【视觉里程计】对极几何,三角测量,PnP,ICP原理
老早就想写些东西,但是介于个人懒惰,一直没开这个头,前几天才发现自己以前学的东西很容易忘记,于是决定还是将学习做个总结,以便后续回头查看,温故而知新嘛。此文章为对相关知识的一些个人理解,若理解有误,欢迎各位评论留言,一起讨论。若此文章能帮助到你,那真是一举两得了。参考高翔老师的著作《视觉SLAM十四讲:从理论到实践》。
视觉里程计就是一个通过分析处理相关图像序列来确定机器人的位置和姿态,也可以顺带将3D点保存下来构建3D点云图,即完成了SLAM的定位与建图。 本文将从单目、双目与RGB-D相机三个方面分别从原理出发构建视觉里程计,从中探索对极几何,三角测量,PnP以及ICP的相关原理与应用。为了简化构建视觉里程计过程,均默认特征匹配已完成。
单目视觉里程计
单目视觉里程计即使用单目相机来构建视觉里程计,单目SLAM首先需要初始化,先计算出相机运动和特征点的3D位置后续便可以通过3D-2D求解方式计算相机运动了。那么如何通过一帧帧图像序列分析出机器人位置并且顺带将地图给构建出来呢,接下来就一步步探索吧。
对极几何
对极几何(Epipolar geometry)又叫对极约束,根据图像二维平面信息来估计单目相机帧间运动的相对位姿关系。我们将单目相机放置在机器人上,此时计算相机位姿便是得到了机器人位姿。我们通过平移机器人可以得到相邻时刻的两帧图像,如下所示,若特征匹配已完成我们能得到两组点集pi和p’i,p1为点集pi中一点,p2为点集p’i中一点,两点均对应空间中的一点P(坐标未知),
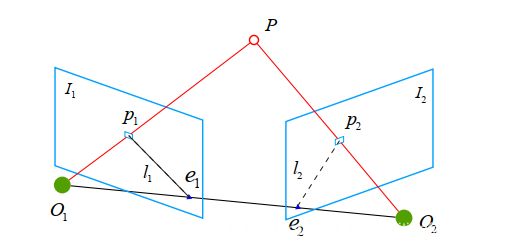
其两点分别在其图像中的投影坐标为p1=[u1,v11]T,和p2=[u2,v2 ,1]T,可得到其满足公式:
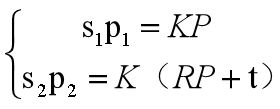
其中 K 为相机内参矩阵, R、 t 为两个坐标系的相机运动。
将上式写为齐次坐标的形式,如下

其中我们记本质矩阵(Essential Matrix) E=t^R,基础矩阵(Fundamental Matrix) F = K−T EK−1,可得x2T Ex1 = p2T F p1 = 0.通过匹配点的像素坐标我们可以求得E或F,接下来使用奇异值分解(SVD)可以求得对应的R和t,具体求解过程可参看《视觉SLAM十四讲》7.3 2D-2D:对极几何 章节。此处相机内参为已知的,求出R和t即能得到第二帧相机位姿相对于第一帧相机位姿的旋转平移矩阵。此时两帧图像之间的旋转平移变换便已求得,至此完成了单目SLAM初始化第一步。
单目SLAM 估计的轨迹和地图,与真实的轨迹和地图之间相差一个因子,这就是所谓的尺度(scale),根据对极约束求解得到的相机旋转运动R是准确的,平移运动t是不具备真实尺度的,又称为尺度不确定。且单目初始化不能只有纯旋转,必须要有一定程度的平移才能完成初始化。
三角测量
三角测量(Triangulation)可以根据前后两帧图像中匹配到的特征点像素坐标以及两帧之间的相机运动R、t ,计算特征点三维空间坐标。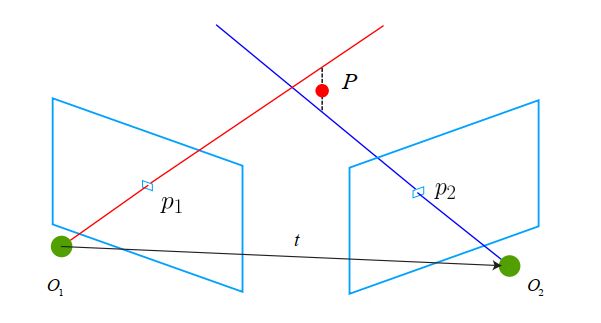 已知匹配点对的像素坐标和第二帧相机坐标系相对于第一帧相机坐标系的R和t,来求p1和p2对应的空间点P分别在两帧相机坐标系下的坐标。按照对极几何中的定义,设 x1、 x2 为两个特征点的归一化坐标,则有:
已知匹配点对的像素坐标和第二帧相机坐标系相对于第一帧相机坐标系的R和t,来求p1和p2对应的空间点P分别在两帧相机坐标系下的坐标。按照对极几何中的定义,设 x1、 x2 为两个特征点的归一化坐标,则有:
![]()
其中s1和s2分别为点P在两个坐标系下的深度。通过对上式左乘x1^, 可得
![]()
该式左侧为零,右侧可看成 s2 的一个方程,可以根据它直接求得s2,同理也可以求得s1。通常来说因为噪声的存在,我们计算出的深度值不一定能使右侧精确为0,因此为保证求得的深度准确性,我们可以使用最小二乘求解来计算深度,而非直接求零解。
此时已经得到匹配点像素坐标以及pi与p’i对应的空间点坐标Pi,至此单目SLAM初始化便已完成。有了以上数据,便可通过2D-3D方式求解相机位姿了。
双目与RGB-D视觉里程计
将双目与RGB-D放在一起是因为两者皆可以通过直接或间接的获取深度信息,省略了单目SLAM初始化的过程。双目相机可以通过相机焦距f和左右相机基线b来计算求得深度信息,而RGB-D相机则可以通过深度相机直接获取深度信息。然后通过相机内参可以计算出特征点对应的3D点在此相机坐标系下的三维坐标。此时单目、双目和RGB-D视觉里程计都拥有了2D和3D点信息,接下来便可以继续通过PnP求解相机位姿了。
PnP
PnP(Perspective-n-Point)可根据某一帧图像中特征点的二维像素坐标及其对应的三维空间坐标,来计算对应的点在相机坐标系下的坐标,便可得到相机相对三维空间坐标系的坐标变换即姿态。若此时这个三维空间坐标为此帧图像的上一帧图像的相机坐标,则可以得到两帧图像之间的变换关系。即利用已知三维结构与图像的对应关系求解相机与参考坐标系的相对关系(相机的外参)。
PnP是一类问题,针对不同的情况有不同的解法,常见的算法有:P3P、DLS、EPnP、UPnP等。
如果两张图像中,其中一张特征点的 3D 位置已知,那么最少只需三个点对(需要至少一个额外点验证结果)就可以估计相机运动,取三个特征点求解PnP问题便是P3P。
P3P 需要利用给定的三个点的几何关系。它的输入数据为三对 3D-2D 匹配点。记 3D点为 A、 B、 C, 2D 点为 a、b、c,其中小写字母代表的点为大写字母在相机成像平面上的投影,如图 7-11 所示。此外, P3P 还需要使用一对验证点,以从可能的解出选出正确的那一个(类似于对极几何情形)。记验证点对为 D − d,相机光心为 O。请注意,我们知道的是A、 B、 C 在世界坐标系中的坐标,而不是在相机坐标系中的坐标。一旦 3D 点在相机坐标系下的坐标能够算出,我们就得到了 3D-3D 的对应点,把 PnP 问题转换为了更为容易计算的 ICP 问题。
我们可以通过线性的方式求解PnP问题,使用直接法或者P3P的相似三角形来先求出相机位姿,再求出空间点。或者使用非线性的方式通过BA(Bundle Adjustment 光束平差法)来构建最小化重投影误差,可以同时优化相机位姿和空间点坐标,具体求解过程可参看《视觉SLAM十四讲》7.7 3D-2D:PnP 章节。
ICP
ICP(Iterative Closest Point)可根据前后两帧图像中匹配好的特征点在相机坐标系下的三维坐标,求解相机帧间运动。也就是通过两帧图像特征匹配后对应的3D点分别在两帧图像相机坐标系下的坐标,来计算相机相对的位姿变换。

ICP问题也可以通过线性或者非线性的方式来求解,线性方式一般采用奇异值分解(SVD)的方式求R和t,非线性的方式则是使用BA以迭代的方式去找最优值,通过最小化重投影误差来求解最优的相机位姿,相比于PnP的BA少优化空间点坐标,使得优化更为简单。具体求解过程可参看《视觉SLAM十四讲》7.9 3D-3D:ICP 章节。
在非线性优化中只需不断迭代,我们就能找到极小值。而且ICP问题存在唯一解或无穷多解的情况。在唯一解的情况下,只要我们能找到极小值解,那么这个极小值就是全局最优值——因此不会遇到局部极小而非全局最小的情况。这也意味着ICP求解可以任意选定初始值。这是已经匹配点时求解 ICP 的一大好处。
总结
1、单目视觉里程计首先初始化,选定第一帧和第二帧图像先根据对极几何求解相机帧间运动得到R1和t1,然后根据三角测量求得一组特征点的3D坐标,我们选定第一帧图像的相机坐标作为世界坐标系,后续所有坐标变换均以此坐标系作为参考系。
将第三帧图像与第二帧图像进行特征匹配,筛选初始化过程中已经得到的部分3D点坐标,此时第二帧图像的3D-第三帧图像的2D构成了PnP的3D-2D的求解问题,可以求得第三帧图像相对于第二帧图像的相机位姿R2和t2以及第三帧匹配点的3D坐标,以便后续使用。通过第三帧相对第二帧的相对位姿T2和第二帧相对第一帧(世界坐标系)的相对位姿T1,既可以求得第三帧相机相对于世界坐标系的位姿,后续所有计算均同理进行,便可跟踪相机的实时位姿了。
2、而双目和RGB-D视觉里程计则少了初始化部分,可以直接获得3D和2D信息,同样将第一帧图像的相机坐标系设为世界坐标系,通过特征匹配得到下一帧的2D点与当前帧的3D点进行PnP求解相机帧间运动和下一帧匹配点的3D坐标,后续依次计算即可得到相机实时位姿。
或者直接使用ICP通过3D-3D点对更简单的求解相机位姿。由于一个像素的深度数据可能测量不到,所以我们可以混合着使用 PnP和 ICP 优化:对于深度已知的特征点,用建模它们的 3D-3D 误差;对于深度未知的特征点,则建模 3D-2D 的重投影误差。于是,可以将所有的误差放在同一个问题中考虑,使得求解更加方便。
3、至此,便是视觉SLAM前端中视觉里程计的构建过程,其中特征匹配、相机内参和传感器误差过程都无法避免的会产生相应的噪声,后续便是对相应误差的非线性优化以及对于累积误差的回环检测了。路还很长,慢慢学习!!!
参考文献
https://blog.csdn.net/lixujie666/article/details/82262513
《视觉slam十四讲》