利用认知知识图谱推理进行one-shot 关系学习
Cognitive Knowledge Graph Reasoning for One-shot Relational Learning
- original
- motivation
- Defination of problem
- model
- optimizer
- complexity analysis
- 实验
original
Zhengxiao Du1, Chang Zhou2, Ming Ding1, Hongxia Yang2, Jie Tang1
1 Department of Computer Science and Technology, Tsinghua University
2 DAMO Academy, Alibaba Group
NeurIPS 2019 under review
代码链接
motivation
知识图谱推理技术是完善知识图谱的重要手段,有效的知识图谱对于阅读理解、对话系统等应用有非常重要的指导作用。目前的知识图谱推理技术主要分为基于表示学习和基于路径信息两类。基于表示学习的方法可解释性很差,基于路径信息的方法主要是使用强化学习方法获取连接两个实体之间的路径信息,具有显式的可解释性,但是路径信息包含信息有限。本文提出一种可解释性的方法,利用认知知识图进行推理。 另一方面, 数据驱动的深度学习技术往往需要大量的数据进行学习,对于训练样例很少时,往往需要在先前的类别中学习大量的先验知识,因此研究one shot learning.
Defination of problem
知识图谱 G G G由三元组 ( h , r , t ) {(h,r, t)} (h,r,t)集合组成。 本文的研究问题可以表示为给定未知关系的实体对集合 { ( h r , t r ) } i = 1 m \{(h_r, t_r)\}_{i=1} ^m {(hr,tr)}i=1m, 推断出尾实体 ( h r , r , ? ) {(h_r, r, ?)} (hr,r,?), 本文里的m=1
model
本文的结构图如下:
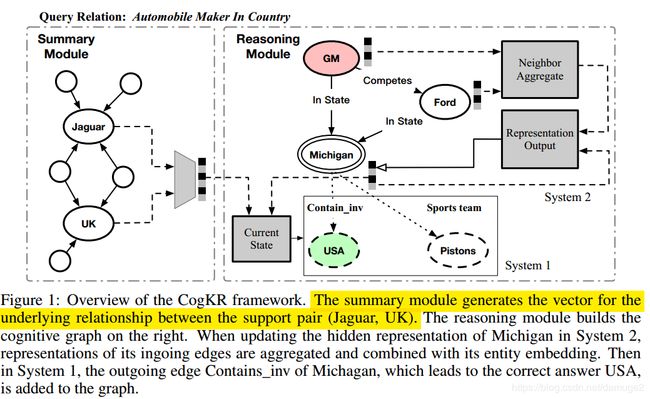
本文的结构主要分为两个部分:summary module 和 reasoning module
summary module 的主要作用是根据训练样例 ( h , t ) (h,t) (h,t)推断它们之间的关系,将推断的关系使用图神经网络表示成向量 ω h , t \omega_{h, t} ωh,t。 首先是使用实体的embedding 结合 与实体相连边以及节点的embedding表示两个实体:
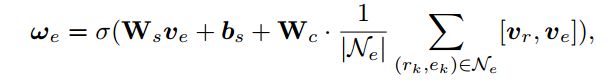
使用下面公式表示两个实体之间潜在的关系:
![]()
**reasoning module:**主要分为系统1和系统2, 系统1负责从知识图谱中收集信息,构建扩展认知知识图谱, 系统2负责推理。
- 系统1
首先了解一下什么是认知知识图谱, 认知知识图谱是知识图谱的一个子图,是在迭代过程中不断扩展的, 认为限定停止迭代的条件或者说是认知知识图谱的大小。
它的构建过程可以用如下的算法进行描述:

V V V表示认知知识图谱中的节点, E E E表示认知知识图谱里的边, F F F是一个辅助的队列。
接下来我们介绍认知知识图谱是根据什么来扩展的,即上述伪代码的第7行, 根据一个多项式分布采样下一步的动作,或者说是要扩展的边。
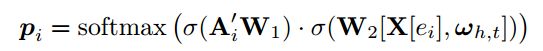
其中 A i A_i Ai表示 e i e_i ei连接的所有边表示堆叠(stack)的矩阵,每条边(r,e)表示是 [ v e , r , X [ e ] ] [v_e, r, X[e]] [ve,r,X[e]], X [ e i ] X[e_i] X[ei]是 e i e_i ei的状态表示, 具体表示方法在系统2中说明
系统2
每次进行扩展之后,都需要更新相关节点的状态表示,更新的方式也是类似使用图神经网络的方法:
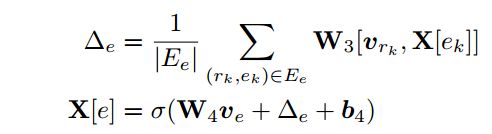
更新方式与传统的图神经网络节点状态表示更新方式有不同, 传统的图神经网络中当前节点的表示是根据上一层相关节点状态进行表示,这里把所有的节点看做同一层,按照序列化的顺序进行更新。
当所有的认知图中的节点都遍历之后,停止扩展认知图。
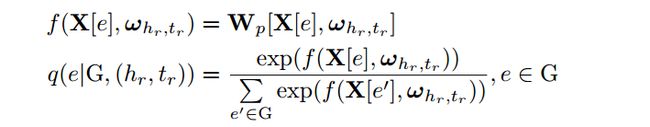
使用上面的公式选择认知图中使得q最大的节点作为推断的结果
optimizer
t ^ \hat{t} t^是推断出来的尾实体的概率:
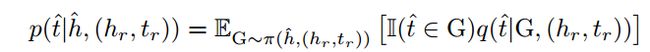
主要优化两个过程, 一个是优化策略 π ( h ^ , ( h r , t r ) ) \pi(\hat{h}, (h_r, t_r)) π(h^,(hr,tr)), 另外一个是优化最后的预测 q ( t ^ ∣ G , ( h r , t r ) ) q(\hat{t}|G,(h_r, t_r)) q(t^∣G,(hr,tr)). 优化策略主要是采用强化学习的方式, 优化预测函数主要是优化交叉熵损失函数。梯度是两部分的梯度之和。
complexity analysis
认知图扩展的步数最多是 O ( ∣ v ∣ ) O(|v|) O(∣v∣), 每次扩展最多访问 η \eta η条边, 因此最多需要 O ( η ∣ V ∣ ) O(\eta|V|) O(η∣V∣)时间扩展完整个认知图。 系统2中节点状态表示更新最多 O ( η ∣ E ∣ ) O(\eta |E|) O(η∣E∣), ∣ E ∣ = O ( ∣ V ∣ 2 ) |E|=O(|V|^2) ∣E∣=O(∣V∣2)
实验
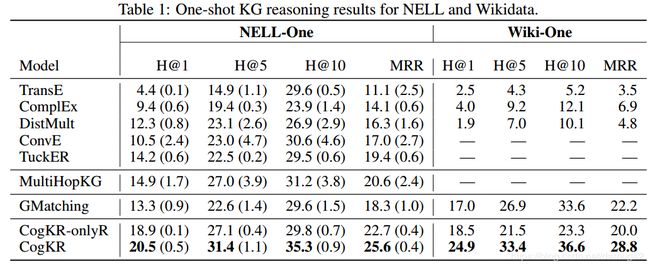
前5个baseline 主要是基于表示学习方法 MultiHopKG主要是基于路径查找方法 Gmatching 是一个one shot learning 的baseline
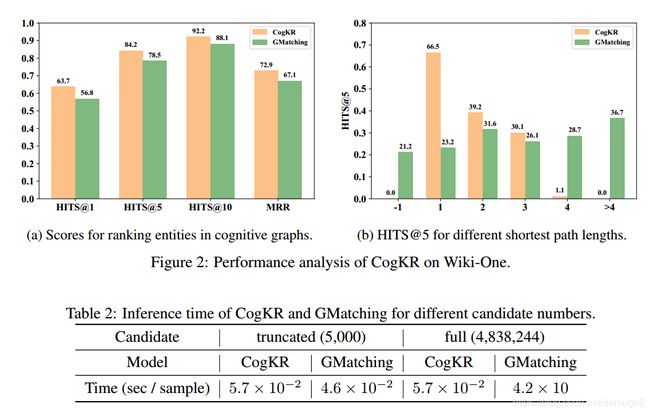
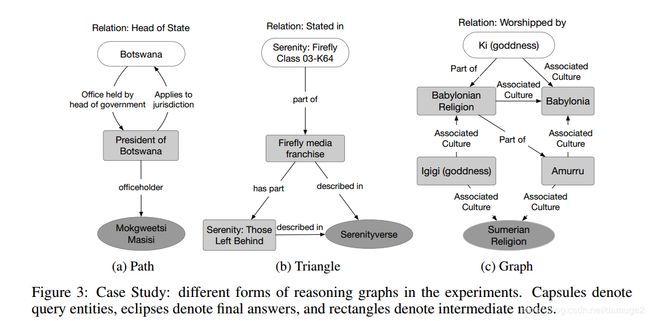
Figure2中(a)展现了CogKR的优势, (b)体现了CogKR的不足之处, 对于长路径的推理能力很差