一、何谓分库分表?
把原本存储于一个库的数据分块存储到多个库(主机)上,把原本存储于一个表的数据分块存储到多个表上。
二、为什么要分库分表?
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大。
另外,由于无法进行分布式式部署,而一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈。
三、分库分表的实施策略
分库分表有垂直切分和水平切分两种:
- 依照不同的表(或者Schema)来切分到不同的数据库(主机)之上,这样的切分称之为数据的垂直(纵向)切分。
- 依据表中的数据的逻辑关系,将同一个表中的数据依照某种条件拆分到多台数据库(主机,当然也可能是同一个数据库)上面。这样的切分称之为数据的水平(横向)切分。
3.1、数据的垂直切分
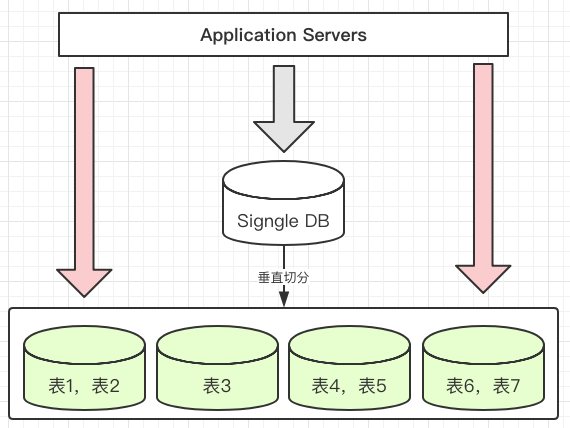
将数据库想象成由非常多个一大块一大块的“数据块”(表)组成,我们垂直的将这些“数据块”切开,然后将他们分散到多台数据库(主机)上面,这样的切分方法就是一个垂直(纵向)的数据切分。
一个架构设计较好的应用系统,它的总体功能肯定是由非常多个功能模块所组成的,每一个功能模块所须要的数据对应到数据库中就是一个或者多个表。
在架构设计中,各功能模块相互之间的交互点越少,系统的耦合度就越低,系统各个模块的维护性以及扩展性也就越好。这样的系统,实现数据的垂直切分也就越简单。
这样的系统,当我们依据功能模块来进行数据的切分,不同功能模块的数据存放于不同的数据库主机中,能够非常简单就避免掉跨数据库的Join存在,同一时候系统架构也非常的清晰。
实际情况下,大部分系统是很难做到全部功能模块所使用的表全然独立,这个就涉及到跨节点Join的问题,这个后面去讲。
3.2、数据的水平切分
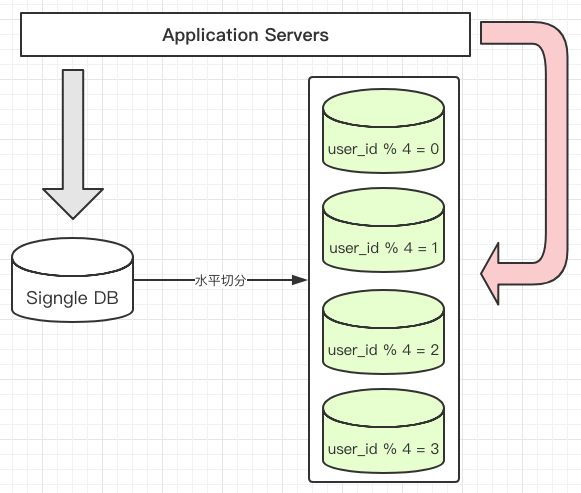
数据的垂直切分基本上能够简单的理解为依照表依照模块来切分数据,而水平切分就不再是依照表或者是功能模块来切分了。一般来说,简单的水平切分主要是将某个访问极其频繁的大表再依照某个字段的某种规则来分散到多个表之中。每一个表中包括一部分数据。
简单来说,就是将表中的某些行切分到一个数据库(表),而另外的某些行又切分到其它的数据库(表)中。当然,为了能够比较容易的判定各行数据被切分到哪个数据库(表)中了,切分总是都须要依照某种特定的规则来进行的。
水平分库分表的切分规则主要包括如下几种:
- 按号段分
user_id为区分,1~1000的对应DB1,1001~2000的对应DB2,以此类推;
优点:可部分迁移
缺点:数据分布不均 - hash取模分:
对user_id进行hash,然后用一个特定的数字,比如应用中需要将一个数据库切分成4个数据库的话,我们就用4这个数字对user_id的hash值进行取模运算,也就是user_id%4,这样的话每次运算就有四种可能:结果为0的时候对应DB1;结果为1的时候对应DB2;结果为2的时候对应DB3;结果为3的时候对应DB4,这样一来就非常均匀的将数据分配到4个DB中。如上图所示。
优点:数据分布均匀
缺点:数据迁移的时候麻烦,不能按照机器性能分摊数据 - 在认证库中保存数据库配置
建立一个DB,这个DB单独保存user_id到DB的映射关系,每次访问数据库的时候都要先查询一次这个数据库,以得到具体的DB信息,然后才能进行我们需要的查询操作。
优点:灵活性强,一对一关系
缺点:每次查询之前都要多一次查询,性能大打折扣 - 其他方式
1)按照地理区域:比如按照华东,华南,华北这样来区分业务。
2)按照时间切分,就是将6个月前,甚至一年前的数据切出去放到另外的一张表,因为随着时间流逝,这些表的数据被查询的概率变小,所以没必要和“热数据”放在一起,这个也是“冷热数据分离”。
以上就是通常的开发中我们选择的方式,有些复杂的项目中可能会混合使用这些方式。
四、数据切分之后的问题解决
数据库中的数据在经过垂直和(或)水平切分被存放在不同的数据库(表)主机之后,应用系统面临的最大问题就是怎样来让这些数据源得到较好的整合,当然也包括切分的一个唯一性保障的问题。
综合来说,主要有以下两个问题:
- 保证ID全局唯一性。
- 查询数据结果集合并问题,这里包括跨节点Join的问题,跨节点合并排序分页问题以及分布式事务问题。
4.1、保证ID全局唯一性
保证ID全局唯一性,主要包括两个要求:
1)全局唯一性:不能出现重复的ID号。
2)数据递增:保证下一ID号一定大于上一个ID号。
一般情况下是将ID生成器作为一个独立模块,需要生成ID时去调用ID生成器。当然,这里需要避免每次用的时候都去获取一次,可以定期去获取一个批次的ID,比如5000个,用完了再去拿,拿到之后存入内存中,内存维护一个集合用来存储,或者你不用集合,通过值去记录每次读取的最新ID,以及他拉取的上限,当用完了一半时,再去触发拉取一次,这样不用等待。
简单例子,一个volatile的线程可见共享变量,每次获取都去修改他的值,这样来保证,如果后续压测发现多线程对同一个共享变量操作会有瓶颈,那么可以切分多个值去分摊压力。
也可以利用MySQL的自增特性。
比如我要把一个表拆分为4个表,那么我可以通过设置每个表的自增ID的起始值和每次自增的值。
举个例子,我把一个表拆分为tb_user_1,tb_user_2,tb_user_3,tb_user_4四个张,它们的起始值分别为1、2、3、4,自增的值都是4。如下
# 新建第一个分表,表名为tb_user_1,自增ID从1开始,每次增加4
CREATE TABLE IF NOT EXISTS tb_user_1(
id INT(11) NOT NULL AUTO_INCREMENT,
title VARCHAR(50),
num INT(11) NOT NULL DEFAULT 0,
PRIMARY KEY (id)
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
ALTER TABLE tb_user_1 AUTO_INCREMENT=1;
#SET auto_increment_offset=1;
SET auto_increment_increment=4;
# 查看设置的结果show variables like '%auto_increment%';
# 新建第二个分表,表名为tb_user_2,自增ID从2开始,每次增加4
CREATE TABLE IF NOT EXISTS tb_user_2(
id INT(11) NOT NULL AUTO_INCREMENT,
title VARCHAR(50),
num INT(11) NOT NULL DEFAULT 0,
PRIMARY KEY (id)
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
ALTER TABLE tb_user_2 AUTO_INCREMENT=2;
#这个是全局设置,不需要重复执行SET auto_increment_increment = 4;
# 新建第三个分表,表名为tb_user_3,自增ID从3开始,每次增加4
CREATE TABLE IF NOT EXISTS tb_user_3(
id INT(11) NOT NULL AUTO_INCREMENT,
title VARCHAR(50),
num INT(11) NOT NULL DEFAULT 0,
PRIMARY KEY (id)
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
ALTER TABLE tb_user_3 AUTO_INCREMENT=3;
# 新建第四个分表,表名为tb_user_4,自增ID从4开始,每次增加4
CREATE TABLE IF NOT EXISTS tb_user_4(
id INT(11) NOT NULL AUTO_INCREMENT,
title VARCHAR(50),
num INT(11) NOT NULL DEFAULT 0,
PRIMARY KEY (id)
)ENGINE=MyISAM DEFAULT CHARSET=utf8;
#ALTER TABLE tb_user_4 AUTO_INCREMENT=4;
# 插入数据进行测试
INSERT INTO tb_user_1(title, num) VALUES('我是一个好人',234);
INSERT INTO tb_user_2(title, num) VALUES('我是一个好人2',234);
INSERT INTO tb_user_3(title, num) VALUES('我是一个好人3',234);
INSERT INTO tb_user_4(title, num) VALUES('我是一个好人4',234);
INSERT INTO tb_user_1(title, num) VALUES('我是一个好人1',234);
INSERT INTO tb_user_1(title, num) VALUES('我是一个好人11',234);
INSERT INTO tb_user_1(title, num) VALUES('我是一个好人111',234);
但是有个问题就是,auto_increment_offset和auto_increment_increment都是全局设置的。如果这样设置之后对其他表的自增ID都有影响,目前不知如何处理。
4.2、查询数据结果集合并问题
结果集合并问题包括跨节点Join的问题,跨节点合并排序分页问题以及分布式事务问题。
先说跨节点Join的问题
数据切分之后,会导致有些老的Join语句无法继续使用。由于Join使用的数据源可能被切分到多个MySQLServer中啦。
如果一定要从MySQL数据数据库端来直接解决的话,目前我这边只找到可以通过MySQL的一种特殊的存储引擎Federated来处理。Federated存储引擎是MySQL解决类似于Oracle的DBLink之类问题的解决方式,但不同之处在于Federated会保存一份远端表结构的定义信息在本地。
但是这种解决方案有一个风险点,那就是假设远端的表结构发生了变更,本地的表定义信息是不会跟着发生对应变化的,那么在这种情况下非常可能造成Query执行出错,无法得到正确的结果。
这类问题,推荐通过应用程序来进行处理,先在驱动表所在的MySQLServer中取出对应的驱动结果集,然后依据驱动结果集再到被驱动表所在的MySQLServer中取出对应的数据。当然这种解决方案对性能会产生一定的影响,但是除了此法,基本上没有太多其它更好的解决的方法了。
再说跨节点合并排序分页问题
一旦进行了数据的水平切分之后,有些排序分页的Query语句的数据源可能也会被切分到多个节点,这样造成的直接后果就是这些排序分页Query无法继续正常执行。事实上这和跨节点Join是一个道理。数据源存在于多个节点上,要通过一个Query来解决,就和跨节点Join是一样的操作。
解决的思路大体上和跨节点Join的解决相似,可是有一点和跨节点Join不太一样。Join非常多时候都有一个驱动与被驱动的关系,所以Join本身涉及到的多个表之间的数据读取一般都会存在一个顺序关系。
排序分页就不太一样,排序分页的数据源基本上能够说是一个表(或者一个结果集)。本身并不存在一个顺序关系,所以在从多个数据源取数据的过程是全然能够并行的。
最后说分布式事务问题
目前比较常见的有两个方式:
- 二阶段提交法
需要有一个事务协调者来保证所有的事务参与者都完成了准备工作(第一阶段)。如果协调者收到所有参与者都准备好的消息,就会通知所有的事务都可以提交了(第二阶段)。 - 事务补偿法
举个例子:将一个跨多个数据库的分布式事务分拆成多个仅处于单个数据库上面的小事务,再通过应用程序来总控各个小事务。
不过,我们应该尽量避免分布式事务,可以拆系统之后使用消息队列来避免分布式事务。
五、真实案例
我们即将做这块,等完成之后再把我们在做的过程中遇到的问题整理在这。
六、小怪的Java群话题讨论内容
找我私发