偶像剪辑,一键获取:多模态联合建模的视频人物摘要

「论文访谈间」是由 PaperWeekly 和中国中文信息学会社会媒体处理专委会(SMP)联合发起的论文报道栏目,旨在让国内优质论文得到更多关注和认可。


社交媒体的兴起推动了“二次创作”的流行。其中,旨在对原始视频进行浓缩,以关键帧或者高亮片段的形式涵盖原始视频的视频摘要成为重要形式之一。而在视频摘要之中,面向特定人物的“视频人物摘要”,即从指定的影视视频中剪辑特定人物出场片段所组成的摘要,受到了广泛的关注和应用。例如,某位明星的影迷们经常将明星出场的片段单独剪辑作为收藏。事实上,视频服务商们也已开始提供类似的功能,如腾讯视频的“只看 TA”功能等。
然而,目前面向“视频人物摘要”的二次创作仍以人工实现为主。其原因之一在于现有技术难以有效适应这一应用场景。例如,传统的人物重识别技术在面向特定场景,如稳定的背景、固定的衣着和姿态等条件下的人物捕捉有着较好的效果,但对于影视场景中多变的角度、姿态、衣着等情况下乏善可陈。与此同时,社交媒体中所富含的其他模态信息,尤其是由大众所创造的众包文本信息(如弹幕)往往难以与现有技术实现有效结合。
针对以上问题,本文引入了一个新的框架用于自动生成视频人物摘要,并通过文本与视觉的模态融合来增强摘要的质量。该任务可以定义为:给定包含多模态信息的原始视频以及目标人物,目的是从原始视频中自动抽取出包含目标人物的摘要视频。
接下来介绍本文中视频人物摘要框架的主要结构,如图 1 所示,本摘要框架由人物检测模块,人物重识别模块和关键帧聚合模块组成:

▲ 图1. 视频人物摘要的整体框架
人物检测模块(Person Detection)的主要作用是无差别地检测出视频中出现的所有人物,这部分主要是对 R-cnn 系列的 detector 进行微调——我们使用基于 ResNet-50 初始化的 Cascade R-CNN 构建一个简单的二分类器(是否包含人),从而逐帧地预测人物出现的区域(Regions of Interest, RoI),人物检测模块可以看做是对视频流数据所进行的预处理。
人物重识别模块(Person Re-identification)的主要作用是在人物检测模块的基础上,判断每一个候选的人物出现区域是否包含了目标人物c。具体来说,模型的输入为一对 <目标查询 q,候选 g>,我们先是对候选 g 包含的人物区域以及附近的文本信息进行特征抽取,得到候选 g 的多模态特征,继而参考 Y.Shen et al. (2018) 中的张量积匹配方法,以度量学习的思路,计算候选 g 与目标查询 q 之间的相似度。模型的输出为一个二元数组,判断目标对象和候选对象是否属于同一个人物,[1,0] 代表是,[0,1] 代表否。

▲ 图2. 多模态重识别模型
在视觉与文本特征的融合过程中,一个重要的问题就是文本中普遍存在的高噪声会对特征融合产生负面影响。针对文本信息如何降噪的问题,本文结合视觉 context,先是通过注意力机制进行 document-level 的降噪。
如图 2 所示,我们认为相近时间内的文本更可能表达相似的语义和构成对人物的相似的描述,所以我们把时间窗口内的文本划分为 k 个段落的集合,并通过 Char-LSTM 或 Neural Topic Model 得到初始的文本特征矩阵 ![]() ,文本特征矩阵的每一行都对应一个段落内的文本的联合表征向量,其中 r 表示文本的联合表征向量的维度。同时,不同段落的文本描述与人物的相关性可能各有不同,所以我们通过一个注意力机制来计算每个段落的文本向量
,文本特征矩阵的每一行都对应一个段落内的文本的联合表征向量,其中 r 表示文本的联合表征向量的维度。同时,不同段落的文本描述与人物的相关性可能各有不同,所以我们通过一个注意力机制来计算每个段落的文本向量 ![]() 的重要性得分
的重要性得分 ![]() :
:

其中 Vis 表示模型主干的顶层特征图通过全局池化和全连接层后压缩得到的语义向量,之所以选择使用顶层的特征图作语义向量的映射,是因为在卷机网络中,越顶层特征图往往越能表达越抽象的语义信息。我们根据重要性更新每个段落的语义向量:

继而我们又考虑到弹幕评论作为一类主观性很强的文本,与作为客观描述的字幕文本在适用场景上迥异,所以根据情境选择合适的文本类型将是很重要的,我们通过文本源选择机制对合适的文本源(字幕 or 弹幕文本)进行筛选。
如图 3 所示,我们拼接目标查询 q 和候选 g 的顶层的视觉特征图,得到一个联合的特征图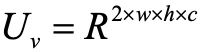 ,其中 w,h,c 分别代表特征图的宽,高和通道数量,将 Uv 经过全局池化层,2 x 2 的池化层(步长为 2),全连接层和 sigmoid 非线性函数后,最终就得到了文本源选择向量
,其中 w,h,c 分别代表特征图的宽,高和通道数量,将 Uv 经过全局池化层,2 x 2 的池化层(步长为 2),全连接层和 sigmoid 非线性函数后,最终就得到了文本源选择向量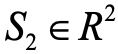 。
。
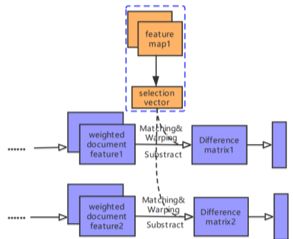
▲ 图3:文本源选择机制
关键帧聚合模块(Key-frame Aggregation)的主要作用是根据重识别模块判断的存在目标人物的关键帧,通过基于时序关联性的启发式方法,将零散的关键帧聚合为流畅的视频片段,最后形成面向目标人物的视频摘要。
实验部分,本文收集了 bilibili 视频网站上的视频数据,共包含 167 个长视频(包含 32 部动漫,19 部电影),以及相应的字幕和弹幕文本。并分别在动漫和电影数据集上做了评估:
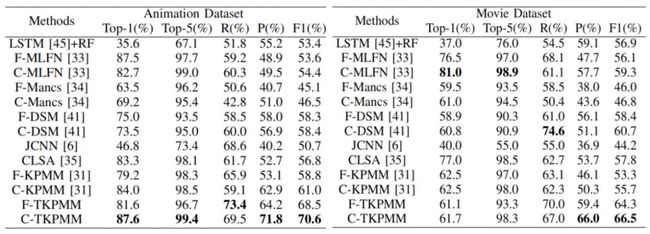
▲ 表1:人物搜索(Person Search)效果对比
可以看到文本信息的引入对于搜索精度有较大的提升,在多数指标上都取得了最好的效果。本文同时也针对摘要结果进行了主观的评估(一致性 3 分,显著性 2 分),模型在动漫和电影数据集上相较于基础模型也分别取得了 0.22 和 0.09 的提升,本文还通过一些直观的案例来展示模型效果:

▲ 图4. 文本描述为人物身份识别提供有益线
最后,我们通过考察高权重的文本主题分布,归纳了文本主题在视频人物搜索任务上的规律,如表 2 所示,通过统计分析,我们发现包含身份/昵称和外观描述的文本信息在该任务上更受青睐也更有价值:

▲ 表2. 高权重文本信息的主题分布
作者有话说
我们的创新之处在于,将文本信息使用到视频人物搜索和摘要过程中,通过降噪后的文本信息来为人物身份识别提供新的线索,并设计了能够进行自动人物摘要的整体流程。实验结果也表明,通过该方法得到的摘要框架具有更高的搜索精度和摘要质量。
我们的后续工作将主要着眼于更进一步的视频理解,我们将在视频人物检索的基础上,通过人物的共现(co-occurrence),在多模态的 context 下进行人物关系的理解。
此外,在人物检索和摘要问题上,如何利用更丰富的多模态信息(诸如音频特征,人脸特征),如何对不同模态进行降噪和有效的融合,如何细致地处理 detection 和 re-identification 之间的误差传递问题,如何提升搜索效率等等,都是可以思考的角度,也对应着很大的提升空间。
相关论文
Peilun Zhou, Tong Xu, Zhizhuo Yin, Dong Liu, Enhong Chen, Guangyi Lv, Changliang Li, Character-oriented Video Summarization with Visual and Textual Cues, IEEE Transactions on Multimedia, 2019
关于作者

周培伦,中国科学技术大学硕士研究生。 于 2017 年获得中国科学技术大学学士学位。目前于安徽省大数据分析与应用重点实验室攻读硕士学位。主要研究方向包括多模态学习,计算机视觉与自然语言处理。

徐童,中国科学技术大学副研究员。 于 2016 年获得中国科学技术大学博士学位。现为中国中文信息学会青年工作委员会委员、中文信息学会社会媒体处理专委会通讯委员。主要研究方向为社交网络与社交媒体分析,近年来,在相关领域国际重要期刊及会议发表论文近 50 篇。

尹智卓,中国科学技术大学本科生。 于 2019 年获得中国科学技术大学学士学位。主要兴趣方向是计算机视觉与高性能计算。

刘东,中国科学技术大学副教授。 于 2004 年和 2009 年分别获得中国科学技术大学学士和博士学位。以作者身份发表国际会议与期刊论文逾百篇,研究内容主要包括图像与视频编码,多媒体信号处理和多媒体数据挖掘等。曾获 2009 年 TCSVT 最佳论文奖。

陈恩红,中国科学技术大学教授、大数据学院执行院长。 主要研究内容包括数据挖掘,机器学习,社交网络分析与推荐系统,在相关领域发表国际会议与期刊论文两百余篇。包括Nature Communications, IEEE/ACM Transactions, KDD, NIPS, IJCAI and AAAI 等。担任 KDD, ICDM, 和 SDM 等国际学术会议程序委员会委员。曾获 KDD’2008最佳应用论文奖,ICDM’2011 最佳研究论文奖和 SDM’2015 最佳论文奖。

吕广奕,中国科学技术大学博士。 于2013年和2019年分别获得中国科学技术大学学士和博士学位。研究内容主要包括深度学习,自然语言处理和推荐系统。

李长亮,金山公司AI Lab负责人。 于2015年获得中国科学研究院自动化所博士学位。研究内容主要包括深度学习,自然语言处理和数据挖掘。曾在EMNLP, IJCNN, PAKDD, NLPCC等顶级国际会议上发表多篇论文。
主办单位



点击以下标题查看更多往期内容:
巧用文本语境信息:基于上下文感知的向量优化
雇水军刷分有效吗?虚假评论的影响研究分析
基于深度强化学习的谣言早期检测模型
KDD 2019 | 使用神经网络为A*搜索算法赋能
让陌生人说出你的兴趣:基于深度学习的推荐模型
基于双层注意力机制的异质图深度神经网络
坚守还是离开?初期城市移民流失预测问题分析
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。
▽ 点击 | 阅读原文 | 下载论文