机器学习方法之非线性回归( Logistic Regression)
非线性回归是线性回归的延伸,其目标预测函数不是线性的。本文主要介绍逻辑回归(Logistic Regression),它是非线性回归的一种,虽然名字中有“回归”二字,但其本质上是一个分类模型。
含义
我们知道,线性回归的模型是求出输出特征向量Y和输入样本矩阵X之间的线性关系系数θ,满足 Y = X θ Y=Xθ Y=Xθ。此时Y是连续的,所以是回归模型。如果Y是离散的话,如何解决?一个可以想到的办法是,我们对于Y再做一次函数转换,变为g(Y)。如果我们令g(Y)的值在某个实数区间的时候是类别A,在另一个实数区间的时候是类别B,以此类推,就得到了一个分类模型。如果结果的类别只有两种,那么就是一个二元分类模型了。逻辑回归的出发点就是从这来的。
看如下实例
有这么几组医疗数据,X特征是肿瘤的大小(连续型),Y是其良恶性(离散型),Y只有0(良性)和1(恶性)2种取值。
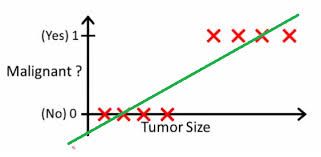
我们选取阈值0.5,h(x)>0.5(恶性),Malignant=1,反之为0,良性。
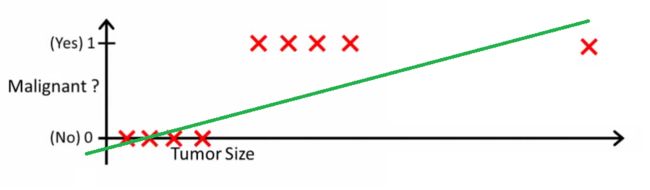
我们选取阈值0.2,h(x)>0.2(恶性),Malignant=1,反之为0,良性。
比较上述两种情况,新的数值加入时需要不断调整阈值,说明用线性的方法进行回归不太合理。
基本模型
我们假设测试数据为 X ( x 0 , x 1 , . . . , x n ) X(x_0,x_1,...,x_n) X(x0,x1,...,xn)
需要学习的参数为 Θ ( θ 0 , θ 1 , . . . , θ n ) \Theta(\theta_0,\theta_1,...,\theta_n) Θ(θ0,θ1,...,θn)
给定函数
Z = θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n Z = \theta_0 + \theta_1x_1 + \theta_2x_2+...+\theta_nx_n Z=θ0+θ1x1+θ2x2+...+θnxn
向量化可表示为
Z = Θ T X Z = \Theta^TX Z=ΘTX
经常需要一个分界线作为区分两类结果。再次需要一个函数进行曲线平滑化,由此引入Sigmoid 函数进行转化:
g ( z ) = 1 1 + e − z g(z) = \frac{1}{1+e^{-z}} g(z)=1+e−z1
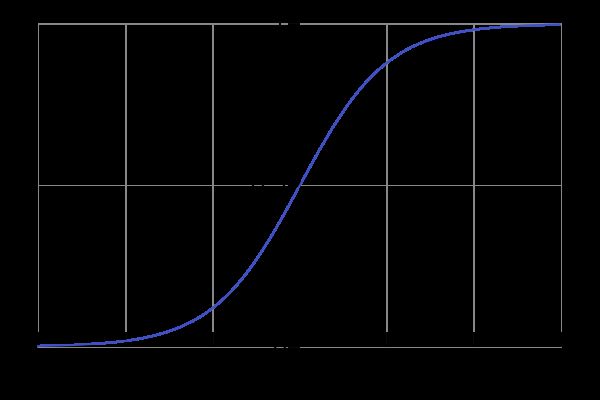
这样的,可以以 0.5 作为分界线。因此逻辑回归的最终目标函数就是:
h θ ( X ) = g ( θ 0 + θ 1 x 1 + θ 2 x 2 + . . . + θ n x n ) = g ( θ T X ) = 1 1 + e − θ T X h_\theta(X) = g(\theta_0 + \theta_1x_1 + \theta_2x_2+...+\theta_nx_n) = g(\theta^TX) = \frac{1}{1+e^{-\theta^TX}} hθ(X)=g(θ0+θ1x1+θ2x2+...+θnxn)=g(θTX)=1+e−θTX1
回归是用来得到样本属于某个分类的概率。因此在分类结果中,假设 y 值是 0 或 1,那么正例 (y = 1):
h θ ( X ) = P ( y = 1 ∣ X ; θ ) h_\theta(X) = P(y=1|X;\theta) hθ(X)=P(y=1∣X;θ)
反例(y = 0):
1 − h θ ( X ) = P ( y = 0 ∣ X ; θ ) 1 - h_\theta(X) = P(y=0|X;\theta) 1−hθ(X)=P(y=0∣X;θ)
在线性回归中,我们要找到合适的 θ ( i ) \theta^{(i)} θ(i)使下面的损失函数值最小:
C o s t ( h θ ( x ( i ) ) , y ( i ) ) = ∑ i = 1 m ( h θ ( x ( i ) ) − y ( i ) ) 2 Cost(h_\theta(x^{(i)}),y^{(i)}) = \sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{(i)})^2 Cost(hθ(x(i)),y(i))=i=1∑m(hθ(x(i))−y(i))2
如果在逻辑回归中运用上面这种损失函数,得到的函数 J 是一个非凸函数,存在多个局部最小值,很难进行求解,因此需要换一个 cost 函数。重新定义个 cost 函数如下:
C o s t ( h θ ( x ( i ) ) , y ( i ) ) = − 1 m [ ∑ i = 1 m ( y ( i ) l o g ( h θ ( x ( i ) ) ) + ( 1 − y ( i ) ) l o g ( 1 − h θ ( x ( i ) ) ) ) ] Cost(h_\theta(x^{(i)}),y^{(i)}) = -\frac{1}{m}[\sum_{i=1}^{m}(y^{(i)}log(h_\theta(x^{(i)})) + (1-y^{(i)})log(1-h_\theta(x^{(i)})))] Cost(hθ(x(i)),y(i))=−m1[i=1∑m(y(i)log(hθ(x(i)))+(1−y(i))log(1−hθ(x(i))))]
求解方法
我们采用梯度下降法求解最佳解。梯度下降法的计算过程就是沿梯度下降的方向求解极小值。
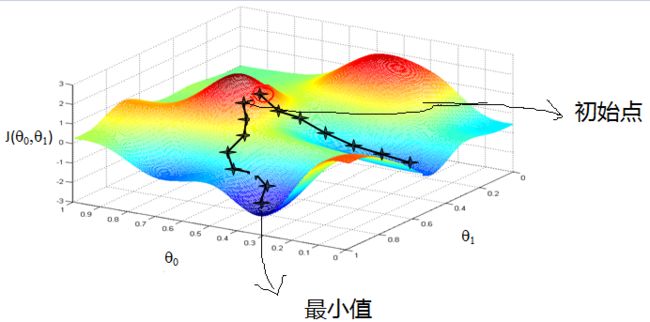
- 先确定向下一步的步幅大小,称之为
Learning rate; - 任意给定一个初始值: θ 0 , θ 1 , . . . , θ n \theta_0,\theta_1,...,\theta_n θ0,θ1,...,θn;
- 确定一个向下的方向,并向下走预先规定的步伐,并更新 θ 0 , θ 1 , . . . , θ n \theta_0,\theta_1,...,\theta_n θ0,θ1,...,θn;
- 当下降的高度小于某个定义的阈值时,停止下降更新。
这就好比是下山,下一步的方向选的是最陡的方向。梯度下降不一定能够找到全局的最优解,有可能是一个局部最优解。当然,如果损失函数是凸函数,梯度下降法得到的解就一定是全局最优解。θ 的更新方程如下:
θ j = θ j − α ∂ ∂ θ j J ( θ ) \theta_j = \theta_j - \alpha\frac{\partial}{\partial\theta_j}J(\theta) θj=θj−α∂θj∂J(θ)
其中,偏导是:
∂ ∂ θ j J ( θ ) = 1 m ∑ i = 1 m ( h ( x ( i ) ) − y ( i ) ) x j ( i ) \frac{\partial}{\partial\theta_j}J(\theta) = \frac{1}{m}\sum_{i=1}^{m}(h(x^{(i)})-y^{(i)})x_j^{(i)} ∂θj∂J(θ)=m1i=1∑m(h(x(i))−y(i))xj(i)
代码实例
本部分我们将采用2种方式实现逻辑回归模型,一种自己编写函数方法,一种调用sklearn中的方法库(LogisticRegression)。
自己实现
import numpy as np
import random
import matplotlib.pyplot as plt
#sigmod函数,将值量化到0-1
def sigmoid(x):
return 1.0 / (1 + np.exp(-x))
# 梯度下降算法
def gradientDescent(x, y, theta, alpha, m, numIteration):
'''
:param x: 输入实例
:param y: 分类标签
:param theta: 学习的参数
:param alpha: 学习率
:param m: 实例个数
:param numIteration: 迭代次数
:return: 学习擦参数theta
'''
xTrans = x.transpose() # 矩阵的转置
J = [] # 存储损失的列表,方便绘图
for i in range(0, numIteration):
hypothsis = sigmoid(np.dot(x, theta)) #量化到0-1
loss = hypothsis - y #计算误差
cost = np.sum(loss ** 2) / (2 * m) #计算损失
J.append(cost) # 将损失存入列表
print("Iteration %d / Cost:%f" % (i, cost))
gradient = np.dot(xTrans, loss) / m
theta = theta - alpha * gradient # 更新梯度
plt.plot(J) # 可视化损失变化
plt.show()
return theta
# 创建数据,用作测试
def genData(numPoints, bais, variance):
'''
:param numPoints: 输入实例数目
:param bais: 偏向
:param variance: 方差
:return 创建的数据 x,y
'''
# 实例(行数)、偏向、方差
x = np.zeros(shape=(numPoints, 2)) # 初始化numPoints行2列(x1,x2)的全零元素矩阵
y = np.zeros(shape=numPoints) # 归类标签
y_list = [0,1] # 标签列表y的取值
for i in range(0, numPoints):
x[i][0] = random.uniform(0, 1) * variance # 创建X的特征对
x[i][1] = (i + bais) + random.uniform(0, 1) * variance
random.shuffle(y_list) # 给X特征对附上随机的0 1 标签
y[i] =y_list[0]
return x, y
x, y = genData(100, 2, 5)
#print(x)
#print(y)
#x和y的维度
m, n = np.shape(x)
n_y = np.shape(y)
numIteration = 100000
alpha = 0.0005
theta = np.ones(n) # 初始化theta
theta = gradientDescent(x, y, theta, alpha, m, numIteration)
print(theta) #output [-0.14718538 0.00381781]
Sklearn实现
from sklearn.linear_model import LogisticRegression
# 调用sklearn自带的逻辑回归方法
sk = LogisticRegression(max_iter=100000)
sk.fit(x, y) # 此处的x和y与上面自己实现的一致
print(sk.intercept_)
print(sk.coef_) #output [-0.11612453 0.00272452]
我们发现自己闪现求解的 θ \theta θ值与sklearn中的相比,还是存在一定误差的,这是因为sklearn中的方法 LogisticRegression有很多参数进行了详细的优化,详情参见https://scikit-learn.org/stable/modules/generated/sklearn.linear_model.LogisticRegression.html#sklearn-linear-model-logisticregression
Cost损失可视化
模型优缺点
优点:
- 适合需要得到一个分类概率的场景
- 计算代价不高,容易理解实现。LR在时间和内存需求上相当高效
- LR对于数据中小噪声的鲁棒性很好
缺点:
- 容易欠拟合,分类精度不高
- 对异常值敏感