- html+css网页设计 旅游网站首页1个页面
html+css+js网页设计
htmlcss旅游
html+css网页设计旅游网站首页1个页面网页作品代码简单,可使用任意HTML辑软件(如:Dreamweaver、HBuilder、Vscode、Sublime、Webstorm、Text、Notepad++等任意html编辑软件进行运行及修改编辑等操作)。获取源码1,访问该网站https://download.csdn.net/download/qq_42431718/897527112,点击
- webstorm报错TypeError: this.cliEngine is not a constructor
Blue_Color
点击Details在控制台会显示报错的位置TypeError:this.cliEngineisnotaconstructoratESLintPlugin.invokeESLint(/Applications/RubyMine.app/Contents/plugins/JavaScriptLanguage/languageService/eslint/bin/eslint-plugin.js:97:
- [附源码]SSM计算机毕业设计游戏账号交易平台JAVA
计算机程序源码
java游戏mysql
项目运行环境配置:Jdk1.8+Tomcat7.0+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:SSM+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需要1.运行环境:最好是javajdk1.8,我们在这个平台上运行的。其他版本理论上也可以。2.ID
- Java中的大数据处理框架对比分析
省赚客app开发者
java开发语言
Java中的大数据处理框架对比分析大家好,我是微赚淘客系统3.0的小编,是个冬天不穿秋裤,天冷也要风度的程序猿!今天,我们将深入探讨Java中常用的大数据处理框架,并对它们进行对比分析。大数据处理框架是现代数据驱动应用的核心,它们帮助企业处理和分析海量数据,以提取有价值的信息。本文将重点介绍ApacheHadoop、ApacheSpark、ApacheFlink和ApacheStorm这四种流行的
- Python+Django毕业设计校园易购二手交易平台(程序+LW+部署)
Python、JAVA毕设程序源码
课程设计javamysql
项目运行环境配置:Jdk1.8+Tomcat7.0+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:SSM+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需要1.运行环境:最好是javajdk1.8,我们在这个平台上运行的。其他版本理论上也可以。2.ID
- Hbase - kerberos认证异常
kikiki2
之前怎么认证都认证不上,问题找了好了,发现它的异常跟实际操作根本就对不上,死马当活马医,当时也是瞎改才好的,给大家伙记录记录。KrbException:ServernotfoundinKerberosdatabase(7)-LOOKING_UP_SERVER>>>KdcAccessibility:removestorm1.starsriver.cnatsun.security.krb5.KrbTg
- WebStorm 配置 PlantUML
weijia_kmys
其他webstormideuml
1.安装PlantUML插件在WebStorm插件市场搜索PlantUMLIntegration并安装,重启WebStorm使插件生效。2.安装GraphvizPlantUML需要Graphviz来生成图形。使用Homebrew安装Graphviz:打开终端(Terminal)。确保你已经安装了Homebrew。如果没有,请先安装Homebrew,可以在Homebrew官网获取安装命令。在终端中输
- ReactNative 常用开源组件
2401_84875852
程序员reactnative开源react.js
WebStormReactNative的代码模板插件,包括:1.组件名称2.Api名称3.所有StyleSheets属性4.组件属性https://github.com/virtoolswebplayer/ReactNative-LiveTemplateReact-native调用cordova插件https://github.com/axemclion/react-native-cordova-
- phpstorm 2018激活教程,phpstorm破解版下载
八重樱勿忘
前言:本次phpstorm2018激活教程非常详细,所有细节指导软件是phpstorm10.0是因新版本破解还不稳定,大家放心这个版本不影响开发和使用。文件以及教程都打包在群文件里了。第一步:解压并打开文件,运行“PhpStorm-10.0.3.exe”点击Next进入下一步第二步:选择软件安装目录自定义选择安装根目录-->点击Next进入下一步注意!后面还需要找安装目录里的文件,所以记住安装到一
- Java Kafka生产者实现
stormsha
Javawebjavakafkalinq
欢迎莅临我的博客,很高兴能够在这里和您见面!希望您在这里可以感受到一份轻松愉快的氛围,不仅可以获得有趣的内容和知识,也可以畅所欲言、分享您的想法和见解。推荐:「stormsha的主页」,「stormsha的知识库」持续学习,不断总结,共同进步,为了踏实,做好当下事儿~专栏导航Python系列:Python面试题合集,剑指大厂Git系列:Git操作技巧GO系列:记录博主学习GO语言的笔记,该笔记专栏
- Python 开心消消乐
stormsha
Python基础python开发语言游戏
文章目录效果图项目结构程序代码完整代码:https://gitcode.com/stormsha1/games/overview效果图项目结构程序代码run.pyimportsysimportpygamefrompygame.localsimportKEYDOWN,QUIT,K_q,K_ESCAPE,MOUSEBUTTONDOWNfromdissipate.levelimportManagerfr
- 玩手机的弹指之间,记忆受到了损坏,这是如何发生的?
跨鹿
一:从拍照损伤效应说起为了验证拍照损伤效应(photo-taking-impairmenteffect)——即拍照不利于记忆形成,加州大学圣克鲁斯分校的学者JuliaS.Soares和BenjaminC.Storm进行了两组实验(篇幅有限,不详细介绍该实验):实验一:42名被试与三个独立变量:观察,相机(手机相机)和Snapchat(色拉布,美国的一款“阅后即焚”照片分享应用)——在观察条件下,参
- 【附源码】计算机毕业设计java智慧后勤系统设计与实现
计算机毕设程序设计
javamybatismysql
项目运行环境配置:Jdk1.8+Tomcat7.0+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:SSM+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需要1.运行环境:最好是javajdk1.8,我们在这个平台上运行的。其他版本理论上也可以。2.ID
- Apache Storm:入门了解
布说在见
apachestorm大数据
前言Storm是一个开源的分布式实时计算系统,它能够处理无边界的数据流,类似于Hadoop对于批量数据处理的作用,但是Storm更侧重于实时数据流的处理。以下是关于Storm的一些关键特性及其应用场景的详细介绍:特性实时处理:Storm能够实时处理数据流,而不是像Hadoop那样需要先收集一批数据再进行处理。它可以持续不断地处理数据,这意味着一旦数据到达,就会立即被处理。简单易用:开发者可以用多种
- 大数据秋招面经之spark系列
wq17629260466
大数据spark
文章目录前言spark高频面试题汇总1.spark介绍2.spark分组取TopN方案总结:方案2是最佳方案。3.repartition与coalesce4.spark的oom问题怎么产生的以及解决方案5.storm与flink,sparkstreaming之间的区别6.spark的几种部署方式:7.复习spark的yarn-cluster模式执行流程:8.spark的job提交流程:9.spar
- PhpStorm中配置调试功能
hong161688
phpstormandroidide
在PhpStorm中配置调试功能是一个相对直接且强大的过程,它允许开发者在开发过程中高效地定位和解决代码问题。以下是一个详细的步骤指南,涵盖了从安装PhpStorm到配置调试环境的整个过程,以及如何在PhpStorm中使用调试功能。一、安装PhpStorm首先,确保你已经从JetBrains的官方网站下载了最新版本的PhpStorm。安装过程相对简单,只需按照安装向导的指示逐步进行即可。在安装过程
- 新闻编辑室第1季第4集台词
kuailexuewaiyu
英文中文♪TrytokeepmyheadaboveitthebestIcan♪♪我要努力挺过这一关♪♪That'swhyhereIam♪♪所以我才在这里♪♪Justwaitingforthisstormtopassmeby♪♪等着暴风雨经过♪♪Andthat'sthesoundofsunshine♪♪聆听阳光的声音♪♪Comingdown♪♪从空中洒下♪♪Andthat'sthesoundofsu
- web期末作业网页设计——我的家乡黑龙江(网页源码)
软件技术NINI
html+css+js旅游旅游htmlcss
一、网站题目旅游,当地特色,历史文化,特色小吃等网站的设计与制作。二、✍️网站描述静态网站的编写主要是用HTMLDIV+CSS等来完成页面的排版设计,常用的网页设计软件有Dreamweaver、EditPlus、HBuilderX、VScode、Webstorm、Animate等等,用的最多的还是DW,当然不同软件写出的前端Html5代码都是一致的,本网页适合修改成为各种类型的产品展示网页,
- 使用命令行创建任意大小文件的方法
拽拽夏天~
测试技巧linux功能测试
使用命令行创建任意大小文件的方法作为一个测试工程师,在工作中可能需要创建任意大小的文件。下面介绍下如何使用命令行创建任意大小的文件:1、Linux-dd命令:Linux下的dd命令很是强大,可以这样使用dd命令来创建指定大小的文件:生成固定大小文件ddif=/dev/zeroof=/home/bluestorm/100M.imgbs=1Mcount=1024(生成一个100M的文件,文件名为100
- phpstorm 插件等功能
胡萝卜的兔
laravelphpstormphpphpstormide
插件MaterialThemeUIUI主题插件ChinesePHPDocumentphp基本函数的中文文档PHPcomposer.jsonsupport在做php组件开发时,编辑composer.json文件时有对应的属性和值的自动完成功能BackgroundImagePlus背景图设置,安装之后,在打开View选项,就可以看到SetBackgroundImage选项了。.envfilessupp
- phpstrom连接远程服务器
努力学习的笨小孩
PHP开发工具phpstorm通过sftp和FTP远程连接服务器创建编辑远程项目PhpStorm是一个编辑PHP代码的PHP开发工具神器,应该说是目前世界上编辑PHP代码的最好用的PHP开发工具IDE了吧,本地项目的创建相信一般人都会,不过有时候我们可能项目运行在远程服务器上,比如有一种情况:在windows下使用PhpStorm编码,代码放在linux服务器上运行。还有一种情况,代码使用版本控制
- JAVA计算机毕业设计校园二手书交易系统(附源码、数据库)
卓杰计算机设计
java数据库开发语言
JAVA计算机毕业设计校园二手书交易系统(附源码、数据库)目运行环境项配置:Jdk1.8+Tomcat8.5+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:JAVA+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需要1.运行环境:最好是javajdk1
- JAVA毕设项目校园二手商品交易系统(java+VUE+Mybatis+Maven+Mysql)
贤杰程序源码
mybatisjavavue.js
JAVA毕设项目校园二手商品交易系统(java+VUE+Mybatis+Maven+Mysql)项目运行环境配置:Jdk1.8+Tomcat8.5+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:JAVA+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需
- html5 css3 JavaScript响应式中文静态网页模板js源代码
Yucool01
html5javascriptcss3
该批次模板具备如下功能:首页,二级页面,三级页面登录页面均有,页面齐全,功能齐全,js+css+html,前端HTML纯静态页面,无后台,可用dreamweaver,sublime,webstorm等工具修改;部分网页模板效果图:有需要的同学可以下载学习一下:https://download.csdn.net/download/Yucool01/22408278https://download.c
- 【python】python指南(十四):**操作符解包字典传参
LDG_AGI
Pythonpython开发语言人工智能机器学习图像处理深度学习计算机视觉
目录一、引言二、**操作符应用2.1**操作符介绍2.2**操作符案例三、总结一、引言对于算法工程师来说,语言从来都不是关键,关键是快速学习以及解决问题的能力。大学的时候参加ACM/ICPC一直使用的是C语言,实习的时候做一个算法策略后台用的是php,毕业后做策略算法开发,因为要用spark,所以写了scala,后来用基于storm开发实时策略,用的java。至于python,从日常用hive做数
- 2018-10-31
马修斯
WebStormmac下如何安装WebStorm+破解1、下载软件最好的地址就是官网了下载地址选择好系统版本以后点击DOWNLOAD下载Webstorm2、安装双击下载好的安装包、将WebStromt拖入application文件夹,然后在Launchpad中找到并打开安装.png3、等待一段时间后,WebStorm将进行第一次运行,当出现如下页面的时候第一行选择Activate,第二行选择Act
- [附源码]JAVA毕业设计基于web旅游网站的设计与实现(系统+LW)
晶涛计算机毕设
java前端旅游
[附源码]JAVA毕业设计基于web旅游网站的设计与实现(系统+LW)目运行环境项配置:Jdk1.8+Tomcat8.5+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:JAVA+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需要1.运行环境:最好是ja
- [附源码]java毕业设计基于web旅游网站的设计与实现
李会计算机程序设计
java前端旅游
项目运行环境配置:Jdk1.8+Tomcat7.0+Mysql+HBuilderX(Webstorm也行)+Eclispe(IntelliJIDEA,Eclispe,MyEclispe,Sts都支持)。项目技术:SSM+mybatis+Maven+Vue等等组成,B/S模式+Maven管理等等。环境需要1.运行环境:最好是javajdk1.8,我们在这个平台上运行的。其他版本理论上也可以。2.ID
- Module not found: Error: Can‘t resolve ‘sass-loader‘ in...
Coisini_甜柚か
web前端sassvue.jscss
"sass-loader"报错!!!Failedtocompile../src/main.jsModulenotfound:Error:Can'tresolve'sass-loader'in'E:\study_software\JetBrains\WebStorm2021\WebstormProjects\vue-element-admin-master'npminstallsass-loader
- pycharm 打开大文件代码洞察功能不可用的解决方法
weixin_44482092
intellij-ideajavaintellijidea
2019-11-13阅读1.3K0今天在使用WebStorm打开一个6.58MB的文件时,编辑器提示文件超过最大限制,代码洞察功能不可用。编辑器很多功能不可用,包括标签折叠、自动补齐、标签自动匹配等。Thefilesize(6.58MB)exceedsconfiquredlimit(2.56MB).Codeinsightfeaturesarenotavailable.其实JetBrains软件有一
- rust的指针作为函数返回值是直接传递,还是先销毁后创建?
wudixiaotie
返回值
这是我自己想到的问题,结果去知呼提问,还没等别人回答, 我自己就想到方法实验了。。
fn main() {
let mut a = 34;
println!("a's addr:{:p}", &a);
let p = &mut a;
println!("p's addr:{:p}", &a
- java编程思想 -- 数据的初始化
百合不是茶
java数据的初始化
1.使用构造器确保数据初始化
/*
*在ReckInitDemo类中创建Reck的对象
*/
public class ReckInitDemo {
public static void main(String[] args) {
//创建Reck对象
new Reck();
}
}
- [航天与宇宙]为什么发射和回收航天器有档期
comsci
地球的大气层中有一个时空屏蔽层,这个层次会不定时的出现,如果该时空屏蔽层出现,那么将导致外层空间进入的任何物体被摧毁,而从地面发射到太空的飞船也将被摧毁...
所以,航天发射和飞船回收都需要等待这个时空屏蔽层消失之后,再进行
&
- linux下批量替换文件内容
商人shang
linux替换
1、网络上现成的资料
格式: sed -i "s/查找字段/替换字段/g" `grep 查找字段 -rl 路径`
linux sed 批量替换多个文件中的字符串
sed -i "s/oldstring/newstring/g" `grep oldstring -rl yourdir`
例如:替换/home下所有文件中的www.admi
- 网页在线天气预报
oloz
天气预报
网页在线调用天气预报
<%@ page language="java" contentType="text/html; charset=utf-8"
pageEncoding="utf-8"%>
<!DOCTYPE html PUBLIC "-//W3C//DTD HTML 4.01 Transit
- SpringMVC和Struts2比较
杨白白
springMVC
1. 入口
spring mvc的入口是servlet,而struts2是filter(这里要指出,filter和servlet是不同的。以前认为filter是servlet的一种特殊),这样就导致了二者的机制不同,这里就牵涉到servlet和filter的区别了。
参见:http://blog.csdn.net/zs15932616453/article/details/8832343
2
- refuse copy, lazy girl!
小桔子
copy
妹妹坐船头啊啊啊啊!都打算一点点琢磨呢。文字编辑也写了基本功能了。。今天查资料,结果查到了人家写得完完整整的。我清楚的认识到:
1.那是我自己觉得写不出的高度
2.如果直接拿来用,很快就能解决问题
3.然后就是抄咩~~
4.肿么可以这样子,都不想写了今儿个,留着作参考吧!拒绝大抄特抄,慢慢一点点写!
- apache与php整合
aichenglong
php apache web
一 apache web服务器
1 apeche web服务器的安装
1)下载Apache web服务器
2)配置域名(如果需要使用要在DNS上注册)
3)测试安装访问http://localhost/验证是否安装成功
2 apache管理
1)service.msc进行图形化管理
2)命令管理,配
- Maven常用内置变量
AILIKES
maven
Built-in properties
${basedir} represents the directory containing pom.xml
${version} equivalent to ${project.version} (deprecated: ${pom.version})
Pom/Project properties
Al
- java的类和对象
百合不是茶
JAVA面向对象 类 对象
java中的类:
java是面向对象的语言,解决问题的核心就是将问题看成是一个类,使用类来解决
java使用 class 类名 来创建类 ,在Java中类名要求和构造方法,Java的文件名是一样的
创建一个A类:
class A{
}
java中的类:将某两个事物有联系的属性包装在一个类中,再通
- JS控制页面输入框为只读
bijian1013
JavaScript
在WEB应用开发当中,增、删除、改、查功能必不可少,为了减少以后维护的工作量,我们一般都只做一份页面,通过传入的参数控制其是新增、修改或者查看。而修改时需将待修改的信息从后台取到并显示出来,实际上就是查看的过程,唯一的区别是修改时,页面上所有的信息能修改,而查看页面上的信息不能修改。因此完全可以将其合并,但通过前端JS将查看页面的所有信息控制为只读,在信息量非常大时,就比较麻烦。
- AngularJS与服务器交互
bijian1013
JavaScriptAngularJS$http
对于AJAX应用(使用XMLHttpRequests)来说,向服务器发起请求的传统方式是:获取一个XMLHttpRequest对象的引用、发起请求、读取响应、检查状态码,最后处理服务端的响应。整个过程示例如下:
var xmlhttp = new XMLHttpRequest();
xmlhttp.onreadystatechange
- [Maven学习笔记八]Maven常用插件应用
bit1129
maven
常用插件及其用法位于:http://maven.apache.org/plugins/
1. Jetty server plugin
2. Dependency copy plugin
3. Surefire Test plugin
4. Uber jar plugin
1. Jetty Pl
- 【Hive六】Hive用户自定义函数(UDF)
bit1129
自定义函数
1. 什么是Hive UDF
Hive是基于Hadoop中的MapReduce,提供HQL查询的数据仓库。Hive是一个很开放的系统,很多内容都支持用户定制,包括:
文件格式:Text File,Sequence File
内存中的数据格式: Java Integer/String, Hadoop IntWritable/Text
用户提供的 map/reduce 脚本:不管什么
- 杀掉nginx进程后丢失nginx.pid,如何重新启动nginx
ronin47
nginx 重启 pid丢失
nginx进程被意外关闭,使用nginx -s reload重启时报如下错误:nginx: [error] open() “/var/run/nginx.pid” failed (2: No such file or directory)这是因为nginx进程被杀死后pid丢失了,下一次再开启nginx -s reload时无法启动解决办法:nginx -s reload 只是用来告诉运行中的ng
- UI设计中我们为什么需要设计动效
brotherlamp
UIui教程ui视频ui资料ui自学
随着国际大品牌苹果和谷歌的引领,最近越来越多的国内公司开始关注动效设计了,越来越多的团队已经意识到动效在产品用户体验中的重要性了,更多的UI设计师们也开始投身动效设计领域。
但是说到底,我们到底为什么需要动效设计?或者说我们到底需要什么样的动效?做动效设计也有段时间了,于是尝试用一些案例,从产品本身出发来说说我所思考的动效设计。
一、加强体验舒适度
嗯,就是让用户更加爽更加爽的用你的产品。
- Spring中JdbcDaoSupport的DataSource注入问题
bylijinnan
javaspring
参考以下两篇文章:
http://www.mkyong.com/spring/spring-jdbctemplate-jdbcdaosupport-examples/
http://stackoverflow.com/questions/4762229/spring-ldap-invoking-setter-methods-in-beans-configuration
Sprin
- 数据库连接池的工作原理
chicony
数据库连接池
随着信息技术的高速发展与广泛应用,数据库技术在信息技术领域中的位置越来越重要,尤其是网络应用和电子商务的迅速发展,都需要数据库技术支持动 态Web站点的运行,而传统的开发模式是:首先在主程序(如Servlet、Beans)中建立数据库连接;然后进行SQL操作,对数据库中的对象进行查 询、修改和删除等操作;最后断开数据库连接。使用这种开发模式,对
- java 关键字
CrazyMizzz
java
关键字是事先定义的,有特别意义的标识符,有时又叫保留字。对于保留字,用户只能按照系统规定的方式使用,不能自行定义。
Java中的关键字按功能主要可以分为以下几类:
(1)访问修饰符
public,private,protected
p
- Hive中的排序语法
daizj
排序hiveorder byDISTRIBUTE BYsort by
Hive中的排序语法 2014.06.22 ORDER BY
hive中的ORDER BY语句和关系数据库中的sql语法相似。他会对查询结果做全局排序,这意味着所有的数据会传送到一个Reduce任务上,这样会导致在大数量的情况下,花费大量时间。
与数据库中 ORDER BY 的区别在于在hive.mapred.mode = strict模式下,必须指定 limit 否则执行会报错。
- 单态设计模式
dcj3sjt126com
设计模式
单例模式(Singleton)用于为一个类生成一个唯一的对象。最常用的地方是数据库连接。 使用单例模式生成一个对象后,该对象可以被其它众多对象所使用。
<?phpclass Example{ // 保存类实例在此属性中 private static&
- svn locked
dcj3sjt126com
Lock
post-commit hook failed (exit code 1) with output:
svn: E155004: Working copy 'D:\xx\xxx' locked
svn: E200031: sqlite: attempt to write a readonly database
svn: E200031: sqlite: attempt to write a
- ARM寄存器学习
e200702084
数据结构C++cC#F#
无论是学习哪一种处理器,首先需要明确的就是这种处理器的寄存器以及工作模式。
ARM有37个寄存器,其中31个通用寄存器,6个状态寄存器。
1、不分组寄存器(R0-R7)
不分组也就是说说,在所有的处理器模式下指的都时同一物理寄存器。在异常中断造成处理器模式切换时,由于不同的处理器模式使用一个名字相同的物理寄存器,就是
- 常用编码资料
gengzg
编码
List<UserInfo> list=GetUserS.GetUserList(11);
String json=JSON.toJSONString(list);
HashMap<Object,Object> hs=new HashMap<Object, Object>();
for(int i=0;i<10;i++)
{
- 进程 vs. 线程
hongtoushizi
线程linux进程
我们介绍了多进程和多线程,这是实现多任务最常用的两种方式。现在,我们来讨论一下这两种方式的优缺点。
首先,要实现多任务,通常我们会设计Master-Worker模式,Master负责分配任务,Worker负责执行任务,因此,多任务环境下,通常是一个Master,多个Worker。
如果用多进程实现Master-Worker,主进程就是Master,其他进程就是Worker。
如果用多线程实现
- Linux定时Job:crontab -e 与 /etc/crontab 的区别
Josh_Persistence
linuxcrontab
一、linux中的crotab中的指定的时间只有5个部分:* * * * *
分别表示:分钟,小时,日,月,星期,具体说来:
第一段 代表分钟 0—59
第二段 代表小时 0—23
第三段 代表日期 1—31
第四段 代表月份 1—12
第五段 代表星期几,0代表星期日 0—6
如:
*/1 * * * * 每分钟执行一次。
*
- KMP算法详解
hm4123660
数据结构C++算法字符串KMP
字符串模式匹配我们相信大家都有遇过,然而我们也习惯用简单匹配法(即Brute-Force算法),其基本思路就是一个个逐一对比下去,这也是我们大家熟知的方法,然而这种算法的效率并不高,但利于理解。
假设主串s="ababcabcacbab",模式串为t="
- 枚举类型的单例模式
zhb8015
单例模式
E.编写一个包含单个元素的枚举类型[极推荐]。代码如下:
public enum MaYun {himself; //定义一个枚举的元素,就代表MaYun的一个实例private String anotherField;MaYun() {//MaYun诞生要做的事情//这个方法也可以去掉。将构造时候需要做的事情放在instance赋值的时候:/** himself = MaYun() {*
- Kafka+Storm+HDFS
ssydxa219
storm
cd /myhome/usr/stormbin/storm nimbus &bin/storm supervisor &bin/storm ui &Kafka+Storm+HDFS整合实践kafka_2.9.2-0.8.1.1.tgzapache-storm-0.9.2-incubating.tar.gzKafka安装配置我们使用3台机器搭建Kafk
- Java获取本地服务器的IP
中华好儿孙
javaWeb获取服务器ip地址
System.out.println("getRequestURL:"+request.getRequestURL());
System.out.println("getLocalAddr:"+request.getLocalAddr());
System.out.println("getLocalPort:&quo
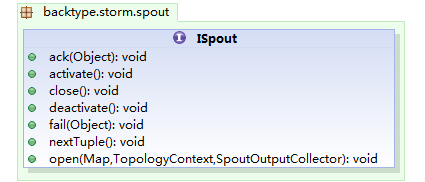
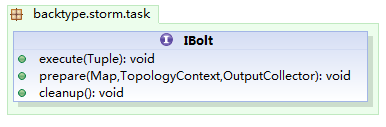
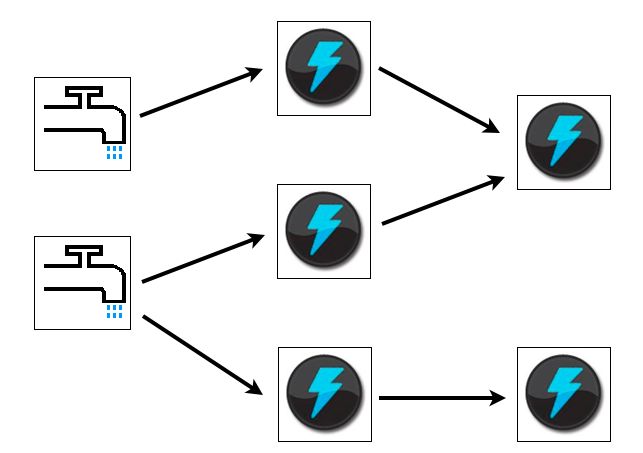 以上是官方网站上提供的图示,storm的处理模型有点类似自来水。水龙头的部分是数据产生器(spout),中间流经的各个节点(bolt)对数据进行分阶段处理。这个模型有点类似以前接触过的过滤器(filter),但是由于各个spout或bolt都是分布式的,相应的复杂性也就不可同日而语了。这里先简单的介绍一下spout和bolt,作为这个系列的开头。
以上是官方网站上提供的图示,storm的处理模型有点类似自来水。水龙头的部分是数据产生器(spout),中间流经的各个节点(bolt)对数据进行分阶段处理。这个模型有点类似以前接触过的过滤器(filter),但是由于各个spout或bolt都是分布式的,相应的复杂性也就不可同日而语了。这里先简单的介绍一下spout和bolt,作为这个系列的开头。