Keras模型入门:基于Python及R实现
Keras有两种模型类型:
- 序贯模型
- 使用函数API创建的模型
1. 序贯模型
可以通过将多个层堆叠并传递给Sequential的构造函数来创建序贯模型。
我们将创建一个包含四层的序贯网络。
- 第1层是全连接层(稠密层),其input_shape为(*,784),output_shape为(*,32)。
- 第2层是激活层,将tanh激活函数用于激活输入张量,Activation也可以作为参数应用于稠密层。
- 第3层是一个稠密层,输出为(*,10)。
- 第4层具有应用softmax函数的Activation。
```{Python}
from keras.models import Sequential
from keras.layers import Dense, Activation
model = Sequential([
Dense(32, input_shape=(784,)),
Activation('tanh'),
Dense(10),
Activation('softmax'),
])
```
```{R}
library(keras)
model <- keras_model_sequential()
model %>% layer_dense(units = 32,input_shape = c(784),
activation = 'tanh')
model %>% layer_dense(units = 10,
activation = 'softmax')
```创建的模型如下:
```{Python}
print(model.summary())
```
````{R}
summary(model)
```Model: "sequential_1"
_________________________________________________________________
Layer (type) Output Shape Param #
=================================================================
dense_1 (Dense) (None, 32) 25120
_________________________________________________________________
activation_1 (Activation) (None, 32) 0
_________________________________________________________________
dense_2 (Dense) (None, 10) 330
_________________________________________________________________
activation_2 (Activation) (None, 10) 0
=================================================================
Total params: 25,450
Trainable params: 25,450
Non-trainable params: 0
_________________________________________________________________
None
编译模型:
compile(self,optimizer,loss,metrics=None,sample_weight_mode=None)
- optimizer: 字符串(预定义优化器名或)优化器对象,参考优化器
- loss: 字符串〈预定义损失函数名〉或目标函数,参考损失函数
- metrics: 列表,包含评估模型在训练和测试时的网络性能的指标
- sample_weight_mode: 如果你需要按时间步为样本赋权(2D权矩阵),将该值设
- 为"temporal" 。默认为"None" ,代表按样本赋权(1D权)。
训练模型:
此方法用于制定次数(数据集上的迭代)训练模型:
fit(self, x = NULL, y = NULL,
batch_size = NULL, epochs = 10,
verbose = getOption("keras.fit_verbose", default = 1),
callbacks = NULL, view_metrics = getOption("keras.view_metrics",
default = "auto"), validation_split = 0, validation_data = NULL,
shuffle = TRUE, class_weight = NULL, sample_weight = NULL,
initial_epoch = 0, steps_per_epoch = NULL, validation_steps = NULL,
...)
本函数将模型训练nb_epoch 轮,其参数有:
• X: 输入数据。如果模型只有一个输入,那么x的类型是numpyarray,如果模型有多个输
入,那么x的类型应当为list , list的元素是对应于各个输入的numpyarray
• y: 标签, numpyarray
• batch_size: 整数,指定进行梯度下降时每个batch包含的样本数。训练时一个batch的样本
会被计算一次梯度下降,使目标函数优化一步。
• epochs: 整数,训练的轮数,每个epoch会把训练集轮一遍。
• verbose: 日志显示, 0为不在标准输出流输出日志信息, 1为输出进度条记录, 2为每个
epoch输出一行记录
• callbacks: list,其中的元素是keras.callbacks.Callback 的对象。这个list中的回调函数将会
在训练过程中的适当时机被调用,参考回调函数
• validation_split: 0-1之间的浮点数,用来指定训练集的一定比例数据作为验证集。验证集
将不参与训练,并在每个epoch结束后测试的模型的指标,如损失函数、精确度等。注意,
validation_split的划分在shuffle之前,因此如果你的数据本身是有序的,需要先手工打乱再
指定validation_spl it,否则可能会出现验证集样本不均匀。
• validation_data: 形式为( X, y) 的tuple,是指定的验证集。此参数将覆盖
validation_spilt 。
• shuffle: 布尔值或字符串,一般为布尔值,表示是否在训练过程中随机打乱输入样本的顺
序。若为字符串flbatch" ,则是用来处理HOF5数据的特殊情况,它将在batch 内部将数据打
乱。
• class_weight: 字典,将不同的类别映射为不同的权值,该参数用来在训练过程中调整损失
函数(只能用于训练〉
• sample_weight: 权值的numpyarray,用于在训练时调整损失函数(仅用于训练)。可以传
递一个10的与样本等长的向量用于对样本进行1对1的加权,或者在面对时序数据时,传递
一个的形式为(samp悔, sequen臼~_Iength) 的矩阵来为每个时间步上的样本赋不同的权。
这种情况下请确定在编译模型时添加了sample_weight_mode='temporal' 。
• initial_epoch: 从该参数指定的epoch开始训练,在继续之前的训练时有用。
评估模型:
evaluate(object, x = NULL, y = NULL, batch_size = NULL, verbose = 1, sample_weight = NULL, steps = NULL, callbacks = NULL, ...)本函数按batch计算在某些输入数据上模型的误差,其参数有2
• X: 输入数据,与fit 一样,是numpyarray或numpyarray的list
• y: 标签, numpyarray
• batch_size: 整数,含义同fit 的同名参数
• verbose: 含义同卡it 的同名参数,但只能取0或1
• sample_weight: numpyarray,含义同fit 的同名参数
模型预测:
调用以下predict API进行预测。
predict(object, x, batch_size = NULL, verbose = 0, steps = NULL, callbacks = NULL, ...)接下来给出一个结合使用这些API的实例。
我们将使用皮马印第安人糖尿病数据集。
该数据集最初来自美国糖尿病、消化系统和肾脏疾病研究所,目标是使用数据集中包括的测量值来诊断性地预测患者是否患有糖尿病。不过这些数据集有一定的局限性,例如,数据集中的所有患者都是大于21岁的女性皮马印度安人。数据集由若干医学预测变量和一个目标变量(结果)组成,预测变量包括患者的怀孕次数、BMI、胰岛素水平、年龄等。
```{python}
from keras.models import Sequential
from keras.layers import Dense
import numpy
# fix random seed for reproducibility
numpy.random.seed(7)
# load pima indians dataset
dataset = numpy.loadtxt("data/diabetes.csv", delimiter=",", skiprows=1)
# split into input (X) and output (Y) variables
X = dataset[:,0:8]
Y = dataset[:,8]
```
```{r}
library(keras)
set.seed(7)
dataset <- read.csv('data/diabetes.csv')
X = as.matrix(dataset[,1:8])
Y = dataset[,9]
```
```{python}
# create model
model = Sequential()
model.add(Dense(12, input_dim=8, activation='relu'))
model.add(Dense(8, activation='relu'))
model.add(Dense(1, activation='sigmoid'))
# Compile model
model.compile(loss='binary_crossentropy', optimizer='adam', metrics=['accuracy'])
# Fit the model
model.fit(X, Y, epochs=150, batch_size=10)
Epoch 149/150
768/768 [==============================] - 0s 119us/step - loss: 0.4754 - accuracy: 0.7643
Epoch 150/150
768/768 [==============================] - 0s 105us/step - loss: 0.4790 - accuracy: 0.7760
```
```{r}
# create model
model <- keras_model_sequential()
model %>% layer_dense(12,input_shape = c(8),activation = 'relu')
model %>% layer_dense(8,activation = 'relu')
model %>% layer_dense(1,activation = 'sigmoid')
# Compile model
model %>% compile(loss='binary_crossentropy', optimizer='adam', metrics=c('accuracy'))
# Fit the model
history <- model %>% fit(X, Y, epochs=150, batch_size=10)
Epoch 149/150
768/768 [==============================] - 0s 333us/sample - loss: 0.4873 - accuracy: 0.7747
Epoch 150/150
768/768 [==============================] - 0s 332us/sample - loss: 0.4833 - accuracy: 0.7604
plot(history)
```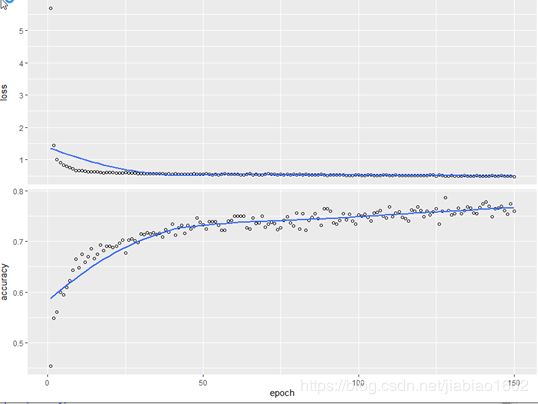
可见,随着Epoch次数越来越大,错误率逐步减少,准确率逐步提高。
最后,让我们来评估模型的效果。
```{python}
# evaluate the model
scores = model.evaluate(X, Y)
print("\n%s: %.2f%%" % (model.metrics_names[1], scores[1]*100))
768/768 [==============================] - 0s 84us/step
accuracy: 77.47%
```
```{r}
# evaluate the model
scores <- model %>% evaluate(X,Y)
paste0(names(scores)[2],":",round(scores[[2]]*100,2),"%")
[1] "accuracy:77.86%"
```Python版本的模型评估准确率为77.47%,R版本的模型评估准确率为77.86%。