[2ex] h_i(w)&=0,i=1, \cdots,l. \end{aligned}\tag 3 wminf(w)s.t.gi(w)hi(w)≤0,i=1,⋯,k.=0,i=1,⋯,l.(3)
与之前明显不同的就是在这个问题中多了不等式的约束条件。因此,为了解决这个问题我们就要定义广义的拉格朗日乘数法(Generalized Lagrangian)。
L ( w , α , β ) = f ( w ) + ∑ i = 1 k α i g i ( w ) + ∑ i = 1 l β i h i ( w ) (4) \mathcal{L}(w,\alpha,\beta) = f(w)+\sum^k_{i=1}\alpha_ig_i(w)+\sum^l_{i=1}\beta_ih_i(w)\tag 4 L(w,α,β)=f(w)+i=1∑kαigi(w)+i=1∑lβihi(w)(4)
其中 α i \alpha_i αi和 β i \beta_i βi都是拉格朗日乘子,但接下来的求解过程与之前就大相径庭了。
2 对偶问题优化
2.1 原始优化问题
根据式子 ( 3 ) ( 4 ) (3)(4) (3)(4)我们考虑如下定义:
θ P ( w ) = max α , β : α i ≥ 0 L ( w , α , β ) (5) \theta_{\mathcal{P}}(w)=\max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(w,\alpha,\beta)\tag 5 θP(w)=α,β:αi≥0maxL(w,α,β)(5)
这个式子表示的含义是:最大化 L ( ω , α , β ) \mathcal{L}(\omega,\alpha,\beta) L(ω,α,β)时 α , β \alpha,\beta α,β的取值,即 α , β \alpha,\beta α,β作为自变量与 w w w无关,最终求得的结果 θ P \theta_{\mathcal{P}} θP是关于 w w w的函数;其中 α i ≥ 0 \alpha_i\geq0 αi≥0是为了在 L ( w , α , β ) \mathcal{L}(w,\alpha,\beta) L(w,α,β)中保证约束条件 g i ( w ) ≤ 0 g_i(w)\leq 0 gi(w)≤0始终成立。
因此,如果原约束条件 g i ( w ) ≤ 0 g_i(w)\leq0 gi(w)≤0和 h i ( w ) = 0 h_i(w)=0 hi(w)=0均成立,那么:
max α , β : α i ≥ 0 L ( w , α , β ) ⟺ max α , β : α i ≥ 0 [ ∑ i = 1 k α i g i ( w ) + ∑ i = 1 l β i h i ( w ) ] (6) \max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(w,\alpha,\beta)\iff\max_{\alpha,\beta:\alpha_i\geq0}\left[\sum^k_{i=1}\alpha_ig_i(w)+\sum^l_{i=1}\beta_ih_i(w)\right]\tag 6 α,β:αi≥0maxL(w,α,β)⟺α,β:αi≥0max[i=1∑kαigi(w)+i=1∑lβihi(w)](6)
则此时有 θ P ( w ) = f ( w ) + 0 \theta_{\mathcal{P}}(w)=f(w)+0 θP(w)=f(w)+0。
同时,我们现在来做这样一个假设,如果存在 g i g_i gi或 h i h_i hi使得原约束条件不成立,即 g i ( ω ) > 0 g_i(\omega)>0\; gi(ω)>0或者 h i ( ω ) ≠ 0 \;h_i(\omega)\ne0 hi(ω)=0,那在这样的条件下 θ P \theta_\mathcal{P} θP会发生什么变化呢?如果 g i ( ω ) > 0 g_i(\omega)>0 gi(ω)>0,为了最大化 L \mathcal{L} L,只需要取 α i \alpha_i αi为无穷大,则此时 L \mathcal{L} L为无穷大,但没有意义;同样,如果 h i ( ω ) ≠ 0 h_i(\omega)\neq0 hi(ω)=0,取 β \beta β为无穷大( h i h_i hi与 β \beta β同号),则同样会无穷大。于是在这种情况下我们就能得到 θ P ( w ) = ∞ \theta_{\mathcal{P}}(w)=\infty θP(w)=∞。
进一步,结合上述两种情况我们就会得到下面这个式子:
θ P ( ω ) = { f ( w ) , if w satisfies primal constraints ∞ , otherwise (7) \theta_{\mathcal{P}}(\omega) = \begin{cases} f(w), & \text{if $w$ satisfies primal constraints} \\[2ex] \infty, & \text{otherwise} \end{cases}\tag 7 θP(ω)=⎩⎨⎧f(w),∞,if w satisfies primal constraintsotherwise(7)
再进一步,在满足约束条件的情况下最小化 θ P ( w ) \theta_{\mathcal{P}}(w) θP(w)就等同于最小化式子 ( 3 ) (3) (3)中的问题了。于是我们就能得到如下定义:
p ∗ = min w θ P ( w ) = min w max α , β : α i ≥ 0 L ( ω , α , β ) (8) p^*=\min_{w}\theta_{\mathcal{P}}(w)=\min_{w}\max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(\omega,\alpha,\beta)\tag 8 p∗=wminθP(w)=wminα,β:αi≥0maxL(ω,α,β)(8)
同时,我们将 ( 8 ) (8) (8)其称之为原始优化问题(primal optimization problem)。
2.2 对偶优化问题
接下来我们继续定义:
θ D ( α , β ) = min w L ( w , α , β ) (9) \theta_{\mathcal{D}}(\alpha,\beta)=\min_{w}\mathcal{L}(w,\alpha,\beta)\tag 9 θD(α,β)=wminL(w,α,β)(9)
这个式子表示的含义是:最小化 L ( ω , α , β ) \mathcal{L}(\omega,\alpha,\beta) L(ω,α,β)时 w w w的取值,即 w w w作为自变量(与 α , β \alpha,\beta α,β无关),最终求得的结果 θ D \theta_{\mathcal{D}} θD是关于 α , β \alpha,\beta α,β的函数。
此时,我们就能定义出原问题的对偶问题:
d ∗ = max α , β : α i ≥ 0 θ D ( α , β ) = max α , β : α i ≥ 0 min w L ( w , α , β ) (10) d^*=\max_{\alpha,\beta:\alpha_i\geq0}\theta_{\mathcal{D}}(\alpha,\beta)=\max_{\alpha,\beta:\alpha_i\geq0}\min_{w}\mathcal{L}(w,\alpha,\beta)\tag{10} d∗=α,β:αi≥0maxθD(α,β)=α,β:αi≥0maxwminL(w,α,β)(10)
并将其称之为对偶优化问题(dual optimization problem)。
那么原始问题和对偶问题有什么关系呢? 我们为什么又要用对偶问题?通常情况下两者满足以下关系:
d ∗ = max α , β : α i ≥ 0 min w L ( w , α , β ) ≤ min w max α , β : α i ≥ 0 L ( w , α , β ) = p ∗ (11) d^*=\max_{\alpha,\beta:\alpha_i\geq0}\min_{w}\mathcal{L}(w,\alpha,\beta)\leq\min_{w}\max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(w,\alpha,\beta)=p^*\tag {11} d∗=α,β:αi≥0maxwminL(w,α,β)≤wminα,β:αi≥0maxL(w,α,β)=p∗(11)
证明:
由式子 ( 5 ) ( 9 ) (5)(9) (5)(9)可知,对于任意的 w , α , β w,\alpha,\beta w,α,β有
θ D ( α , β ) = min w L ( w , α , β ) ≤ L ( w , α , β ) ≤ max α , β : α i ≥ 0 L ( w , α , β ) = θ P ( w ) (12) \theta_{\mathcal{D}}(\alpha,\beta)=\min_{w}\mathcal{L}(w,\alpha,\beta)\leq\mathcal{L}(w,\alpha,\beta)\leq\max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(w,\alpha,\beta)=\theta_{\mathcal{P}}(w)\tag{12} θD(α,β)=wminL(w,α,β)≤L(w,α,β)≤α,β:αi≥0maxL(w,α,β)=θP(w)(12)
由不等式的传递性可知:
θ D ( α , β ) ≤ θ P ( w ) (13) \theta_{\mathcal{D}}(\alpha,\beta)\leq\theta_{\mathcal{P}}(w)\tag{13} θD(α,β)≤θP(w)(13)
由于原始问题和对偶问题均有最优值,所以:
max α , β : α i ≥ 0 θ D ( α , β ) ≤ min w θ P ( w ) \max_{\alpha,\beta:\alpha_i\geq0}\theta_{\mathcal{D}}(\alpha,\beta)\leq\min_{w}\theta_{\mathcal{P}}(w) α,β:αi≥0maxθD(α,β)≤wminθP(w)
即有:
max α , β : α i ≥ 0 min w L ( w , α , β ) ≤ min w max α , β : α i ≥ 0 L ( w , α , β ) (14) \max_{\alpha,\beta:\alpha_i\geq0}\min_{w}\mathcal{L}(w,\alpha,\beta)\leq\min_{w}\max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(w,\alpha,\beta)\tag{14} α,β:αi≥0maxwminL(w,α,β)≤wminα,β:αi≥0maxL(w,α,β)(14)
而之所以要用对偶问题是因为直接对原始问题进行求解异常困难,所以一般将其转转换为对偶问题进行求解。但就目前来看,两者并不完全等同,其解也就必然不会相同。所以下面就要说到KKT条件了。
2.3 KKT条件
上面说到,要想用对偶问题的解来代替原始问题的解,就必须使得两者等价;对于原始问题和对偶问题,假设函数 f ( w ) f(w) f(w)和 h i ( w ) h_i(w) hi(w)是凸函数, h i ( w ) h_i(w) hi(w)是仿射函数,且不等式 g i ( w ) g_i(w) gi(w)严格可行(对于所有的 i i i都有 g i ( w ) < 0 g_i(w)<0 gi(w)<0),则 w ∗ w^* w∗和 α ∗ , β ∗ \alpha^*,\beta^* α∗,β∗同时是原始问题和对偶问题解的充分必要条件是 w ∗ , α ∗ , β ∗ w^*,\alpha^*,\beta^* w∗,α∗,β∗满足 Karush-Kuhn-Tucker(KKT) 条件:
∂ ∂ w i L ( w ∗ , α ∗ , β ∗ ) = 0 , i = 1 , ⋯ , n ∂ ∂ β i L ( w ∗ , α ∗ , β ∗ ) = 0 , i = 1 , ⋯ , l (15) \begin{aligned} \frac{\partial}{\partial w_i}\mathcal{L}(w^*,\alpha^*,\beta^*)=0,i&=1,\cdots,n\\[1ex] \frac{\partial}{\partial\beta_i}\mathcal{L}(w^*,\alpha^*,\beta^*)=0,i&=1,\cdots,l \end{aligned}\tag {15} ∂wi∂L(w∗,α∗,β∗)=0,i∂βi∂L(w∗,α∗,β∗)=0,i=1,⋯,n=1,⋯,l(15)
α i ∗ g i ( w ∗ ) = 0 , i = 1 , ⋯ , k (16) \alpha_i^*g_i(w^*)=0,i=1,\cdots,k\tag{16} αi∗gi(w∗)=0,i=1,⋯,k(16)
g i ( w ∗ ) ≤ 0 , i = 1 , ⋯ , k α i ∗ ≥ 0 , i = 1 , ⋯ , k (17) \begin{aligned} g_i(w^*)\leq0,i&=1,\cdots,k\\[1ex] \alpha_i^*\geq0,i&=1,\cdots,k \end{aligned}\tag{17} gi(w∗)≤0,iαi∗≥0,i=1,⋯,k=1,⋯,k(17)
其中式子 ( 16 ) (16) (16)称为KKT的对偶互补条件(dual complementarity condition)。由此可知,如果 α i ∗ > 0 \alpha^*_i>0 αi∗>0则有 g i ( w ) = 0 g_i(w)=0 gi(w)=0,而这一点也将用来说明SVM仅仅只有特别少的"支持向量"(support vectors)。
此时,若原始问题和对偶问题都有最优值,则:
d ∗ = max α , β : α i ≥ 0 min w L ( w , α , β ) = min w max α , β : α i ≥ 0 L ( w , α , β ) = p ∗ (18) d^*=\max_{\alpha,\beta:\alpha_i\geq0}\min_{w}\mathcal{L}(w,\alpha,\beta)=\min_{w}\max_{\alpha,\beta:\alpha_i\geq0}\mathcal{L}(w,\alpha,\beta)=p^*\tag {18} d∗=α,β:αi≥0maxwminL(w,α,β)=wminα,β:αi≥0maxL(w,α,β)=p∗(18)
2.4 示例
求解以下优化问题:
min x f ( x ) = x 1 2 + x 2 2 s. t. h ( x ) = x 1 − x 2 − 2 = 0 g ( x ) = ( x 1 − 2 ) 2 + x 2 2 − 1 ≤ 0 (19) \begin{array}{ll} \min_{\boldsymbol{x}} & f(\boldsymbol{x})=x_1^2+x_2^2\\ \textrm{s. t.} & h(\boldsymbol{x})=x_1-x_2-2=0\\ ~ & g(\boldsymbol{x}) = (x_1-2)^2+x_2^2 -1\leq 0\\ \end{array}\tag{19} minxs. t. f(x)=x12+x22h(x)=x1−x2−2=0g(x)=(x1−2)2+x22−1≤0(19)
由于优化问题 ( 19 ) (19) (19)相对简单,我们可以先通过作图来直观感受以下:
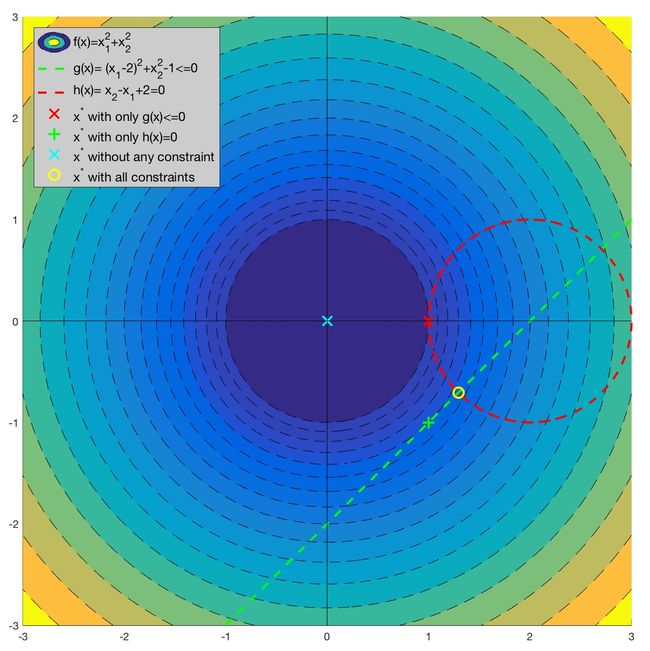
之所以说这个案例比较典型是因为它与线性SVM的数学模型非常相似,且包含了等式和不等式两种不同的约束条件。更重要的是,这两个约束条件在优化问题中都起到了作用。如图所示(左上角所示):
①如果没有任何约束条件,最优解在坐标原点(0, 0)处;
②如果只有不等式约束条件 g ( x ) ≤ 0 g(\boldsymbol{x})\leq 0 g(x)≤0,最优解在坐标(1,0)处(红色X);
③如果只有等式约束条件 h ( x ) = 0 h(\boldsymbol{x})=0 h(x)=0 ,最优解在坐标(1,-1)处(绿色+);
④如果两个约束条件都有,最优解在 ( 2 − 2 / 2 , − 2 / 2 ) (2-\sqrt{2}/2,-\sqrt{2}/2) (2−2/2,−2/2) 处(黄色O)。
针对这一问题,我们可以设计拉格朗日函数如下:
L ( x , α , β ) = ( x 1 2 + x 2 2 ) + α [ ( x 1 − 2 ) 2 + x 2 2 − 1 ] + β ( x 1 − x 2 − 2 ) (20) L(\boldsymbol{x},\alpha,\beta)=(x_1^2+x_2^2)+\alpha\left[(x_1-2)^2+x_2^2-1\right]+\beta(x_1-x_2-2)\tag{20} L(x,α,β)=(x12+x22)+α[(x1−2)2+x22−1]+β(x1−x2−2)(20)
根据式子 ( 5 ) (5) (5)可知:
θ P ( x ) = max α , β : α ≥ 0 L ( x , α , β ) (21) \theta_{\mathcal{P}}(x)=\max_{\alpha,\beta:\alpha\geq0}\mathcal{L}(x,\alpha,\beta)\tag{21} θP(x)=α,β:α≥0maxL(x,α,β)(21)
此时,我们依然可以得到,如果 x x x不满足上面的两个约束条件,即:
①若 g ( x ) > 0 g(x)>0 g(x)>0;则可以任取 α \alpha α使得 θ P ( x ) \theta_{\mathcal{P}}(x) θP(x)趋于无穷;
②若 h ( x ) ≠ 0 h(x)\neq0 h(x)=0;则只有任取 β \beta β,且 β , h ( x ) \beta,h(x) β,h(x)同号,那么 θ p ( x ) \theta_p(x) θp(x)依旧可能趋于无穷;
③而只有两个约束条件同时满足, θ P ( x ) \theta_{\mathcal{P}}(x) θP(x)才可能取得极值;
于是同样有:
θ P ( x ) = { f ( x ) , if x satisfies primal constraints ∞ , otherwise (22) \begin{aligned} \theta_{\mathcal{P}}(x) = \begin{cases} f(x), & \text{if $x$ satisfies primal constraints} \\[2ex] \infty, & \text{otherwise} \end{cases} \end{aligned}\tag{22} θP(x)=⎩⎨⎧f(x),∞,if x satisfies primal constraintsotherwise(22)
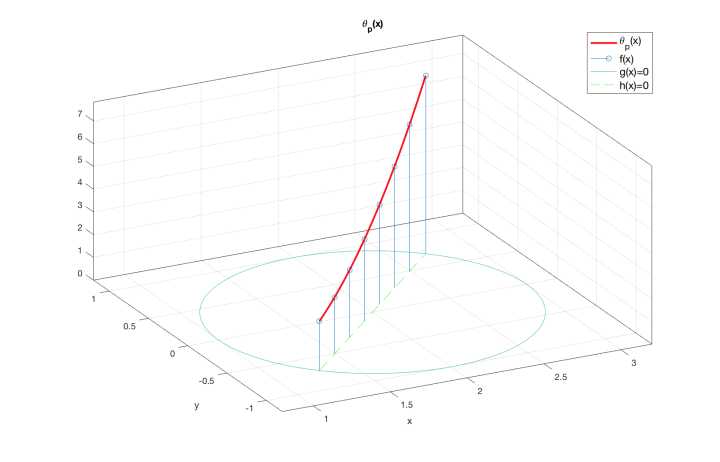
如图所示:函数 θ P ( x ) \theta_{\mathcal{P}}(\boldsymbol{x}) θP(x) 只在绿色直线在圆圈内的部分——也就是直线 h ( x ) = 0 h(\boldsymbol{x})=0 h(x)=0在圆 g ( x ) = 0 g(\boldsymbol{x})=0 g(x)=0上的弦——与原目标函数 f ( x ) f(\boldsymbol{x}) f(x) 取相同的值,而在其他地方均有 θ P ( x ) = + ∞ \theta_P(\boldsymbol{x})=+\infty θP(x)=+∞。
故,其原始问题为:
p ∗ = min x max α , β : α > 0 L ( x , α , β ) (23) p^*=\min_{x}\max_{\alpha,\beta:\alpha>0}\mathcal{L}(x,\alpha,\beta)\tag{23} p∗=xminα,β:α>0maxL(x,α,β)(23)
接着,那么其对偶问题就应该为:
d ∗ = max α , β : α > 0 min x L ( x , α , β ) (24) d^*=\max_{\alpha,\beta:\alpha>0}\min_{x}\mathcal{L}(x,\alpha,\beta)\tag{24} d∗=α,β:α>0maxxminL(x,α,β)(24)
对于求解对偶问题,一般分为两步:
-
第一步,最小化 L ( x , α , β ) \mathcal{L}(x,\alpha,\beta) L(x,α,β);
我们将 α , β \alpha,\beta α,β视为常数,这时 L ( x , α , β ) L(\boldsymbol{x},\alpha,\beta) L(x,α,β) 就只是 x \boldsymbol{x} x的函数。我们可以通过求导等于零的方式寻找其最小值,即 θ D ( α , β ) = min x [ L ( x , α , β ) ] \theta_{\mathcal{D}}(\alpha,\beta)=\min_{\boldsymbol{x}}\left[L(\boldsymbol{x},\alpha,\beta)\right] θD(α,β)=minx[L(x,α,β)]
{ β + 2 x 1 + α ( 2 x 1 − 4 ) = 0 2 x 2 − β + 2 α x 2 = 0 (25) \left\{\begin{array}{l} \beta + 2x_1 + \alpha (2x_1 - 4)=0\\ 2x_2 - \beta + 2\alpha x_2=0 \end{array}\right.\tag{25} {β+2x1+α(2x1−4)=02x2−β+2αx2=0(25)
可以解得:
{ x 1 = 4 α − β 2 α + 2 x 2 = β 2 α + 2 (26) \left\{ \begin{array}{l} x_1 = \frac{4\alpha-\beta}{2\alpha + 2}\\ x_2 = \frac{\beta}{2\alpha + 2} \end{array}\right.\tag{26} {x1=2α+24α−βx2=2α+2β(26)将 ( 25 ) (25) (25)代入拉格朗日目标函数 ( 20 ) (20) (20)可以得到:
θ D ( α , β ) = − β 2 + 4 β + 2 α 2 − 6 α 2 ( α + 1 ) (27) \theta_{\mathcal{D}}(\alpha,\beta)= -\frac{\beta^2 + 4\, \beta + 2\, \alpha^2 - 6\, \alpha}{2\, \left(\alpha + 1\right)}\tag{27} θD(α,β)=−2(α+1)β2+4β+2α2−6α(27) -
第二步,最大化 θ D ( α , β ) \theta_{\mathcal{D}}(\alpha,\beta) θD(α,β)
此时可以将 θ D ( α , β ) \theta_{\mathcal{D}}(\alpha,\beta) θD(α,β)看成是一个二元函数求极值(无条件)的问题,且 α > 0 \alpha>0 α>0。用拉格朗日乘数法即可求解。设 D = θ D ( α , β ) D=\theta_{\mathcal{D}}(\alpha,\beta) D=θD(α,β),则 D D D分别对 α , β \alpha,\beta α,β求偏导并令其为0有:
∂ D ∂ α = − 2 α 2 + 4 α − β 2 − 4 β − 6 2 ( α + 1 ) 2 = 0 ; ∂ D ∂ β = 2 β + 4 2 ( α + 1 ) = 0 \begin{aligned} \frac{\partial D}{\partial\alpha}&=-\frac{2\alpha^2+4\alpha-\beta^2-4\beta-6}{2(\alpha+1)^2}=0;\\[2ex] \frac{\partial D}{\partial\beta}&=\frac{2\beta+4}{2(\alpha+1)}=0 \end{aligned} ∂α∂D∂β∂D=−2(α+1)22α2+4α−β2−4β−6=0;=2(α+1)2β+4=0
联立求得:
α = 2 − 1 ( > 0 ) , β = − 2 (28) \alpha=\sqrt{2}-1(>0),\;\beta=-2\tag{28} α=2−1(>0),β=−2(28)
再将 ( 28 ) (28) (28)代入 ( 26 ) (26) (26)即可求得 x x x.
3 总结
在这篇文章中,笔者首先介绍了广义的拉格朗日乘数法;然后进一步介绍了如何通过拉格朗日对偶方法来进行求解;最后我们还通过一个示例来对整个求解过程进行了演算。实话说,尽管笔者在写这部分内容的时候也看了不少资料,但还是有很多东西笔者自己也不是十分的清楚,因此难免会存在各种问题。可以说,支持向量机的整个求解过程应该算是机器学习算法中数学要求最高的一个。本次内容就到此结束,感谢阅读!
若有任何疑问与见解,请发邮件至[email protected]并附上文章链接,青山不改,绿水长流,月来客栈见!
引用
[1] https://zhuanlan.zhihu.com/p/24638007
[2] Andrew Ng. CS229. Note3 http://cs229.stanford.edu/notes/cs229-notes3.pdf
[3]支持向量机通俗导论(理解SVM的三层境界)](http://blog.csdn.net/v_july_v/article/details/7624837)
[4]《统计机器学习(第二版)》李航,公众号回复“统计学习方法”即可获得电子版与讲义
推荐阅读
[1]原来这就是支持向量机
[2]从另一个角度理解支持向量机
[3]好久不见的拉格朗日乘数法
