Unity性能优化归纳
Unity优化入手方向
优化涉及的三大方面
1. CPU方面。例如,DrawCall调用。DrawCall是CPU对底层图形程序接口的调用,用以在屏幕上绘制内容。
2. GPU方面。Fragment优化,涉及GPU;Batching合并。将批处理之前需要很多次调用(Draw Call)的物体合并,之后只需要调用一次底层图形程序的接口就行。
3. 内存方面。
Unity优化策略
检测性能问题
1. 性能分析的最佳途径。
- 检查目标脚本是否在场景中出现。
- 检查脚本是否运行了正确的次数。
- 最小化脚本变化。
- 缩小内部干扰。
- 缩小外部干扰。
2. 代码片段的定向profile。
- Profiler.BeginSample()&Profiler.EndSample()。
- Custom CPU Profiling:使用Stopwatch。
编码策略
1. 缓存Component引用。
2. 使用最快的方式获取Component:GetComponent
3. 删除空的回调声明,例如Start(),Update()等。
4. 避免在运行时使用Find()和SendMessage()。
5. 使用静态类Static Classes。
6. 使用单例,静态类只能继承Object,不能继承MonoBehaviour。
7. 通过SerializeField添加引用。
8. 自定义消息系统。
9. 禁用不再使用的脚本和物体,通过是否可是或者距离禁用物体。
10. 在比较距离的时候考虑使用:Distance-Squared。
11. 避免获取GameObject的字符串属性,如使用CompareTag(Str)而不是使用Tag==str。
12. 使用Coroutine和InvokeRepeating代替Update。
13. 缓存Transform,尽量使用local*。
14. 更快的null refernce check,使用!System.Object.RefernceEquals(GameObject, null)替代gameObject!=null。
Batching收益
1. 动态批处理条件
- 相同材质。
- 使用MeshRenderer或是粒子系统。
- Shader所用顶点属性不超过900。
- 相同Lightmap文件。
- 单通道。
- 每批次不超过300个网格,32000个顶点。
2. 静态批处理
- 网格必须是Static。
- 每个被静态处理的网格需要额外的内存。
- 运行时才能看到dc变化。
- 不能在运行时添加。
- 运行时位置和角度不能变化。
- 同一批中任意物体可视则全部会被渲染。
内存优化
1. 对象池。
2. 合理GC。
动态图形(Dynamic Graphics)
1. LOD。
2. 禁用GPU Skinning,将皮肤的计算压力转移至CPU。
3. Reduce Tessellation(降低Geometry Shader的复杂度)
4. 遮挡剔除。
5. 优化Shader。
6. 减少纹理数据,如降低纹理质量,使用Mipmap等。
7. 测试不同的纹理压缩格式。
8. 减少纹理采样。
9. 组织资源或者减少纹理切换。
10. 使用合适的ShadingMode。
11. 使用灯光组件的CullingMask。
12. 使用烘焙的灯光贴图。
13. 优化投影。
物理性能优化
1. 尽量大的TimeStep。
2. 减少FixedUpdate消耗的时间。
3. 没有RigidBody的碰撞体为静态碰撞体,合理使用静态碰撞体。
4. 慎用连续碰撞和连续动态碰撞。
5. 慎用MeshCollider。
6. 优化CollisionMatrix。
7. Scale应该在(1,1,1)附件,位置应靠近(0, 0, 0),质量应在0.1附近,不超过10。
8. Minimize cast and bounding-Volume Checks。
9. 减少复杂碰撞体组件的使用,如Terrain,Cloth, Wheel等。
10. Let Physics Objects Sleep。
11. Modify Solver Iteration Count。
12. 优化 Ragdolls。
- Reduce Joints and Colliders。
- Avoid Inter-Ragdoll Collision。
- Distable or Remove Inactive Ragdolls。
13. Know When to use physics。
资源优化
1. 声音
(1) 加载类型
- Decompress On Load大部分情况下使用。适用于小的音频文件。
- CompressedInMemory牺牲CPU换区内存。
- Streaming通常用在背景音乐。
(2) Load In BackGround。
(3) PreloadAudioData。
(4) 需要在远程设备或Standalone应用中测试内存使用。
(5) 性能增强:
- 最小化AudioSource数量。
- 最小化AudioClip的引用。
- 3D音效勾选ForceToMono。一般情况下用单声道效果是足够的,把它压缩成单声道可以减少内存的使用。
- 降低采样率。一般采样率20K就足够了。
- 考虑所有的编码方式。
- 小心使用Streaming。
- 使用AudioMixer添加滤镜。
- 使用Resource.UnloadAssets()释放不再使用的资源。
- 使用AudioModule(TrackModule)文件作为背景音乐。
(6) 建议ios使用mp3,andriod使用vorbis。
2. 纹理
- 缩减纹理文件大小。
- 明智地使用Mipmap。
- 避免使用psd或tiff。
- 调整AnisoLevel。
- 考虑使用图集。
- 为非正方形纹理调整压缩率。
- SparseTextures。
- Procedural Materials。
3. 网格和动画
(1) 模型导入:
- 模型导入要使用FBX文件,很多项目它的模型导入会把Read/Write打开,这个设置打开一下会导致内存翻倍。需要合理设置Read-Write Enable。
- 模型导入有三个选项卡,其中一个是动画相关的选项卡,默认不是None,即使FBX里面没有动画数据的话,也会默认添加一个Animator的组件,会增加了内存的占用,需要检查导入设置。
- FBX导入的时候,如果不使用一些Normalmap等特性,如果开了Normal Tangent导入也都是浪费了内存空间,一般都是在项目开始初期决定用不用Normal Map,如果不用的话以后可以把这个关闭掉。
(2) 减少面数。
(3) 改变MeshCompression设置。
(4) import/Calculate设置。
(5) 勾选OptimizeMesh。
(6) 合并网格。
(7) 动画:
- 考虑烘焙动画。
- 可以设置动画的压缩。
- 检查一下原始动画制作的时候是按照什么帧率制作出来的。
4. Resources文件夹优化:
-
现在Unity官方不再推荐使用Resources文件夹,把资源放在这里面的话,它是有几个缺点的,第一个缺点你游戏启动的时候,它第一步会把Resources文件夹内的文件构建一个索引,这样后面再动态加载资源的时候,可以在这里面查找这个文件,这样做导致游戏启动比较耗时,会发现启动黑屏的时间很长,这样对玩家来说这样的体验不太好。
-
另外,构建索引会占用你更多系统的内存资源。
5. Shader预编译问题:
- 有些时候游戏里面跑到一段时间发生卡顿,很多时候是做了Shader编译,引擎提供一个功能是Shader.WarmupAllShaders,推荐的使用方式是游戏场景加载完之后,可以调用这个API,把场景当中引用的Shader预先编译一下,这样游戏过程当中再使用的时候就不会再去调用编译的操作,这样就避免你游戏过程当中产生Shader编译导致的卡顿。
CPU方面的优化
1. 一些常见的影响CPU效率的项目:
- DrawCalls。
- 物理组件(Physics)。
- GC(用来处理内存)
- 脚本中的代码质量。
对DrawCalls进行优化
1. 对DrawCall的优化,主要就是为了尽量解放CPU在调用图形接口上的开销。所以针对DrawCall主要的思路就是每个物体尽量减少渲染的次数,多个物体最好一起渲染。
2. 优化方案:
- 使用DrawCallBatching。Unity在运行时可以将一些物体进行合并,从而用一个描绘调用来渲染他们。
- 通过将纹理打包成图集尽量减少材质的使用。
- 尽量少使用反光,阴影之类的效果,因为那会使物体多次渲染。
使用DrawCallBatching批处理
1. 使用DrawCallBatching需要保证物体之间的材质相同,这样才能有效降低DrawCall数量。

2. 静态批处理:
- 只要场景中物体不移动,并且拥有相同的材质,静态批处理就允许引擎对任意大小的几何物体进行批处理操作来降低绘制调用。
-
如果想要使用静态批处理,需要明确指出哪些物体是静止的,并且在游戏中永远不会移动,旋转和缩放。可以在“Inspector”视图中勾选“Static"复选框即可。
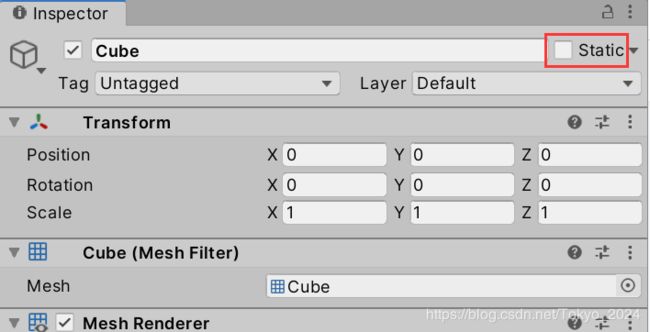
- 静态批处理的好处很多,其中之一就是与动态批处理相比,约束要少得多。一般推荐使用DrawCall的静态批处理来减少DrawCall的次数。
3. 动态批处理。
- Unity中DrawCall动态批处理机制是引擎自动进行的,无需像静态批处理那样手动设置Static。
- 例如动态实例化Prefab的例子,如果动态物体共享相同的材质,则引擎会自动对DrawCall优化,进行批处理。

- 批处理动态物体需要在每个顶点上进行一定的开销,所以动态批处理仅支持小于900顶点的网格物体。
- 如果着色器使用顶点位置,发现和UV值3种属性,那么只能批处理300顶点以下的物体;如果着色器需要使用顶点位置,法线,UV0,UV1和切向量,那只能批处理180顶点以下的物体。
- 不要使用缩放。不同缩放值得两个物体将不会进行动态批处理。统一缩放的物体不会与非统一缩放的物体进行批处理。
- 使用不同材质的实例化物体将会导致批处理失败。
- 拥有lightmap的物体含有额外(隐藏)的材质属性,例如lightmap的偏移和缩放系数等。所以,拥有lightmap的物体将不会进行批处理(除非它们指向lightmap的同一部分)
- 预设体的实例化会自动地使用相同的网格模型和材质。
- 多通道的Shader会妨碍批处理操作。
对物理组件的优化
从性能优化的角度考虑,物理组件能少用还是少用为好。
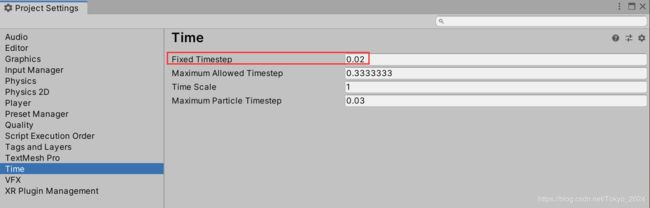
设置一个合适的FixedTimestep
1. FixedTimestep这个指标和物理计算相关。如果计算频率太高,自然会影响到CPU的开销。同时,若计算评率达不到游戏设计时的要求,又会影响到功能的实现,所以如何抉择需要开发人员具体分析,选择一个合适的值。
尽量不要使用网格碰撞器(Mesh Collider)
1. Mesh Collider非常复杂,利用一个网格资源并在其上构建碰撞器。对于复杂网状模型上的碰撞检测,它要比应用原型碰撞器精确得多。标记为凸起的网格碰撞器才能够和其他网格碰撞器发生碰撞。
2. 手机游戏无须这种性价比不高的东西。
处理内存,却让CPU受伤的GC
GC概述
1. 虽然GC时用来处理内存的,但的确增加的时CPU的开销。因此他的确能达到释放内存的效果,但代价更加沉重,会加重CPU的负担。因此对于GC的优化目标就是尽量少的触发GC。
2. GC是Mono运行时的机制,而非Unity游戏引擎的机制。所以GC主要针对Mono的对象来说的,而不是用来处理引擎的assets(纹理,音效)的内存释放的,它管理的也是Mono的托管堆。
3. 分配到托管堆上的是引用类型。比如类的实例,字符串,数组等。而作为int类型,float类型,包括结构体其实都是值类型,他们会被分配到堆栈上而非堆上。
4. GC的触发情况:
- 堆的内存不足时,会自动调用GC。
- 作为编程人员,也可以手动调用GC。
优化方案
1. 字符串连接的处理。因为将两个字符串连接的过程,其实是生成一个新的字符串的过程,而之前旧字符串就成为了垃圾;而作为引用类型的字符串,其空间是在堆上分配的,被弃置的旧字符串的空间就会被GC当做垃圾回收。
2. 尽量不要使用foreach语句,而使用for语句。foreach语句其实会涉及到迭代器的使用,而据说每一次循环所产生的迭代器会带来24Bytes的垃圾。
3. 不要直接访问GameObject的Tag属性。因为访问物体的tag属性会在堆上额外的分配空间。不要使用诸如if(go.tag == "human"),最好换成if(go.CompareTag("human"))。
4. 使用“池”以实现空间的重复利用。
5. 最好不用LINQ的命令,因为他们会分配临时的空间,同样也是GC收集的目标。而且它有可能在某些情况下不能很好地进行AOT编译。
对代码质量进行优化
1. 获取对象,组件等应该只访问一次并保留引用。下图为某个试验中对比方法获取属性的时间。

2. 最好不要频繁地使用GetComponent,尤其是在循环中。
3. 使用内建的数组,例如用Vector3.zero,而不是new Vector(0, 0, 0)。
4. 对于方法的参数的优化,善于使用ref关键字。
5. 善于使用OnVecameVisible()和OnBecameInvisible()来控制物体的update()函数的执行以减少开销。
GPU方面优化
1. GPU的瓶颈主要存在以下4个方面:
- 填充率。图形处理单元每秒渲染的像素数量。
- 像素的复杂度。比如动态阴影,光照,复杂的Shader等。
- 几何体的复杂度(顶点数量)。
- GPU的显存带宽。
2. 据上可知:影响GPU性能的无法就是两大方面,一方面是顶点数量过多,像素计算过于复杂;另一方面就是GPU的显存带宽。
- 减少顶点数量,简化计算复杂度。
- 压缩图片,适应显存带宽。
减少绘制的数目
1. 保持材质的数目尽可能少,这使得Unity更容易进行批处理。
2. 使用纹理图集(一张大贴图包含了很多子贴图)来替代一系列单独的小贴图。他们可以更快地被加载,具有很少的状态转换,而且批处理更友好。
3. 如果使用了纹理图集和共享材质,使用Renderer.sharedMaterial来代替Renderer.material。
4. 使用光照纹理(lightmap)而非实时灯光。
5. 使用LOD,好处就是对那些离得远,看不清的物体的细节可以忽略。
6. 遮挡剔除。
7. 使用mobile版的shader,因为简单。
优化显存带宽
1. OepnGL ES2.0使用ETC1格式压缩等,或者在OpenGL ES3.0使用ETC2格式压缩图片。
2. 使用Mipmap。
内存的优化
1. Unity中主要包含四类内存:
- 资源内存占用。
- 引擎模块自身内存占用。
- 托管堆内存占用。
- 若干我们自己引入的DLL或者第三方DLL所需要的内存。
2. Unity使用C#语言托管了内存的释放,导致开发者不能选择在什么时间去释放内存。如果场景非常复杂的话,它需要遍历场景中的所有对象,C#的GC操作会非常耗时。很多游戏里面玩的过程当中发现游戏卡顿都是内存GC导致的卡顿,关键的一点是游戏过程当中,尤其是每帧的操作的函数里面,尽量不要在堆栈分配内存。
资源内存占用
在一个较为复杂的大中型项目中,资源的内存占用往往占据了总体内存的70%以上。其中,纹理、网格、动画片段和音频片段则是最容易造成较大内存开销的资源。
一. 纹理
纹理资源可以说是几乎所有游戏项目中占据最大内存开销的资源。一个6万面片的场景,网格资源最大才不过10MB,但一个2048x2048的纹理,可能直接就达到16MB。因此,项目中纹理资源的使用是否得当会极大地影响项目的内存占用。
通常可以通过纹理格式,纹理尺寸和Mipmap功能来对纹理进行优化。
1. 纹理格式。
(1) 纹理格式是研发团队最需要关注的纹理属性。因为它不仅影响着纹理的内存占用,同时还决定了纹理的加载效率。
(2) 一般来说,建议开发团队尽可能根据硬件的种类选择硬件支持的纹理格式,比如Android平台的ETC、iOS平台的PVRTC、Windows PC上的DXT等等。
(3) 可以在性能分析过程中,将纹理格式进行详细罗列,以便开发团队进行快速查找,一步定位。
(4) 在使用硬件支持的纹理格式时,你可能会遇到以下几个问题:
- 色阶问题。由于ETC、PVRTC等格式均为有损压缩,因此,当纹理色差范围跨度较大时,均不可避免地造成不同程度的“阶梯”状的色阶问题。因此,很多研发团队使用RGBA32/ARGB32格式来实现更好的效果。但是,这种做法将造成很大的内存占用。比如,同样一张1024x1024的纹理,如果不开启Mipmap,并且为PVRTC格式,则其内存占用为512KB,而如果转换为RGBA32位,则很可能占用达到4MB。所以,研发团队在使用RGBA32或ARGB32格式的纹理时,一定要慎重考虑,更为明智的选择是尽量减少纹理的色差范围,使其尽可能使用硬件支持的压缩格式进行储存。
- ETC1 不支持透明通道问题。在Android平台上,对于使用OpenGL ES 2.0的设备,其纹理格式仅能支持ETC1格式,该格式有个较为严重的问题,即不支持Alpha透明通道,使得透明贴图无法直接通过ETC1格式来进行储存。建议研发团队将透明贴图尽可能分拆成两张,即一张RGB24位纹理记录原始纹理的颜色部分和一张Alpha8纹理记录原始纹理的透明通道部分。然后,将这两张贴图分别转化为ETC1格式的纹理,并通过特定的Shader来进行渲染,从而来达到支持透明贴图的效果。该种方法不仅可以极大程度上逼近RGBA透明贴图的渲染效果,同时还可以降低纹理的内存占用。
- 目前已经有越来越多的设备支持了OpenGL ES 3.0,这样Android平台上你可以进一步使用ETC2甚至ASTC,这些纹理格式均为支持透明通道且压缩比更为理想的纹理格式。如果你的游戏适合人群为中高端设备用户,那么不妨直接使用这两种格式来作为纹理的主要存储格式。
2. 纹理尺寸。
(1) 一般来说,纹理尺寸越大,则内存占用越大。所以,尽可能降低纹理尺寸,如果512x512的纹理对于显示效果已经够用,那么就不要使用1024x1024的纹理,因为后者的内存占用是前者的四倍。
(2) 在性能分析报告中,可以将纹理的尺寸进行详细展示,以便开发团队进行快速检测。
3. Mipmap功能。
(1) Mipmap旨在有效降低渲染带宽的压力,提升游戏的渲染效率。但是,开启Mipmap会将纹理内存提升1.33倍。
(2) 对于具有较大纵深感的3D游戏来说,3D场景模型和角色我们一般是建议开启Mipmap功能。对3D物体,关闭Mipmap会导致远处的纹理有闪烁感,而且渲染性能较低,因此开启3D物体上纹理的Mipmap。
(3) 对2D物体,Mipmap并不会导致闪烁和性能问题,所以建议关闭2D以及UI纹理上的Mipmap选项,开启Mipmap并不会提升渲染效率,反倒会增加无谓的内存占用。
(4) 在性能分析报告中,通过Mipmap一项进行排序,详细检测开启Mipmap功能的资源是否为UI资源。
4. Read&Rrite。
(1) 一般情况下,纹理资源的“Read & Write”功能在Unity引擎中是默认关闭的。
(2) 开启该选项将会使纹理内存增大一倍。

5. 纹理导入:
- 有些不需要Alpha通道的纹理在导入时保留了Alpha通道,把这些不必要的Alpha通道都关闭掉。
二. Mesh网格
1. Normal、Color和Tangent
(1) Mesh资源的数据中经常会含有大量的Color数据、Normal数据和Tangent数据。这些数据的存在将大幅度增加Mesh资源的文件体积和内存占用。其中,Color数据和Normal数据主要为3DMax、Maya等建模软件导出时设置所生成,而Tangent一般为导入引擎时生成。
(2) 如果项目对Mesh进行Draw Call Batching操作的话,那么将很有可能进一步增大总体内存的占用。比如,100个Mesh进行拼合,其中99个Mesh均没有Color、Tangent等属性,剩下一个则包含有Color、Normal和Tangent属性,那么Mesh拼合后CombinedMesh中将为每个Mesh来添加上此三个顶点属性,进而造成很大的内存开销。
(3) 在性能优化报告中需要为每个Mesh展示了其Normal、Color和Tangent属性的具体使用情况,研发团队可以直接针对每种属性进行排序查看,直接定位出现冗余数据的资源。
(4) 一般来说这些数据主要为Shader所用,来生成较为酷炫的效果。所以,建议研发团队针对项目中的网格资源进行详细检测,查看该模型的渲染Shader中是否需要这些数据进行渲染。
2. 关闭模型不必要的Read/Write Enable。开启Read/Write Enabled一般是用于运行时修改Mesh的顶点数据,开启这个选项会导致Mesh的内存占用翻倍。因此如果项目中不需要在运行时修改这些Mesh数据的话,建议把这个选项关闭。

三. 音频资源
1. 音频设置:流式加载音频,用CPU耗能换取内存(内存性能不好的机器建议开启),对于音乐或者其他很长的音轨十分有用。
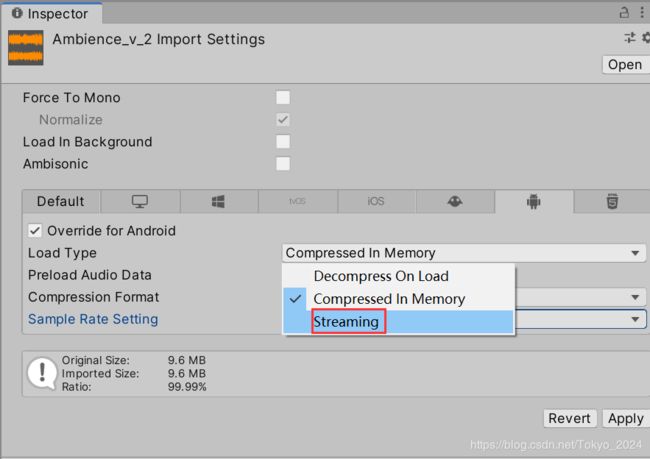
四. GUI系统
1. OnGUI是Unity老的UI系统,现在不建议使用OnGUI。第三方的插件NGUI,也是有它的不足。因为它使用C#开发,会导致堆栈的内存分配,运行时会导致内存的操作。
引擎模块自身占用
引擎自身中存在内存开销的部分纷繁复杂,可以说是由巨量的“微小”内存所累积起来的,比如GameObject及其各种Component(最大量的Component应该算是Transform了)、ParticleSystem、MonoScript以及各种各样的模块Manager(SceneManager、CanvasManager、PersistentManager等)。一般情况下,上面所指出的引擎各组成部分的内存开销均比较小,真正占据较大内存开销的是这两处:WebStream 和 SerializedFile。其绝大部分的内存分配则是由AssetBundle加载资源所致。
一. WebStream:
1. 使用new WWW或CreateFromMemory来加载AssetBundle时,Unity引擎会加载原始数据到内存中并对其进行解压,而WebStream的大小则是AssetBundle原始文件大小 + 解压后的数据大小 + DecompressionBuffer(0.5MB)。同时,由于Unity 5.3版本之前的AssetBundle文件为LZMA压缩,其压缩比类似于Zip(20%-25%),所以对于一个1MB的原始AssetBundle文件,其加载后WebStream的大小则可能是5~6MB。
2. 当项目中存在通过new WWW加载多个AssetBundle文件,且AssetBundle又无法及时释放时,WebStream的内存可能会很大,这是研发团队需要时刻关注的。
二. SerializedFile
1. 对于SerializedFile,则是当使用LoadFromCacheOrDownload、CreateFromFile或new WWW本地AssetBundle文件时产生的序列化文件。
2. 对于WebStream和SerializedFile,需要关注以下两点:
- 是否存在AssetBundle没有被清理干净的情况。开发团队可以通过Unity Profiler直接查看其使用具体的使用情况,并确定Take Sample时AssetBundle的存在是否合理;
- 对于占用WebStream较大的AssetBundle文件(如UI Atlas相关的AssetBundle文件等),建议使用LoadFromCacheOrDownLoad或CreateFromFile来进行替换,即将解压后的AssetBundle数据存储于本地Cache中进行使用。这种做法非常适合于内存特别吃紧的项目,即通过本地的磁盘空间来换取内存空间。
三. 后期特效
1. 后期特效其实有多个问题,首先它的GPU消耗比较高,另外一个消耗是会导致你的内存消耗非常大,因为每个特效都有可能分配你一个全屏幕大小的一个RenderTexture。而RenderTexture因为要用来实时渲染,所以是不能压缩,不像普通的游戏纹理可以使用ETC或者PVRTC格式压缩。所以它对内存的占用非常高,我们经常看到有的游戏后期特效分配了几十兆甚至更高的内存。
托管堆的内存占用
1. “托管” 的本意是Mono可以自动地改变堆的大小来适应所需要的内存,并且适时地调用垃圾回收(Garbage Collection)操作来释放已经不需要的内存,从而降低开发人员在代码内存管理方面的门槛。
2. Mono的内存分配就是很传统的运行时内存分配。
- 值类型:int型,float型,结构体struct,bool之类的。他们都放在堆栈上(注意不是堆,所以不涉及GC)。
- 引用类型:可以狭义地理解为各种类的实例。由于是在堆上分配,会涉及到GC。
3. Mono托管堆中的那些封装的对象,除了在Mono托管堆上分配封装类实例化之后所需要的内存之外,还会牵扯到其背后对应的游戏引擎内部控件在Unity3D的内部内存上的分配。
4. 目前Unity所使用的Mono版本存在一个很严重的问题,即:Mono的堆内存一旦分配,就不会返还给系统。这意味着Mono的堆内存是只升不降的。举个例子,项目运行时,在场景A中开辟了60MB的托管堆内存,而到下一场景B时,只需要使用20MB的托管堆内存,那么Mono中将会存在40MB空闲的堆内存,且不会返还给系统。这是我们非常不愿意看到的现象,因为对于游戏(特别是移动游戏)来说,内存的占用可谓是寸土寸金的,让Mono毫无必要地锁住大量的内存,是一件非常浪费的事情。
5. 在性能优化过程中,统计测试过程中累积的函数堆内存分配量,通过查看堆内存分配Top10的函数,即可快速对其底层代码实现进行查看,定位是否有分配不必要堆内存的代码存在。
6. 不必要的堆内存分配主要来自于以下几个方面:
- 高频率地 New Class/Container/Array等。切记不要在Update、FixUpdate或较高调用频率的函数中开辟堆内存,这会对你的项目内存和性能均造成非常大的伤害。做个简单的计算,假设你的项目中某一函数每一帧只分配100B的堆内存,帧率是1秒30帧,那么1秒钟游戏的堆内存分配则是3KB,1分钟的堆内存分配就是180KB,10分钟后就已经分配了1.8MB。如果你有10个这样的函数,那么10分钟后,堆内存的分配就是18MB,这期间,它可能会造成Mono的堆内存峰值升高,同时又可能引起了多次GC的调用。
- Log输出。建议对自身Log的输出进行严格的控制,仅保留关键Log,以避免不必要的堆内存分配。
- UIPanel.LateUpdate。这是NGUI中CPU和堆内存开销最大的函数。它本身只是一个函数,但NGUI的大量使用使它逐渐成为了一个不可忽视规则。该函数的堆内存分配和自身CPU开销,其根源上是一致的,即是由UI网格的重建造成。
- 关于代码堆内存分配的注意点还有很多,比如String连接、部分引擎API(GetComponent)的使用等等。