面试问题:
1)什么场景,应该用什么分区策略?
2)怎么选择分区字段和相关算法?
3)怎么解决不均匀和扩容问题?
跨磁盘分散查询,更大查询吞吐量。
如SUM()和COUNT()聚合函数查询,容易并行处理。 “SELECT salesperson_id, COUNT (orders) as order_total FROM sales GROUP BY salesperson_id;”。查询可在每个分区上同时进行,总计所有分区得结果。
分区类型:RANGE、LIST、HASH、KEY
一、RANGE分区
基于属于一个给定连续区间列值,多行分配给分区。
区间要连续且不重叠,用VALUES LESS THAN操作符定义。实例:

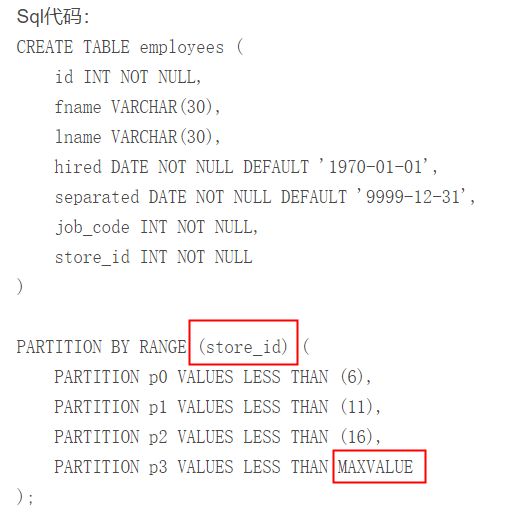
1到5雇员P0中,6到10在P1中,PARTITION BY RANGE 语法要求;按顺序定义,从低到高。(72, ‘Michael’, ‘Widenius’, ’1998-06-25′, NULL, 13)新行插入到p2,
增加21商店错误。 CREATE TABLE用“catchall” VALUES LESS THAN子句,提供给大于明确指定最高值:MAXVALUE最大可能整数值
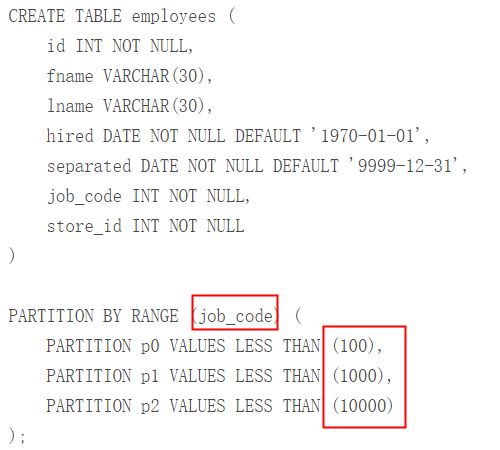
基于雇员的工作代码分表,job_code 列值的连续区间。2位数字:普通工人,3数字:办公室和支持人员,4数字:管理层
基于每个雇员离开公司的年份来分割表,YEAR(separated)
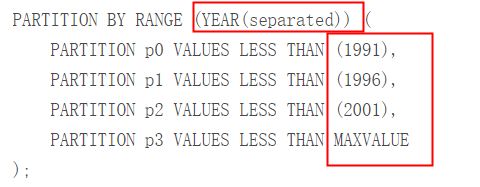
1991年前雇佣p0中,1991到1995年p1中, 1996到2000年p2中,2000年后p3中。
适用场景:
1)删除一个分区上的“旧的”数据时,只删除分区即可。DELETE FROM employees WHERE YEAR (separated) <= 1990
2)包含有日期或时间值,包含有从一些其他级数开始增长的值的列。
3)经常运行直接依赖于用于分割表的列的查询。如”SELECT COUNT(*) FROM employees WHERE YEAR(separated) = 2000 GROUP BY store_id;”迅速地确定只有分区p2扫描
二、LIST分区
类RANGE分区,基于列值匹配一个离散值集合中的某个值
(1)“PARTITION BY LIST(expr)”来实现,其中“expr”是某列值或一个基于某个列值、并返回整数值的表达式,VALUES IN (value_list)定义分区,value_list逗号分隔整数列表。


(2) 西区的所有音像店都卖了:“ALTER TABLE employees DROP PARTITION pWest;”比相同作用DELETE(删除)查询“DELETE query DELETE FROM employees WHERE store_id IN (4,12,13,14,18);”有效得多。
(3) LIST没有“VALUES LESS THAN MAXVALUE”要匹配的任何值都必须在值列表中找到。
INSERT INTO employees VALUES(224, 'Linus', 'Torvalds', '2002-05-01', '2004-10-12', 42, 21);“store_id”列值21不能在用于定义分区pNorth, pEast, pWest,或pCentral的值列表中找到。
(4) 与其他三种生成复合的子分区
三、HASH分区
“PARTITION BY HASH (expr)”,“expr”返回一个整数表达式。很可能需要再添加“PARTITIONS num”子句,num是非负整数,表示要被分割成分区数量
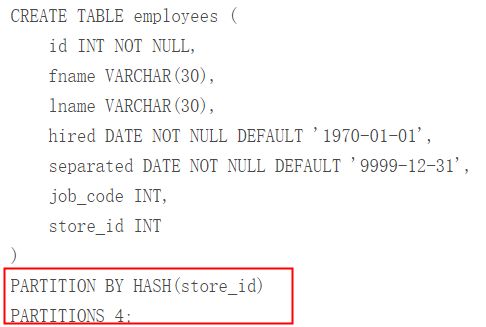
没有PARTITIONS子句,分区默认为1。NDB Cluster(簇)表,默认分区数将与簇数据节点数量相同,这种修正可能是考虑任何MAX_ROWS设置,确保所有的行都能合适地插入分区中。
用HASH函数对createtime日期进行HASH运算,根据日期来分区数据,10个分区。
LINER HASH
支持线性哈希功能,与常规区别,用线性2幂(powers-of-two)运算法则,常规哈希用模数。语法上区别“PARTITION BY”子句中添加“LINEAR”关键字。

表达式expr,保存到分区num 个分区中的分区N,其中N是根据下面的算法得到:
1. 大于num、2的幂,称为V
2. V = POWER(2, CEILING(LOG(2, num))) (如,假定num是13。LOG(2,13)就是3.7004397181411。 CEILING(3.7004397181411)就是4,则V = POWER(2,4), 即等于16)。
3. 设置 N = F(column_list) & (V – 1).
4. 当 N >= num: · 设置 V = CEIL(V / 2) · 设置 N = N & (V – 1)
例如,假设表t1,使用线性哈希分区且有4个分区,是通过下面的语句创建的: CREATE TABLE t1 (col1 INT, col2 CHAR(5), col3 DATE) PARTITION BY LINEAR HASH( YEAR(col3) ) PARTITIONS 6; 现在假设要插入两行记录到表t1中,其中一条记录col3列值为’2003-04-14′,另一条记录col3列值为’1998-10-19′。第一条记录将要保存到的分区确定如下: V = POWER(2, CEILING(LOG(2,7))) = 8 N = YEAR(’2003-04-14′) & (8 – 1) = 2003 & 7 = 3 (3 >= 6 为假(FALSE): 记录将被保存到#3号分区中) 第二条记录将要保存到的分区序号计算如下: V = 8 N = YEAR(’1998-10-19′) & (8-1) = 1998 & 7 = 6 (6 >= 4 为真(TRUE): 还需要附加的步骤) N = 6 & CEILING(5 / 2) = 6 & 3 = 2 (2 >= 4 为假(FALSE): 记录将被保存到#2分区中) 按照线性哈希分区的优点在于增加、删除、合并和拆分分区将变得更加快捷,有利于处理含有极其大量(1000吉)数据的表。
缺点:分布不均衡。
四、KEY分区
用的少,知道怎么用即可。
类似HASH分区,区别:KEY分区只支持计算一列或多列,且MySQL服务器提供其自身的哈希函数。必须有一列或多列包含整数值。
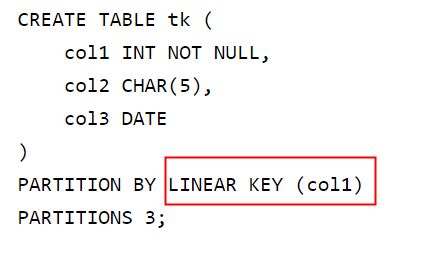
KEY分区中使用关键字LINEAR和在HASH分区中使用具有同样作用,分区编号是通过2的幂(powers-of-two)算法得到,不是通过模数算法。