前言
LIBSVM是台湾大学林智仁(Lin Chih-Jen)教授等开发设计的一个简单、易于使用和快速有效的SVM分类与回归的软件包。LIBSVM软件包拥有目前各种常用编程语言的版本,如Python、Java、Matlab等。
一、支持算法
LIBSVM支持下述算法,具体可以参考作者写的介绍文档[1]。
1.1 C-SVC


1.2 ν-SVC


1.3 ε-SVR

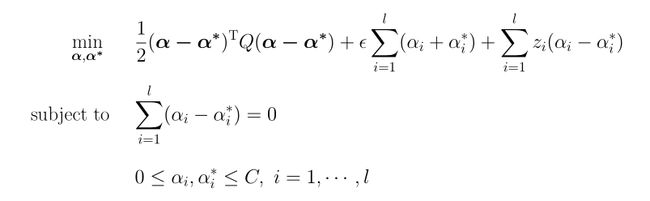
1.4 ν-SVR


二、LIBSVM入门使用
作者写了该软件包的入门使用文档[2],大致总结如下:
SVM使用流程:
- 转换数据格式;
- 缩放数据,例如将其变换到[0,1]或者[-1,1]的范围;
- 使用RBF核函数;
- 使用交叉验证寻找最优参数C和r;
- 使用最优参数训练整个数据集;
- 测试。
首选RBF核函数,原因是:
- 线性核是RBF的特例;
- Sigmoid核在特定参数下的特性类似于RBF;
- 多项式核参数比RBF多,在阶数较高时且容易导致计算数值过大。
但是在特征数量很大时,RBF可能会不适用,使用线性核是一种更好的选择。
寻找最优参数:
使用网格搜索利用交叉验证寻找最优参数时,先使用粗网格,然后缩小寻找区域使用细网格。网格使用指数拉伸网格,例如:C=2-5,2-4,...,210 ,gamma=2-7,2-6,...,215。
特征数量:
特征过多时,先进行特征提取,选取一个合适的特征子集。
LIBSVM不适合特征数量过多且样本数量过多的情形,比如文档分类。
LIBLINEAR更加适合这类情况。
在样本数量很大时,LIBLINEAR速度会快很多倍。
三、Python接口
LIBSVM接口函数在svmutil.py文件中,按照源码顺序依次是:
svm_read_problem(data_file_name)
从文本文件中读取数据,数据的格式为:
label index1:value1 index2:value2 ...
返回训练所用的y和x,使用示例:
y, x = svm_read_problem('data.txt')
假定文件中数据如下:
1 1:1.1 2:1.2 3:1.3 4:1.4
-1 1:-1.1 2:-1.2 3:-1.3 4:-1.4
则y=[1.0, -1.0],
x=[{1: 1.1, 2: 1.2, 3: 1.3, 4: 1.4}, {1: -1.1, 2: -1.2, 3: -1.3, 4: -1.4}]。svm_load_model(model_file_name)
从文件中读取SVM模型。svm_save_model(model_file_name, model)
将SVM模型保存到文件中。evaluations(ty, pv)
ty即训练的数据y,
pv即预测的y值。
返回(准确率, 均方误差, 均方相关系数)这样一个元组,使用示例:
ACC, MSE, SCC = evaluations(y, pred_labels)。-
svm_train(arg1, arg2=None, arg3=None)
调用有以下几种形式:
svm_train(y, x [, options]) -> model | ACC | MSE
svm_train(prob [, options]) -> model | ACC | MSE
svm_train(prob, param) -> model | ACC | MSE
如果使用了交叉验证,epsilon-SVR和nu-SVR返回MSE,其他返回ACC;没有使用交叉验证就返回model。
后两种调用中出现的prob参数是对应svm.py文件中的svm_problem类型,
生成方法为:prob = svm_problem(y, x)。
最后一种调用方式中出现的param参数对应svm.py中的svm_parameter类型,
生成方法为:param = svm_parameter('-t 0 -c 1')。
options类似于linux命令中的参数输入方式,有以下选项:-sSVM的类型,默认值为0
0 -- C-SVC
1 -- nu-SVC
2 -- one-class SVM
3 -- epsilon-SVR
4 -- nu-SVR-t核函数的类型,默认值为2
0 -- 线性: u'*v
1 -- 多项式: (gamma*u'*v + coef0)^degree
2 -- 径向基: exp(-gamma*|u-v|^2)
3 -- sigmoid: tanh(gamma*u'*v + coef0)
4 -- precomputed kernel,核函数值存储于training_set_file中-ddegree的值,默认为3;-ggamma的值,默认1/num_features;-rcoef0的值,默认为0;-cC-SVC, epsilon-SVR, and nu-SVR的cost,默认值为1;-nnu-SVC, one-class SVM, and nu-SVR中的nu,默认值为0.5;-pepsilon-SVR的loss function中的epsilon参数,默认值0.1;-m缓冲内存大小,单位MB,默认值100;-e终止判据的容忍值,默认值0.001;-h是否使用收缩启发式算法(shrinking heuristics),取值0或1,默认值为0;-b是否估算正确概率,取值0或1,默认值为0;-wiC-SVC中第i个特征的Cost参数;-v交叉验证;-q静默方式,无输出。
svm_predict(y, x, m, options="")
y、x对应测试数据,m即训练好的model,options支持-b和-q。
调用语法:
p_labs, p_acc, p_vals = svm_predict(y, x, model [,'predicting_options'])
返回预测的标签,(准确率, 均方误差, 均方相关系数)元组,以及-b 1参数时返回判断系数。
Tips:
svm_train(y, x [, options])这种形式的调用,x除了字典形式以外,如:
x = [{1: 1.1, 2: 1.2, 3: 1.3, 4: 1.4}, {1: -1.1, 2: -1.2, 3: -1.3, 4: -1.4}]
也可以是如下形式,
x = [[1.1, 1.2, 1.3, 1.4], [-1.1, -1.2, -1.3, -1.4]]
svm_train会调用svm.py文件中svm_problem类对y和x进行包装,svm_problem类又会调用gen_svm_nodearray函数对x进行处理,该函数可以处理x两种情形的输入。
四、数值实验
这里使用SVR对创业板开盘指数历史曲线做一下回归,数据可以从网易财经下载[3]。自变量选取前一日的:收盘指数、最高指数、最低指数、开盘指数、成交量、成交额,因变量:开盘指数。
首先,使用get_stock_data函数从下载的数据中读取相关信息,并转换为相应的参数数组(用到工具函数代码见最后)。进行归一化之后,使用网格搜索得到最优参数。最后使用最优参数进行训练。
def get_stock_data(file_path):
"""
从文件中读取股票的数据信息。
:param file_path:
:return: X = [收盘指数、最高指数、最低指数、开盘指数、成交量、成交额]
y = [开盘指数]
"""
# 收盘价、最高价、最低价、开盘价、成交量、成交额
# 从0开始计数,对应表格的第4,5,6,7,11,12列
... ...
stock_data_array, target_array = get_stock_data(stock_file_path)
m_count = len(stock_data_array)
x_data = stock_data_array[:m_count-1]
y_data = target_array[1:]
# 归一化
x_data, x_map_inf = Utils.map_min_max_2D(x_data)
y_data, y_map_inf = Utils.map_min_max_1D(y_data)
# 寻找最优参数
mse_best, c_best, g_best = Utils.get_best_cg_for_SVR(y_data, x_data, -4, 4, -4, 4, c_step=0.25, g_step=0.25)
# 使用最优参数进行训练
model = svm_train(y_data, x_data, '-s 3 -c {} -g {} -p 0.0005'.format(str(c_best), str(g_best )))
py_data, p_acc, p_val = svm_predict(y_data, x_data, model)
# 从归一化数据变换回来
y_data, _ = Utils.map_min_max_1D(y_data, is_reverse=True, map_inf=y_map_inf)
py_data, _ = Utils.map_min_max_1D(py_data, is_reverse=True, map_inf=y_map_inf)
回归的结果如下:

“炒股这方面,接盘是不可能接盘的,这辈子不可能接盘的。做分析又不会做,就是关灯吃面、滴蜡复盘,才能维持的了生活这样子,进股市感觉像回家一样,在股市里的感觉比家里感觉好多了!上市公司个个都是精华,吹得又好听,我超喜欢股市的!”——接盘·格瓦拉
勇敢的生活下去还是要靠爱... ...

注:
Utils类包含几个工具函数,为方便阅读,此处省略了具体的代码。
import numpy as np
import math
from svmutil import *
class Utils:
@staticmethod
def output_tecplot_line(title="1D Data", file_name=".tmp.plt", var_dict=None):
"""
将数据输出成Tecplot曲线
:param title:
:param file_name:
:param var_dict:
:return:
"""
@staticmethod
def output_tecplot_2D(title="2D Data", file_name=".tmp.plt", var_dict=None):
"""
将数据输出成Tecplot二维数据
:param title:
:param file_name:
:param var_dict:
:return:
"""
@staticmethod
def map_min_max_2D(data, map_range=[0, 1], use='col', is_reverse=False, map_inf=[]):
'''
对二维data矩阵进行归一化
:param data: 二维矩阵,为list类型
:param map_range: 默认映射到[0,1]之间
:param use: 'row'按行归一化,'col'按列归一化,默认按行列一化
:param is_reverse: 还原
:param map_inf: 保存归一化的映射信息,即每一行的最小值、最大值两个参数
:return: 归一化的矩阵,(映射信息矩阵)。
'''
@staticmethod
def map_min_max_1D(data, map_range=[0, 1], is_reverse=False, map_inf=[]):
@staticmethod
def get_best_cg_for_SVR(train_label, train_data, c_min, c_max,
g_min, g_max, fold_counts=3, c_step=1, g_step=1):
'''
使用LIBSVM中SVR工具之时,获取最优参数-c和-g的值。
:param train_label:
:param train_data:
:param c_min:
:param c_max:
:param g_min:
:param g_max:
:param fold_counts: 交叉验证的折数
:param c_step:
:param g_step:
:return: 返回c、g的最优值。
'''
附录——我的其他博客
支持向量机SVM
深度神经网络Google Inception Net-V3结构图
深度神经网络ResNet-V2结构图
从计算流体力学的角度理解循环神经网络
-
Chang C C, Lin C J. LIBSVM: A library for Support Vector-Machines. https://www.csie.ntu.edu.tw/~cjlin/papers/libsvm.pdf ↩
-
Hsu C W, Chang C C, Lin C J. A Pratical Guide to Support Vector Classification. https://www.csie.ntu.edu.tw/~cjlin/papers/guide/guide.pdf ↩
-
网易财经:http://quotes.money.163.com/trade/lsjysj_zhishu_000001.html ↩