使用数据挖掘软件Rapidminer进行关联规则分析
这段时间使用了Rapidminer进行关联规则的挖掘实验,很多细节问题折腾了好长时间。在网络上也搜不到类似的东西,尤其是中间遇到一个问题折腾了两天。最后是通过研究Rapidminer本身带有的例子才把一些细节给搞清楚,因此把一些需要注意的地方写下来以备下次查询。
前提是有很多的数据,准备做频繁模式以及关联规则分析,也了解过Weka或者Rapidminer这样的工具,也能自己写出代码来完成这个工作。但是,考虑到时间成本以及对算法充分了解的基础上,想要快速得到结果,从而把主要精力放在数据的构造上和挖掘结果的分析上,那就有必要了解下如何使用这些工具软件。
1 简介:
首先介绍下RapidMiner: RapidMiner一款开源数据分析工具。有非常丰富的数据分析算法,通过拖拽方式进行数据挖掘流程的连接,每个节点是一个处理过程(可以包含子过程)。每个节点的操作可以是数据本身的过滤、变换、属性选择等。也支持正则表达式过滤、按权重过滤、丢失补齐等一系列自己想要完成的数据操作。建模的model也包括了常用的分类预测、聚类、关联规则、相关性计算、相似性计算等模型,基本满足了很多的需要。
本文介绍的工作是:有一个用于频繁模式和关联规则分析的数据,通常是一个二维表格,用Rapidminer完成这样一个分析的具体过程。
数据准备:通过要做频繁模式和关联规则分析的数据都有稀疏的特点,当数据量很大的时候,比如有上万维、几十万的条目数据,就有必要考虑使用稀疏存储的方式来导入到Rapidminer中。由于Rapidminer能识别Weka中的arff格式数据,因此,本文采用Weka中稀疏数据的存储格式。下面是一个例子(该例子是以传统购物车的商品来说明,每个商品是一个属性,每个属性的取值是F或者T,当然做关联规则的数据也不一定本身就是二值属性的。):
@relation'basket'
@attribute fruitveg {F, T}
@attribute freshmeat {F, T}
@attribute dairy {F, T}
@attribute cannedveg {F, T}
@attribute cannedmeat {F, T}
@attribute frozenmeal {F, T}
@attribute beer {F, T}
@attribute wine {F, T}
@attribute softdrink {F, T}
@attribute fish {F, T}
@attribute confectionery {F, T}
@data
{1 T, 2 T, 10 T}
{1 T, 10 T}
{3 T, 5 T, 6 T, 9 T}
{2 T, 7 T}
{1 T, 7 T, 9 T}
数据格式说明请见:http://www.tuicool.com/articles/Q3MfEr
2. 软件准备:如果本身有这个软件请跳过此步。
http://softadvice.informer.com/Rapidminer_5.3.html 安装很简单,安装目录下有源码,可以导入eclipse研究,也可以自己下载源码。
3. 打开Rapidminer就可以看到这样的界面了。

3.1导入数据:
使用excel 格式的文件, arff格式等等。本例选用读取arff格式文件,因此拖拽一个Read ARFF 的操作,然后配置读入数据的路径。
流程图为:
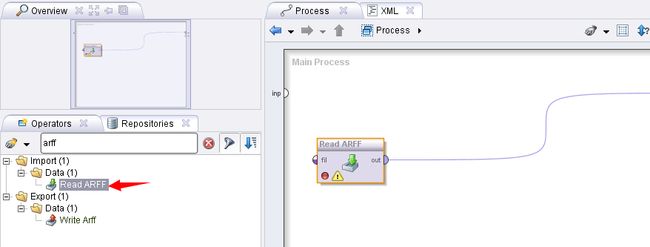
配置路径如下:

3.2数据预处理:
首先查看数据如下:这里仅有11个商品(属性),12个购物车(也就是12条数据)。
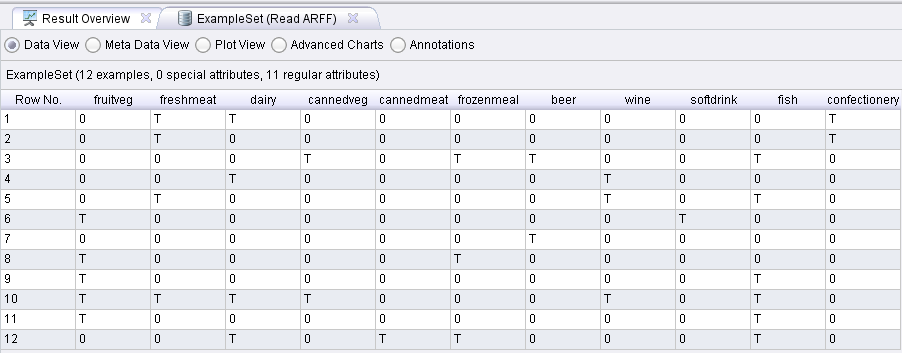
如果直接使用这个读入的数据进行FPGrowth树的构建,流程图如下:
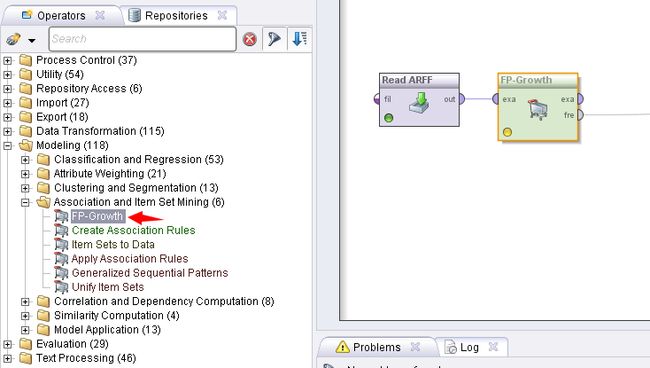
挖掘结果是:如下图所示,Rapidminer并没有正确得到商品的频繁集,而是商品取反的频繁集,也就是缺失商品的频繁集。

分析原因发现:Rapidminer的FP-Growth算法要求输入的是二值属性(bionominal),但是由于本例中的数据本身就是二值属性,算法本身也没有报错。运行结果和预期结果天壤之别就是由于合理的事情和一厢情愿。笔者甚至开始怀疑开源软件本身有bug,因此还花了两天时间调试代码,最后发现是由于软件本身没有认出来T就是表示”有“,而F表示”没有“的意思。这里要补充一点是,比如对频繁一项集进行计算的时候,针对的是一个属性的不同取值进行统计,这些取值有T有F,甚至是有三个取值或者更多,那么要统计哪一个取值的出现的个数作为结果呢?比如,一般频繁集的格式是:比如统计Age = ”old “ 是频繁集,它的置信度为 count( Age = ”old “)/ count(all ages)。 因此不指定属性的取值就直接给出统计结果是错误的,因此可以说是Rapidminer的一个bug。
我们希望的是它会自动统计取值为T的那些条目。当然,它也不能具备这样的功能能自动识别语义,因为这件事是需要软件使用者来说明的。但是,Rapidminer本身不报告这里可能出现语义理解偏差的问题就显得不太合理了。
因此在真正进行FP-Growth树构建的时候还要进行一步数据预处理,即进行二值化处理,告诉软件T表示true,F表示false。
如下图所示,选择Nominal to Binomial 操作对数据进行二值化,选中该操作的transform binomial 选项。
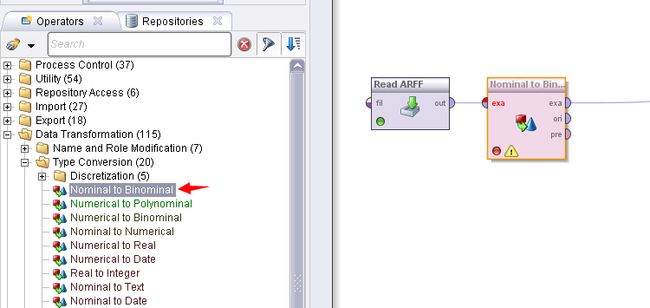
配置参数为:
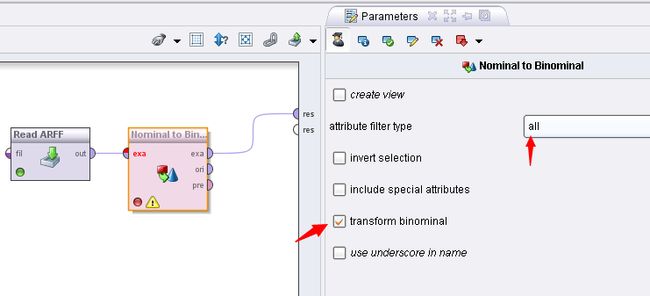
该操作结束后的数据如下:可以看到的是属性增加了一倍为22个。即每个属性的取值个数相加在一起为22个。如果原来的数据在每个属性的独立取值个数为3,则结果就是3+3+...3= 33个(因为本数据中有11个属性),以此类推。

经过本步骤操作后,发现属性的个数增加了很多,但是很多属性也就是为取值为0的属性是不需要的,因此需要过滤掉。流程图如下:

配置selectattribute这个操作的参数:
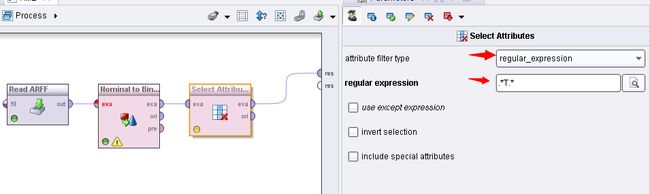
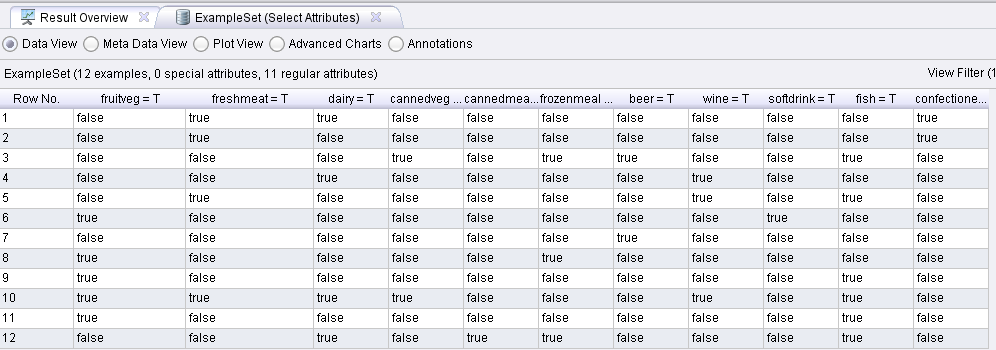
这个参数的意义就是使用正则表达式过滤掉属性中不为T的属性,也就是留下属性取值为T的属性。 可以看到的是,保留的属性取值都是T,也就是保留语义为存在的商品。到这时,这个数据就是Rapidminer认识的数据了,它要计算频繁集就知道统计属性取值为true的个数了。其中,属性的名称变为了 frultveg = T 等。最后结果就是将数据构造为如下图所示的样子:
3.3完成频繁集和关联规则挖掘
最后使用FP-Growth 模型和Create Association Rules 进行连接,得出结果。
结果为:
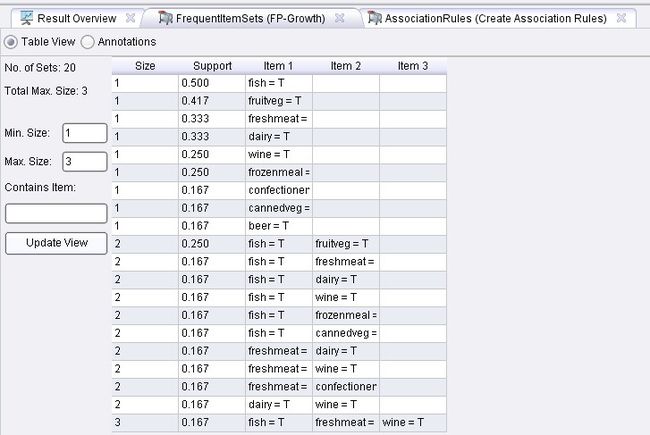
关联规则如下图:

4 总结:
本实验采取的weka的arff数据,该数据格式支持稀疏存储的方式,对关联规则挖掘尤其适用。Rapidminer适用于小样本数据的挖掘,如果数量大很大,则要考虑适用更优秀的算法或者并行处理方式。MapReduce的编程模型对这种可以并行的任务十分方便。一般数量的挖掘,我的实验是在5万维,30万条数据进行的,利用16G内存进行实验,还是比较轻松。