纯干货:微软漏洞中国第一人黄正——如何用正确姿势挖掘浏览器漏洞(附完整 PPT)
浏览器就像一扇窗,通过这扇窗,黑客可以攻入电脑的心脏。
就像情场高手,通过眼睛,融化一个人的心灵。
黄正,百度安全实验室 X-Team 掌门人。2016年,这个信仰“技术可以改变世界”的低调黑客大牛以一己之力挖掘无数浏览器漏洞,创下了排名微软 MSRC 2016 年度黑客贡献榜中国区第一(世界第八)的壮举。

从一个安全开发工程师华丽转身,成为安全研究员,黄正最终站在了中国浏览器漏洞挖掘的顶峰。本期硬创公开课,我们将会请到黄正为雷锋网宅客频道的读者童鞋们奉献一场纯干货——如何用正确的姿势挖掘浏览器漏洞。
从上千万行代码中,精准地找到那个微小的漏洞,恰如站在万里之遥,拉弓搭箭。正中靶心。
以下,是雷锋网宅客频道(公众号:宅客频道)诚意奉上的公开课全文及完整 PPT。
关于我自己
我是百度安全实验室的黄正,在百度参与过网页挂马检测、钓鱼欺诈检测、病毒木马分析、伪基站检测、泛站群打击、漏洞挖掘和漏洞利用等。
在百度做恶意网页检测相关的开发工作,可以说是一个职业“鉴黄师”,其实“鉴黄”是一个非常有挑战的事情,每天要检测几亿/几十亿的网页,怎样设计存储、调度、检测算法,才能在有限的服务器、带宽,在有限的时间内检测完,还要去保证检出率和误报率。
所以恶意网页检测是一个比较偏工程的方向,我呢还是有一颗黑客的心,还挑战一些新的安全技术方向。想去挖漏洞,所以在早期组建安全实验室团队时就加入了 X-Team,从安全开发工程师切换到做浏览器漏洞挖掘,今天给大家分享的议题是浏览器漏洞挖掘,希望大家能有所收获。
今天先给大家科普一下浏览器的一些基础知识,再回顾看一下浏览器漏洞类型,重点讲怎么去做一个 Fuzz 系统,以及分享一些我们曾经发现过的一些漏洞POC,最后再分享一下怎么给微软、GOOGLE、苹果报告安全漏洞。
浏览器基础知识
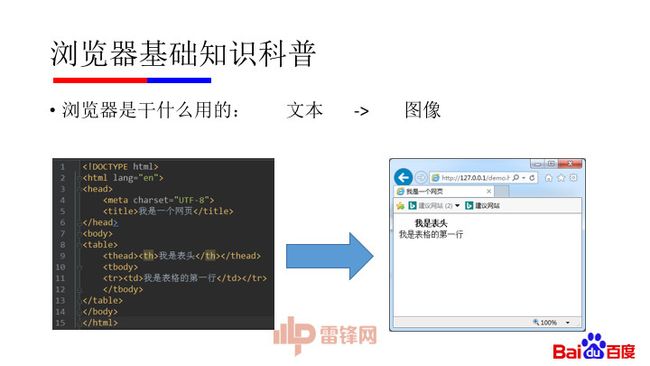
首先,浏览器是干嘛用的。大家都知道是用来看网页用的,再往底层一点呢,它是把html代码按照一定的标准绘制成在屏幕上肉眼可见的图像用的。
比如,像这段html代码,浏览器会按照一定的标准去把他变成一张肉眼可见的网页:
浏览器广泛存在各个地方,Windows,Mac OS X,iOS/iPad,Android,Play station(PS 4),QT,ATM。微信里也有浏览器,可能你每天都在用,但是你不知道。
那么浏览器是怎么把 Html 代码渲染成网页的呢?来看一张浏览器渲染引擎的结构图:

渲染引擎大致可以分成4块:
HTML解释器:将HTML文本解释成DOM;
CSS解释器:解析CSS,为DOM中的各个元素计算样式信息;
布局:根据元素与样式信息,计算大小、位置、布局;
Javascript引擎:解释js脚本,修改DOM、CSS。
最后使用图像库,将布局绘制成图像结果,也就是人眼看见的网页。

什么是DOM树呢?
DOM树是把 HTML 文档呈现为带有元素、属性和文本的树结构。比如以下HTML将被解析成如下DOM树:

使用 DOM 给 JS 开放的接口,可以用用 JS 操作 DOM 对象的属性。这里列举一些常见的 DOM 方法:

调用这些 DOM 方法,对 DOM 的修改,最终会体现在绘图上,也就是肉眼可见的网页变化。DOM的标准也在不断在升级:
DOM level 1、DOM level 2、DOM level 3、DOM level 4...



浏览器是一个很复杂的工程,不仅要去支持不同时候的DOM标准,而且不同的浏览器为了让解析的速度变得更快,让用户使用得更方便,在不断地增加新功能。从13年的新闻来看,Chrome 浏览器的代码应该至少有1000万行。

代码越多,开发的人员越多,就容易出现安全问题。接着介绍一下浏览器的漏洞类型,我自己的分类方法,不一定合理。
浏览器漏洞类型
第一类漏洞是信息泄漏漏洞,有以下几种场景:
比如老的IE浏览器可以用 JS 检测是否存在某文件。这样会泄漏用户是否安装了杀毒软件,以便进行下一步操作。
有些信息泄漏漏洞会泄漏内存的信息,攻击者可能使用泄漏的信息来绕过操作系统的保护机制,比如:ASLR、DEP 等等。
还有一类信息泄漏漏洞:UXSS,通用跨域漏洞。这种跨越域隔离策略的漏洞,可以在后台偷偷地打开其它域的网页,把你在其它网站上的数据偷走。

第二类漏洞是内存破坏漏洞:
内存破坏漏洞又可以细分为释放后重用漏洞(UAF),越界读写漏洞,类型混淆漏洞。越界读写漏洞比较神,他也能用来泄漏内存信息,所以越界读写漏洞非常好利用。
第三类漏洞,是国产浏览器的一些神漏洞,特权域 XSS+特权域 API:
比如搜狗浏览器浏览网页可下载任意文件到任意位置,重启之后,电脑可能被完全控制。百度浏览器可静默安装插件,且存在目录穿越漏洞。解压缩到启动目录,重启之后,电脑被完全控制。
利用这些浏览器漏洞可以做什么可怕的事情呢?
想像一下:
打开一个网页,完全控制你的电脑,APT攻击;
打开一个网页,完全控制你的手机,监听通话短信;
打开一个网页,越狱你的游戏机,玩盗版游戏;
打开一个网页,偷走你京东帐号、控制微博帐号…….
我们曾经抓到一个打 DDoS 的嫌疑人,他控制了200个肉鸡,接单打 DDoS。这200个肉鸡每天给他创造2000块的收入,如果有一套组合的浏览器0day+一个大站 Webshell,一天上千的肉鸡非常简单,日入万元不是梦,哈哈。。。
浏览器漏洞挖掘方法
那怎么挖掘浏览器漏洞呢?
第一种方法,人工
像Chrome 和 Webkit 这些是开源的,通过理解代码逻辑来找 Bug。比如 marius.mlynski 读 Chrome 代码发现数十个 UXSS 漏洞,每个漏洞Google奖励 7500 美元。
国产浏览器的漏洞大多是人工测试出来的,用自己的经验,逆向分析,手工测试。
第二种方法,自动化 Fuzz
用机器代替人来自动化挖漏洞。
有一些开源的框架可以学习:Grinder、Fileja、funfzz等。我们来看一下一个Fuzz框架是怎样实现的。

简单地说就是控制浏览器去加载你生成的测试样本,捕捉导致浏览器崩溃的样本,传回服务器作下一步分析。今天给大家分享一个最简单的Fuzz框架,一行代码,启动调试器打开样本生成器网页:
windbg -c “!py chrome_dbg_test.py” -o “C:\Program Files\Google\Chrome\Application\chrome.exe --js-flags=”--expose-gc" --no-sandbox --disable-seccomp-sandbox --allow-file-access-from-files --force-renderer-accessibility http://127.0.0.1/fuzzer.php
解释上面的命令:
使用windbg调试启动chrome打开样本生成器http://127.0.0.1/fuzzer.php
http://127.0.0.1/fuzzer.php生成测试样本并切换样本。
一个最简单调试器,十几行代码,pydbg 是 windbg 的一个插件,使用它可以编程控制 windbg。
比如用这段代码,监控调试进程产生的调试事件:
while True:
exc = e(".lastevent")
print exc
if exc.find("Exit process") > 0:
os.system("taskkill /F /IM windbg.exe")
观察windbg收到的调试事件,如果是退出进程事件,那么把windbg退出(同时chrome进程也退出了)。同理,如果windbg收到的调试事件是读写内存异常,那就是一个有效崩溃。
这时候你只需要执行windbg命令r,k,把结果传回服务器就完成了一个崩溃信息的收集了。
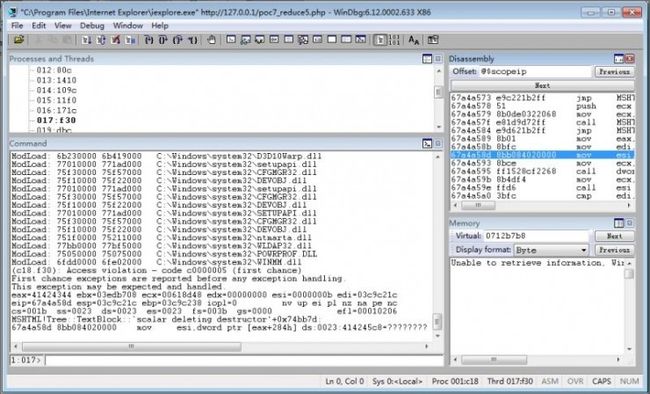
要想挖掘浏览器漏洞,推荐大家去分析以往浏览器的漏洞,收集一些POC,这样能更好地理解浏览器漏洞形成的原因以及调试分析方法。来看一个典型IE漏洞的POC:

所以我们的目标是怎样去生成有效的、复杂的、测试用例,让浏览器崩溃。
我们需要去构建 fuzz 生成算法用的字典,通常可以写爬虫到 MSDN、MDN、W3C 去抓取,还有可以用 IDA 分析 mshtml 找隐藏的属性键值,还可以看浏览器源码的头文件。我们需要去构建全面的字典,去覆盖浏览器的各个特性。

网上也有些自动构建字典的方法,可以参考
var elements = [“abbr”, “acronym”, “address”, “article”, “aside”, “b”……];
for (var i = 0; i < elements.length; i++) {
var element = document.createElement(elements[i]);
for (var key in element) {
if (typeof element[key] == "function") {
function_list.push(key);
}
}
构建出来的字典像这样:

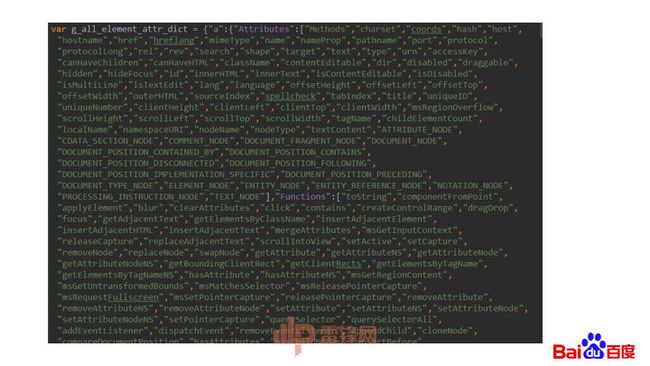
再来一个生成算法,用一个CSS生成算法来举例,使用刚才收集回来的字典,随机生成测试用的CSS。

好了,有了源材料和随机生成方法,现在你可以生成测试样本了。

然而还有一个大问题:
如果只是这样随机生成,跑一年有可能会出来一个有效的崩溃,这是个很可悲的事情。为什么????
一是因为测试的总样本集非常大,比如一共有110个html标签的类型,如果我们随机创建10个,那就是110的10次方种可能,这是个超级大的数,大到你可能永远都跑不完,二是前辈们可能10年前就跑过了,能发现的问题早就报告修复完了。
所以FUZZ的核心是样本生成算法。
我们需要新的样本生成策略,去发现别人发现不了的漏洞。曲博在 2014 BlackHat 分享了一个有意思的故事:
曲博他老婆的iPhone屏幕坏了,让曲博修,他拆开后,装上了新屏幕,差不多快好了,发现多了两个螺丝,摄像头不见了……
最终iPhone废了
QU BO 得出来的启示是:
工程师把东西拆开的时候容易犯错误,工程师把东西恢复的时候容易犯错误。
应用到fuzz这块,有两个策略,去做相反的事情,去改变初始的状态。比如:

我们应用这种想法也找到了一些漏洞:



其中在 document.execCommand("undo"); 这块我们至少收获了5枚漏洞。但是也有不少撞洞的情况。
所以我们需要样本生成策略,去发现别人发现不了的漏洞。
我们首先想的是把调用关系做得非常深,制造非常复杂的回调场景。比如以下这个POC,我们多次在事件响应函数中去触发另一个事件响应函数,最终导致解析出错:

看下这个崩溃的调用栈:

我们还可以去fuzz别人搞得少的方向。
Fuzz 别人搞得少的方向,第一个是 OBJECT。

CLSID:8856F961-340A-11D0-A96B-00C04FD705A2 应该是一个浏览器控件,浏览器控件是有自己独立的前进、后退功能的,如果与父页面的前进后退功能混用,会导致问题。
我们整理了系统中所有clsid:

在OBJECT这块我们至少也收获了5个漏洞。
Fuzz 别人搞得少的方向,第二个是unicode。

很少看见有人做fuzz的时候会随机的用一些unicode字符串来测试,我们在这块收获了EDGE一个越界读漏洞。
Fuzz 别人搞得少的方向,第三种是正则表达式。

fuzz别人搞得少的方向,第四种是JS解析引擎。

现在JS引擎的内存破坏漏洞越来越多了。我们在这块也挖到不少漏洞,由于目前还都是 0day 的状态,所以不拿我们自己发现的 POC 举例,拿一个 Google Project Zero 分开的 POC 给大家看看长什么样:

Fuzz 别人搞得少的方向,第五种是混合生成。
现在很多人生成的fuzz样本都是用JS生成的,但是对HTML的初始状态关注并不多,比如我们在初始状态时加了N个复杂的表格嵌套,也发现了不少的问题。

去fuzz非常复杂的元素,比如表格、表单、Frame。
表格相关的各种元素都有特有方法,比如insertRow、moveRow、deleteRow,还有表单的特有的属性和方法,如果跟CSS结合,那么渲染起来就更加复杂了,比如下面这个POC:

通过fuzz非常复杂的元素,我们至少收获了10个漏洞。
去fuzz非常复杂的元素,还有CSS。CSS也有很多种操作方法,比如:
style,