Flink广播状态实战——设备异常报警
背景:
昨天,收到一个网友的咨询:
他们想要实时监控网络攻击请求——即如何让一个实时的请求日志同mysql表(监控规则)中数据进行匹配,且mysql表是可以动态配置呢?
如果匹配成功之后,还需再添加一个字段(从mysql中取),输出数据到kafka,然后用报表展示明细数据,报告给安全部门同事。

听到这个需求的我,第一反应是↑↑↑
但是,
做大数据的男人怎么能怂?
不多说废话,开干!
异步io+缓存读取mysql的方案后续会更新
本篇文章用scala开发
(用scala开发spark习惯了,所以flink也习惯用sclal)
首先,让我们先来梳理一个流程图:
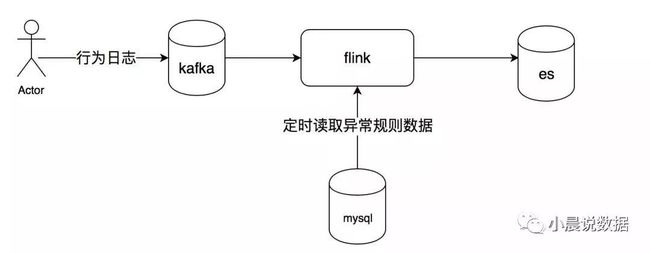
我的mysql日志
重点提醒
这里的难点:一个json字段,可能对应多种value。也就是你都要广播到状态中,所以我在设计key的时候采了用两个字段拼接做key(下文有细致讲解)
SET NAMES utf8mb4;SET FOREIGN_KEY_CHECKS = 0;-- ------------------------------ Table structure for event_mapping-- ----------------------------DROP TABLE IF EXISTS `event_mapping`;CREATE TABLE `event_mapping` (`id` int(11) NOT NULL AUTO_INCREMENT,`region` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '要匹配的报文字段',`value` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '要匹配的报文字段的值',`inner_code` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '内部映射编码',`rule` varchar(50) CHARACTER SET utf8 COLLATE utf8_bin NULL DEFAULT NULL COMMENT '匹配规则',PRIMARY KEY (`id`) USING BTREE) ENGINE = InnoDB AUTO_INCREMENT = 4 CHARACTER SET = utf8 COLLATE = utf8_bin ROW_FORMAT = Dynamic;-- ------------------------------ Records of event_mapping-- ----------------------------INSERT INTO `event_mapping` VALUES (1, 'desc', 'usb插入', '1001', 'include');INSERT INTO `event_mapping` VALUES (2, 'desc', '安装恶意软件', '1002', 'include');INSERT INTO `event_mapping` VALUES (3, 'id', '100', '1003', '=');SET FOREIGN_KEY_CHECKS = 1;
在这里,我们主要解析json串里面的risk(风险)字段,它存储的是list,需要遍历里面的行为数据,risk对象里面存储的字段,就是mysql中定义的region字段。
难点1——需要动态识别mysql的region和json串匹配

这个举个例子大家就能明白~
举个例子大家就明白:mysql中设置规则字段是desc-->需要从json中解析descmysql中设置规则字段是level-->需要从json中解析level等等。。。
难点2
——mysql的region(desc)和value对应关系是1对多
需要动态识别mysql的region(desc)对应的value(安装恶意软件,usb插入) 是1对多;即一个规则字段,可以设置多个报警触发条件。
存储广播变量的时候,需要特别设计一下key,我的解决办法是(region+"_"+value 拼接成key)。
INSERT INTO `event_mapping` VALUES (2, 'desc', '安装恶意软件', '1002', 'include');INSERT INTO `event_mapping` VALUES (1, 'desc', 'usb插入', '1001', 'include');
简化后的Kafka日志:
{"message_id": "aaaaaaaa","risks": [{"time": "2019-04-16 12:00:00","last": 600,"count": 100,"risk_type": {"main_type": "权限鉴别","sub_type": "频繁鉴权"},"desc": "安装恶意软件","level": "低"}, {"time": "2019-04-16 12:00:00","last": 600,"count": 100,"risk_type": {"main_type": "权限鉴别","sub_type": "频繁鉴权"},"desc": "usb插入","level": "低"}]}
读取mysql的程序:
import java.sql.DriverManagerimport java.sql.Connectionimport java.sql.DriverManagerimport java.sql.PreparedStatementimport java.sql.ResultSetimport java.utilimport java.util.Hashtableimport org.apache.flink.configuration.Configurationimport org.apache.flink.streaming.api.functions.source.{RichSourceFunction, SourceFunction}import scala.collection.mutablecase class RegionInfo(region:String,value : String,inner_code:String)class JdbcReader extends RichSourceFunction[RegionInfo]{private var connection:Connection = nullprivate var ps:PreparedStatement = nullprivate var isRunning:Boolean = trueoverride def cancel(): Unit = {super.close()if(connection!=null){connection.close()}if(ps != null){ps.close()}isRunning = false}override def run(ctx: SourceFunction.SourceContext[RegionInfo]): Unit = {while (isRunning){val resultSet = ps.executeQuery()while (resultSet.next()){val rangeInfo =RegionInfo(resultSet.getString("region"),resultSet.getString("value"),resultSet.getString("inner_code"))ctx.collect(rangeInfo)}//休息2分钟Thread.sleep(5000 * 60)}}override def open(parameters: Configuration): Unit = {super.open(parameters)val driverClass = "com.mysql.jdbc.Driver"val dbUrl = "jdbc:mysql://localhost:3306/flink"val userName = "root"val passWord = "1234"connection = DriverManager.getConnection(dbUrl, userName, passWord)ps = connection.prepareStatement("select region, value, inner_code from event_mapping")}}
flink核心代码:
import java.utilimport java.util.Propertiesimport com.alibaba.fastjson.JSONimport org.apache.flink.api.common.serialization.SimpleStringSchemaimport org.apache.flink.api.common.state.MapStateDescriptorimport org.apache.flink.api.common.typeinfo.{BasicTypeInfo, TypeHint, TypeInformation, Types}import org.apache.flink.streaming.api.functions.co.BroadcastProcessFunctionimport org.apache.flink.streaming.api.scala.StreamExecutionEnvironmentimport org.apache.flink.streaming.connectors.kafka.FlinkKafkaConsumer08import org.apache.flink.util.Collectorimport org.apache.flink.api.scala._object DeviceMonitorCEP {def main(args: Array[String]): Unit = {implicit val typeInfo = TypeInformation.of(classOf[(RegionInfo)])val env = StreamExecutionEnvironment.getExecutionEnvironmentval descriptor:MapStateDescriptor[String,RegionInfo]=new MapStateDescriptor("region_rule",BasicTypeInfo.STRING_TYPE_INFO,TypeInformation.of(new TypeHint[RegionInfo] {}))val regionStream =env.addSource(new JdbcReader).broadcast(descriptor)val properties = new Properties()//kafka位置 老版本的 kafka是配置zookeeper地址properties.setProperty("bootstrap.servers","localhost:9092")properties.setProperty("zookeeper.connect","localhost:2181")val topic = "flink-topic"properties.setProperty("group.id", "test-flink")val textConsumer = new FlinkKafkaConsumer08(topic,new SimpleStringSchema(),properties)env.addSource(textConsumer).connect(regionStream).process(new BroadcastProcessFunction[String,RegionInfo,String]{override def processBroadcastElement(regionInfo: RegionInfo, ctx: BroadcastProcessFunction[String, RegionInfo, String]#Context, out: Collector[String]) = {val region = regionInfo.regionval state =ctx.getBroadcastState(descriptor)state.put(region+"_"+regionInfo.inner_code,regionInfo)}override def processElement(value: String, ctx: BroadcastProcessFunction[String, RegionInfo, String]#ReadOnlyContext, out: Collector[String]) = {val json = JSON.parseObject(value)val arrayJson = json.getJSONArray("risks")for ( i <- 0 until arrayJson.size()){val obj =arrayJson.getJSONObject(i)val state =ctx.getBroadcastState(descriptor).immutableEntries().iterator()while (state.hasNext){val map =state.next()if (obj.get(map.getKey.split("_")(0)) == map.getValue.value){obj.put("inner_code",map.getValue.inner_code)out.collect(obj.toJSONString)}}}}}).setParallelism(1).print()env.execute()}}
kafka创建topic代码:
./kafka-topics.sh --zookeeper localhost:2181 --create --topic flink-topic --partitions 3 --replication-factor 1kafka生产代码:
import java.util.Propertiesimport kafka.producer.{KeyedMessage, Producer, ProducerConfig}import scala.io.Sourceobject kafkaProduct {def test1() = {val brokers_list = "localhost:9092"val topic = "flink-topic"val props = new Properties()props.put("group.id", "test-flink")props.put("metadata.broker.list",brokers_list)props.put("serializer.class", "kafka.serializer.StringEncoder")props.put("num.partitions","4")val config = new ProducerConfig(props)val producer = new Producer[String, String](config)var num = 0for (line <- Source.fromFile("/Users/huzechen/Downloads/flinktest/src/main/resources/cep").getLines) {val aa = scala.util.Random.nextInt(3).toStringprintln(aa)producer.send(new KeyedMessage(topic,aa,line))}producer.close()}def main(args: Array[String]): Unit = {test1()}}