深度学习pytorch基础
pytorch是facebook在深度学习框架torch基础上使用python重写的深度学习框架
安装pytorch便捷方法是登录官网(https://pytorch.org/get-started/locally/)选择匹配的版本进行下载
1. pytorch中的tensor
tensor意为张量,即区别于标量的多维数据
1.1 tensor的数据类型
和numpy差不多,tensor中的数据类型有自己的定义方式
1.1.1 torch.FloatTensor
生成数据为浮点型的tensor,参数可以是一个列表,也可以是一个维度值
import torch
a=torch.FloatTensor(2,3)
print(a)
b=torch.FloatTensor([1,2,3,4])
print(b)
输出如下

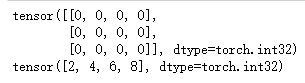
1.1.2 torch.IntTensor
生成整形张量,同理于floattensor
a=torch.IntTensor(3,4)
print(a)
b=torch.IntTensor([2,4,6,8])
print(b)
输出如下:
1.1.3 torch.rand
生成数据为浮点型指定维度的随机tensor,在0~1之间均匀分布
a=torch.rand(2,3)
print(a)
![]()
1.1.4 torch.randn
生成浮点型指定维度的tensor,满足均值为0,方差为1的正态分布
1.1.5 arange
开始用的是range,不过在版本升级之后官方改成了arange
生成浮点型且指定首尾范围的tensor,参数有三个,分别是起始范围值,结束范围值,步长
a=torch.arange(1,20,2)
print(a)
1.1.6 torch.zeros
生成浮点类型指定维度的全0tensor
a=torch.zeros(3,5)
print(a)
1.2 tensor的运算
- abs:返回输出参数tensor的绝对值
- add:返回输入参数的求和结果,可以对tensor间求和,也可以对tensor和标量求和(各对应元素相加)
- clamp:对参数变量按照自定义范围进行裁剪,有三个参数,分别是待操作的tensor变量,裁剪上边界,裁剪下边界,具体的裁剪过程是:对于每个元素x,假定裁剪上边界a,下边界为b,x
- div:求商,同add,可以是tenso之间或者tensor与标量(各对应元素相除)
- mul:求积,同div
- pow:求幂,同div
- mm:矩阵乘法
- mv:矩阵与向量乘法,第一个参数是矩阵,第二个参数必须是与矩阵列数相等的一维向量
a=torch.randn(2,3)
print("a\n",a)
print("a的绝对值: \n",torch.abs(a))
b=torch.randn(2,3)
print("b\n",b)
print("a+b: \n",torch.add(a,b))
print("a+1:\n",torch.add(a,1))
print("clamp裁剪:\n",torch.clamp(a,0.5,-0.5))
print("a/b\n",torch.div(a,b))
print("a/2\n",torch.div(a,2))
print("a*b\n",torch.mul(a,b))
print("a*10\n",torch.mul(a,10))
print("a**b\n",torch.pow(a,b))
print("a**2\n",torch.pow(a,2))
a=torch.ones(2,3)
print("a\n",a)
b=torch.ones(3,2)
print("b\n",b)
print("aXb\n",torch.mm(a,b))
c=torch.ones(3)
print("c\n",c)
print("a·c\n",torch.mv(a,c))
输出如下:

1.3 搭建一个简易神经网络
import torch
batch_n=100
hidden_layer =100
input_data=1000
output_data=10
首先导入包,然后声明四个整型变量,batchn表示输入数据的数量,hiddenlayer表示经过隐藏层保留的数据特征个数,inputdate表示输入数据的数据特征个数,outputdata就表示输出数据的数据特征个数
这里赋值之后的含义就变成输入的数据是100条,每条数据有1000特征,经过隐藏层之后变成了100个特征,最后输出时变成10个特征,这10个特征就可以看成是输出结果属于十个类别的可能性
x=torch.randn(batch_n,input_data)
y=torch.randn(batch_n,output_data)
w1=torch.randn(input_data,hidden_layer)
w2=torch.randn(hidden_layer,output_data)
因为没有引入真正的样本数据,所以我们随机生成满足维度要求的输入输出张量x,y,也随机初始化w1和w2两层神经网络,可以把数据经过网络看成是矩阵的乘法运算,这样就可以掌握参数维度的定义
epoch_n=20
learning_rate=1e-6
这里定义了循环次数和学习速率,循环次数就是我们要用这两层网络反复处理多少遍数据,学习速率就是改变梯度相关参数时的幅度,学习速率大,参数就改变的剧烈,结果也改变的剧烈,学习速率小改变的幅度小,可以逐渐接近期望值,不会刹不住车
for each in range(epoch_n):
h1=x.mm(w1)
h1=h1.clamp(min=0)
y_pred=h1.mm(w2)
loss=(y_pred-y).pow(2).sum()
print("Epoch:{},Loss:{:.4f}".format(each,loss))
grad_y_pred=2*(y_pred-y)
grad_w2=h1.t().mm(grad_y_pred)
grad_h=grad_y_pred.clone()
grad_h=grad_h.mm(w2.t())
grad_h.clamp(min=0)
grad_w1=x.t().mm(grad_h)
w1 -= learning_rate*grad_w1
w2 -= learning_rate*grad_w2
这各循环就是神经网络的核心,首先根据指定的循环次数epoch进行循环,在每层循环中,首先将输入数据x(100,1000)和第一层网络w1(1000,100)相乘,此时h1变成(100,100),随后使用裁剪函数,过滤掉小于零的值,这就是常见的Relu激活方法,随后h1(100,100)再次乘w2(100,10),获得的预测结果ypred就是满足输出要求的(100,10),这个结果是我们第一轮预测的结果,随后我们要与期望结果y进行比较,来确定误差,比较的方法就是求标准差,二者差值的平方和,得到损失函数loss,然后使用format在每次循环都输出loss,通过loss的大小可以直观判断预测结果距离期望结果的误差大小,随后就是根据梯度的反向传播,更新参数网络w1,w2的过程,再重复执行20次循环后,我们可以从输出结果直观看出loss逐渐变小,预测结果在逐渐接近期望值,这就是神经网络的基本过程