(Python爬虫/自然语言处理)BeautifulSoup+webdriver爬电视剧文本数据并统计Tfidf以进行相似度处理和文本聚类
近来很闲,在优酷爬个2019年内地剧的简介,然后给宝贝女友做个简陋的电视剧推荐。
在python准备好需要用到的包,大概是
import re
import time
import requests
from bs4 import BeautifulSoup
import numpy as np
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import jieba
from sklearn.feature_extraction.text import TfidfTransformer, CountVectorizer
from sklearn.cluster import KMeans
import matplotlib.pyplot as plt
from sklearn.metrics.pairwise import cosine_similarity
from sklearn.decomposition import PCA
首先在优酷筛选好条件然后导出地址:https://list.youku.com/category/show/c_97_s_1_d_1_a_%E4%B8%AD%E5%9B%BD_r_2019.html?spm=a2ha1.12701310.app.55!25!255DL!4DD~A!2
然后发现个问题就是优酷这个网页只有使用鼠标下拉至最底部才能展示出或者在网页代码上展示出完整的电视剧信息,所以直接使用requests.get()方法是爬不出完整的信息,所以引用个web-driver控件,我的话用Chrome web-driver,在网上下载和自己chrome对应版本的chrome webdriver,然后在python执行,打开这个网页并把它拉到最底部
url = 'https://list.youku.com/category/show/c_97_s_1_d_1_a_%E4%B8%AD%E5%9B%BD_r_2019.html?spm=a2ha1.12701310.app.5~5!2~5!2~5~5~DL!4~DD~A!2'
driver = webdriver.Chrome(executable_path="C:\Program Files (x86)\Google\Chrome\Application\chromedriver.exe")#打开浏览器
driver.get(url)#打开你的访问地址
driver.maximize_window()#将页面最大化
driver.refresh()
js="var q=document.documentElement.scrollTop=100000"
for i in range(10):#下拉10次,每次间隔1秒钟
driver.execute_script(js)
time.sleep(1)
这样网页就能显示所有的电视剧信息了,接着就要导出源代码,利用正则表达式过滤出每部剧的链接,得到每一部剧的链接后,发现点进去就是视频播放界面,电视剧的简介在这个界面里面的一个超链接里,那么需要点进这个链接才能得到另一个有电视剧简介的界面,所以一共需要获取2次url地址
#利用刚才的自动浏览器显示网页源,过滤信息得到对应电视剧链接
ele = driver.page_source
list_url = re.findall(r'categorypack_pack_cover">, ele)
for i in range(len(list_url)):
list_url[i] = 'https:' + list_url[i]
#上面得到的链接是视频链接,电视剧的剧情简介和信息在里面的另一个链接里,因此再收集一次链接
list_url2 = []
for k in list_url:
try:
res = requests.get(k)
soup = BeautifulSoup(res.text,'html.parser')
for i in soup.select('.tvinfo h2 a'):
list_url2.append('https:' + i['href'])
except:
pass
#收集简介和剧名
name = []
text=[]
for i in list_url2:
try:
res = requests.get(i)
soup = BeautifulSoup(res.text,'html.parser')
text.append(str(soup.select('.intro-more.hide')[0])[33:-7])
name.append(re.findall(r':(.*?)', str(soup.select('.p-row.p-title')[0])))
except:
pass
收集完剧名和简介之后,把文本删除停用词比如标点符号,还有一些语气词‘吗,哟’之类的,在网上搜中文停用词就能搜到一个文档出来。删除停用词之后,进行jieba分词
#import jieba
#载入中文停词表
path = 'C://Users/trium/Documents/Python Learning/NLP/stopped words.txt'
with open(path, 'r', encoding='utf8') as f:
stopped_words = f.read().split()
'''jieba分词, 并删除text里面的停用词'''
new_text = []
for i in text:
sep = " ".join(jieba.cut(i, cut_all=False)).split(' ')
new_temp = []
for k in sep:
if k not in stopped_words:
new_temp.append(k)
new_text.append(' '.join(new_temp))
过滤之后的文本可以进行tfidf处理了,导入sklearn的CountVectorizer(),将文本中的词语转换为词频矩阵,再使用TfidfTransformer()统计每个词的tfidf,最后将其转化为数组类型
#from sklearn.feature_extraction.text import TfidfTransformer, CountVectorizer
vectorizer=CountVectorizer()#该类会将文本中的词语转换为词频矩阵,矩阵元素a[i][j] 表示j词在i类文本下的词频
transformer=TfidfTransformer()#该类会统计每个词语的tf-idf权值
tfidf=transformer.fit_transform(vectorizer.fit_transform(new_text))#第一个fit_transform是计算tf-idf,第二个fit_transform是将文本转为词频矩阵
word=vectorizer.get_feature_names()#获取词袋模型中的所有词语
weight=tfidf.toarray()#将tf-idf矩阵抽取出来,元素a[i][j]表示j词在i类文本中的tf-idf权重
根据这个数组,可以计算电视剧之间的相似度,也可以进行电视剧的一个聚类。相似度的计算这里使用余弦相似度cosine similarity,在已知各电视剧的相似度后,可以进行一个简单的电视剧推荐(即基于电视剧相似度的推荐)
#from sklearn.metrics.pairwise import cosine_similarity
cosine = cosine_similarity(weight)
movie_name = [name[i][0] for i in range(len(name))]#转为一维list
#创建函数,功能:导入电视剧名/导出最类似的电视剧名
def recommend(original_movie, movie_name_list, similarity_matrix, number):
if original_movie not in movie_name_list:
print('这部剧不在列表上!')
return '推荐结果:空集'
elif number > len(movie_name):
print('推荐电视剧数量超过电视剧列表,请缩小推荐数量!')
return '推荐结果:空集'
else:
movie_index = movie_name.index(original_movie)
movie_similarity = similarity_matrix[:,movie_index]
sort_index = np.argsort(-movie_similarity)#相似度降序返回原先的movie index
recommend_movie_index = sort_index[1:number+1].tolist()#最高相似度的一定是它本身,所以不需要
recommend_movie_name = [movie_name_list[i] for i in recommend_movie_index]
return recommend_movie_name
#推荐3部与'大明风华 TV版'相似的电视剧
print(recommend(original_movie='大明风华 TV版', movie_name_list=movie_name, similarity_matrix=cosine, number=3))
那么结果就打印出来:
[‘独孤皇后’, ‘穿越时空的爱恋 短剧版’, ‘在桃花盛开的地方’]
此外,也可以利用tfidf进行文本聚类。由于一共有5千多个词语在我们的数据里面,所以数据的特征数会非常大,因此需要进行一个降维,考虑到这是一个无监督的数据处理,也就使用了PCA进行降维,为了方便可视化,就把数据降到2维,虽然会损失准确率。考虑到这是tfidf的矩阵,这里不需要做标准化处理。
#from sklearn.decomposition import PCA
pca = PCA(n_components=2)
X_r = pca.fit(weight).transform(weight)
降维后,由于对数据数值不了解,所以直接就使用Kmeans算法进行聚类,在聚类前先计算各K值的SSE,并可视化。
#from sklearn.cluster import KMeans
#查看各K值SSE
SSE = [] # 存放每次结果的误差平方和
for k in range(1,31):
pre_clustering = KMeans(n_clusters=k) # 构造聚类器
pre_clustering.fit(X_r)
SSE.append(pre_clustering.inertia_)
K = range(1,31)
plt.xlabel('k')
plt.ylabel('SSE')
plt.plot(K,SSE,'o-')
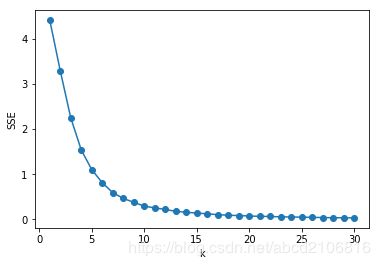
选K=5进行聚类,最后得到各类的结果和标签,并可视化聚类结果
#根据SSE图把电视剧分为5类
clustering = KMeans(n_clusters=5, random_state=0)
clustering.fit(X_r)
clustering_label = clustering.labels_
#Visulize the clustering result
for i in range(len(X_r)):
if int(clustering_label[i]) == 0:
plt.scatter(X_r[i][0], X_r[i][1], color='red')
if int(clustering_label[i]) == 1:
plt.scatter(X_r[i][0], X_r[i][1], color='black')
if int(clustering_label[i]) == 2:
plt.scatter(X_r[i][0], X_r[i][1], color='blue')
if int(clustering_label[i]) == 3:
plt.scatter(X_r[i][0], X_r[i][1], color='yellow')
if int(clustering_label[i]) == 4:
plt.scatter(X_r[i][0], X_r[i][1], color='green')
name_array = np.reshape(np.array(name), (-1,1))
name_label = np.insert(name_array, 1, values=clustering_label, axis=1)
cluster_result = []
for i in range(clustering_label.max()+1):
temp_list = []
for k in range(name_label.shape[0]):
if int(name_label[k,1]) == i:
temp_list.append(str(name_label[k,0]))
cluster_result.append(temp_list)
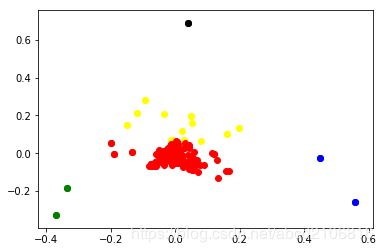
结果是强行要求女朋友去看然后她就看上瘾了,我解放了一段时间