详解:智能医学影像分析的前沿与挑战
[转] http://www.leiphone.com/news/201701/b7msIh0xvsuBliIr.html

雷锋网按:本文整理自雅森科技高级算法研究员杨士霆,在雷锋网硬创公开课上的演讲,主题为“智能医学影像分析的前沿与挑战”。
杨士霆,毕业于台湾长庚大学电机工程研究所博士班,主攻医学影像处理与应用。研究领域涉及医学影像处理,生物医学资讯,医用光学,类神经与模糊理论,功能性磁振造影,医学物理与生医统计。曾在台湾林口长庚医院,宁波杜比医疗负责影像算法开发工作,现任职于北京雅森科技发展公司,担任高级算法研究员。
公开课视频如下:
以下为雷锋网(公众号:雷锋网)整理的演讲主要文字内容(关注雷锋网医疗科技微信公众号“AIHealth”,回复“117”下载完整PPT):

本次公开课主要分为四部分:
一是医学成像的概念及其类型与方式,以及人工智能及深度学习等技术的介绍;
二是深度学习如何应用于医学影像处理等医疗领域;
三是深度学习目前遇到的困难与需要突破的方向;
最后是总结。
医学影像与人工智能
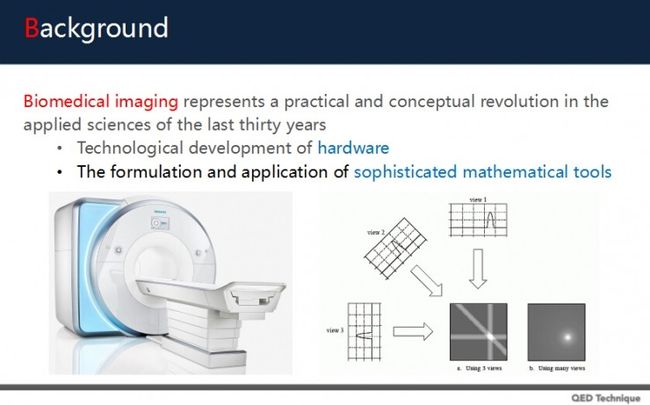
近三十年的医学成像,是一种实用性及创新概念的革命,主要包括两个部分:
一是硬件发展的突飞猛进,包括MR、CT等硬件的发展,这些成像技术让我们得到了很好的影像;
二是复杂数学工具的利用,通过这些方式可以对医学影像进行重建、分析与处理,从而得到清晰可见的医学图像。
这两个部分造就了成像上的进展。

医学成像主要分为两个形态:
一是结构性图像,它主要可以得到组织的结构性特征,但无法看到生物有机代谢的情况;
二是功能性图像,它可以提示代谢的衰变与下降,或功能性的疾病。
相比结构性图像,功能性图像的空间解析度较差。
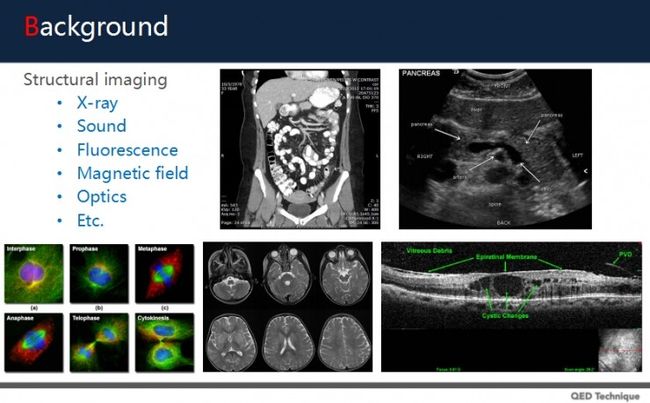
我们可以透过不一样的介质来形成图像,结构性成像包括:
X-ray,如血管摄影和电脑断层,它可以看到组织结构;
声音的方法,如超声成像;
荧光,它可以用来探讨组织和细胞的形状与结构;
磁场,如核磁共振,它可以看到脑组织和身体器官的结构;
光学,比如眼底图像,光学相干断层扫描,它可以侦探到身体的结构,帮助诊断。
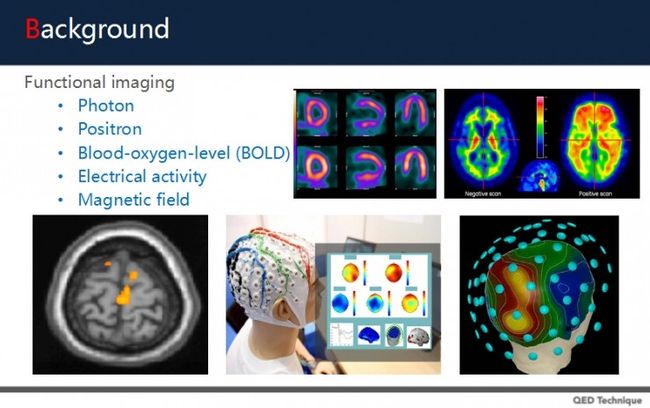
功能性图像有:
光子,如用单光子电脑断层扫描,可以看到代谢状况,不过没法看到组织结构;
正子,如正子断层扫描,它加上一些医学药物的应用,可以看到代谢情况,看到肿瘤和病灶;
血氧水平,如fMRI功能性磁共振;
电流活动,下中图是脑波图的方法,透过脑波图,拓扑到脑部对应位置,可以看到活动状态下脑部电流改变的状况;
磁场,与脑波图类似,通过脑磁图的方法,用磁场侦探微弱电流,可以感应出大脑中的功能性差异。
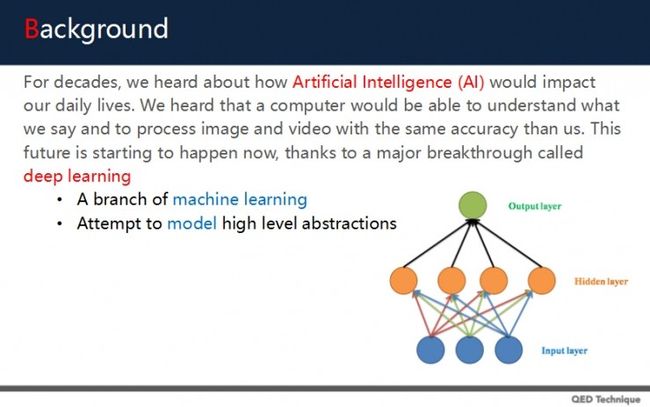
关于人工智能,我们一直听到它将对日常生活产生重要的影响。而如今,计算机已经可以像人类一样准确地处理图像与视频,甚至比人类表现还要好。这些突破主要来自深度学习。
关于深度学习,可以理解为它是机器学习的一个分支,其主要目的是模拟更高层次抽象思维。

深度学习主要是建构大量的抽象层,帮助将一些输入的讯号映射到更高层的表现方式。例如,处理图像中,输入的特征可以是每个像素,可以计算像素的强度,它可能是一组边缘,也可能是特定的轮廓与区域。透过这些方式可以让深度学习去达到我们的目的。
深度学习主要有非监督与半监督特征学习,它会分层进行特征提取。

在医学成像中,要做到精准诊断,对疾病进行评估,需要:
一借助影像设备获取图像,由于近几年影像设备的进步,它在诊断上取得了比较好的效果。
二是解读医学图像。现在主要依靠医师完成,但有一些问题需要克服,比如主观性,医师的经验和训练不同,在看医学图像时有不同方式的解读与定义;另外医师的经验不同,对同一组资料的解读有较大的差异;而且医师会疲劳,从而导致解读的错误。
三是检测出异常。
四是将想量测的位置进行量化,比如术前术后,让医师评估手术前后的差异时,要针对图像做量化,透过前后数据的差别,协助医师判断手术是否成功。
上面提到的四个主要问题,都可以通过深度学习的方式来促进诊断,即将需要治疗的地方做明确的辨识,辅助医师做更有效地诊断,找到病灶。
深度学习在医学影像上的应用

接下来要讲解深度学习技术在医学影像上的应用。目前医学影像领域的主要处理内容有:
CAD,即计算机辅助诊断,医师可以据此评估病人的治疗情况,以及术前术后的差别等。辅助诊断也可以通过图像分析的方法,找到肿瘤和癌症病灶。
图像分割,主要是对身体的组织做明确的分割。
图像配准与图像融合,这两者可以一起讲。我们知道,图像有结构性与功能性之分,后者图像空间解析度差,可以看到组织的代谢情况,但不知道位于组织中的位置。所以需要影像配准与融合,将不同类型的图像结合在一起,一个提供清晰的结构,一个提供代谢情况,这样可以了解到组织与器官的病变。
影像导引治疗。它可以分成两类,一是影像导引手术,比如做开脑手术时,癫痫病人会不自主地出现放电异常抽动,用药物抵制可能没效果,这就要在大脑中植入电极,而这样就需要引导的方法,将电极放到正确位置上。二是放射手术治疗,即放疗,它需要对肿瘤的位置做评估,因为放射线可以杀死癌细胞,也可能杀死正常细胞,所以要引导将放疗固定在正确的位置,这也就需要医学图像的应用。
最后是医学资料库的搜寻与获取,即如何从资料库中检索出想要的数据,这些可以通过深度学习的方法处理。

我们为什么要在医学图像上使用深度学习的方法呢?因为图像有不同形态,来自不同的组织,而如前所述,深度学习可以进行分析与处理,让一些人为误差得到调整。通过深度学习提取最主要的特征,它也可以对疾病分类,做图像分类与分割。
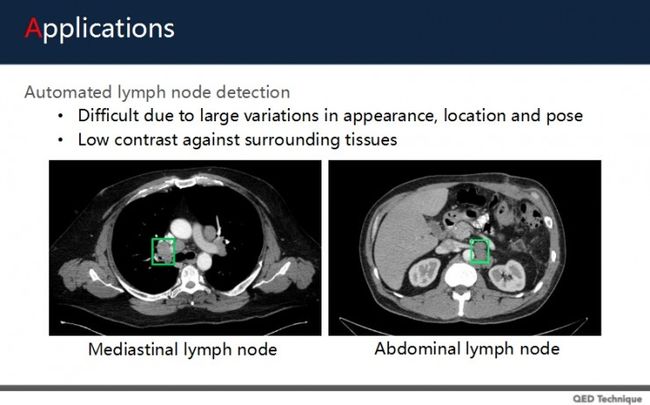
接下来讲讲深度学习的临床应用。
上图中的案例是全自动淋巴结检测。左边是纵隔的淋巴结,右边是腹部淋巴结。可以看到,图像标定出来的位置中,其实淋巴结有很大的差异,比如形状与位置不一定,它与周围的组织也非常类似。

过去传统的图像处理,是透过电脑断层图像,取得3D的立体影像,然后做影像上的处理分析与应用。比较新的方法是増强式3D Haar特征,建立整体完整的检测器,透过scanning window检测淋巴结。
但传统方法表现不佳,主要是维度上的限制。
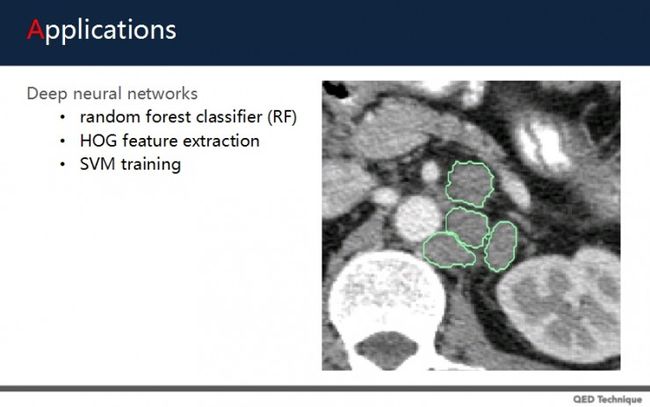
在前两年的一篇论文中,有人透过深度学习的方式自动检测淋巴结。做法是,首先通过随机森林分类器RF,检测出大概位置并做标定;然后将标定出来的淋巴结,根据矢状面、横切面、冠状面、三维角度,互相正交结合,创建出2.5维的空间投影立体特征。接下来,透过HOG特征提取方法,对空间投影图像进行向量特征截取。然后通过SVM训练方法,将取得的特征做加强和训练,然后自动检测出淋巴结位置。
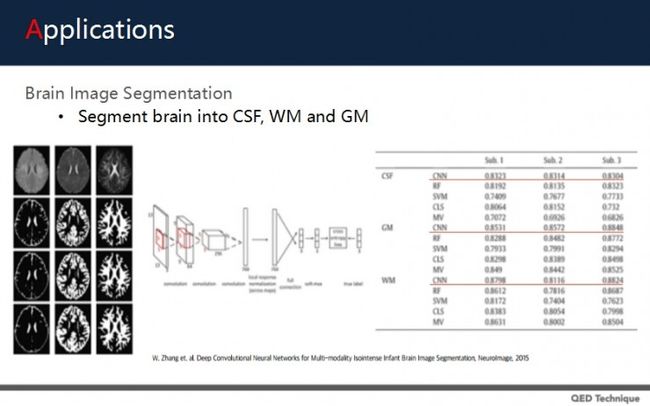
用深度学习的方法做分割,在2015年的一篇文章也有展现。它主要利用卷积神经网络CNN,自动将大脑灰质、白质、脑脊髓翼自动分割,从而分析大脑的病变。
这篇论文中利用深度学习将不同的病人的资料做分割,精确度都不错。

具体来说,作者用CNN将不同类型的MRI图像,做有效分割,精确分割灰质、白质、脑脊髓翼。
他们通过CNN,将图像分成一块块patch,然后对完整图像做学习,训练与分类。
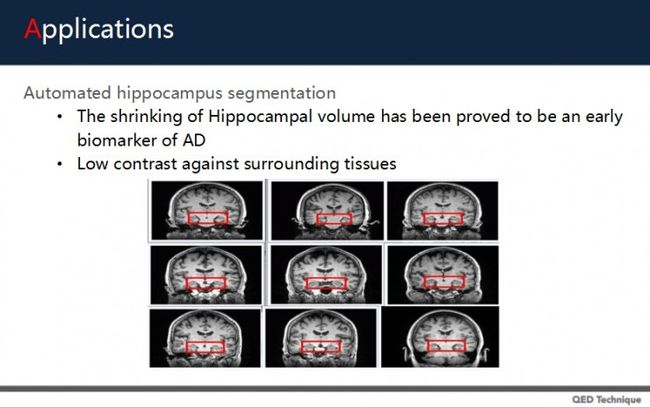
上面这个研究是海马回的分割。研究表明,海马回主要与记忆有关。上图是用手标定的海马回的位置,可以看出与淋巴结一样,它与临近组织很相近,分割有一定难度。
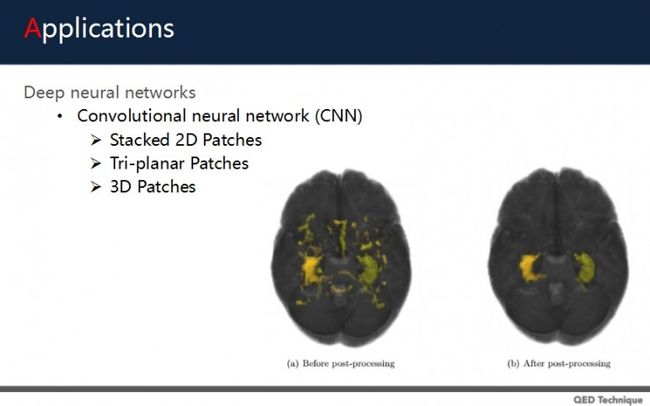
在2015年的一篇论文中,就有作者通过CNN,用2D patches、三平面patches,以及改良式3D patches的方法,将海马回进行深度学习,从而分割。左边是还没处理的情况,右是明确定位了海马回的位置。
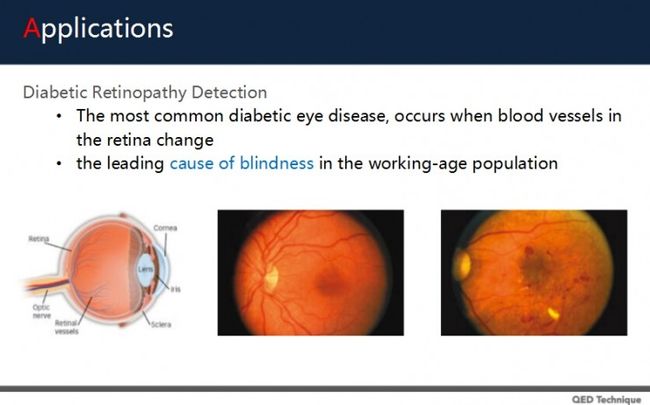
在光学图像上,这里的例子是糖尿病视网膜病变的检测。一般来说,糖尿病患者容易发生眼部疾病,视网膜血管也会有所改变。上面中间的图是正常情况,右边是患者图像。

所以,在一些研究中用CNN的方法,针对眼底图像进行糖尿病视网膜病变的辨识。已经可以判断严重的情况。
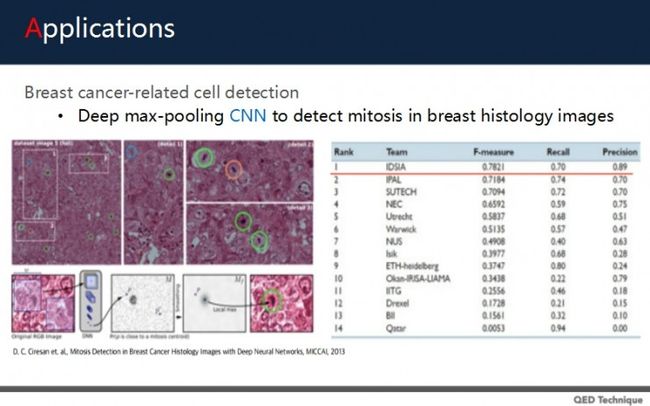
另外还有深度学习在细胞检测中的应用。比如2013年的一篇论文,主要是胸部癌症细胞的检测,标定的是细胞癌症,通过max-pooling CNN,针对胸部组织图像做有丝分裂的分析。结果显示,精确度达到了将近9成。

上图就是针对组织图像的分析,得到的有线分裂的情况。
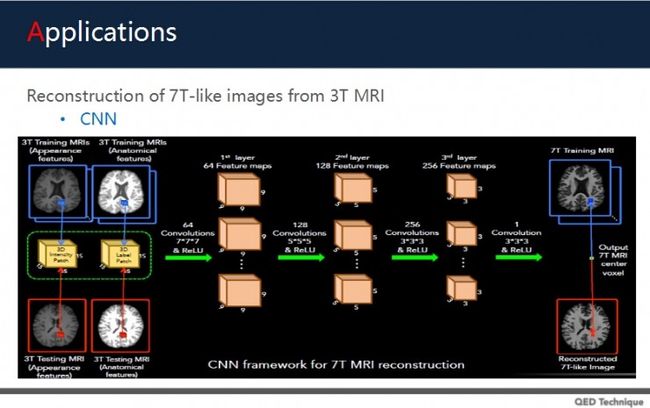
另外,还有个很好玩的例子。CNN除了做图像识别,还可以将3T MRI图像透过CNN网络,重建出类7T MRI的图像。所谓T是指特斯拉,即磁场感应强度。我们医学中常见的核磁机器是1T和1.5T,而7T是磁场强达7特斯拉,这种设备昂贵,需要很多的费用,但7T图像的性噪比强。所以,研究中想通过深度学习将3T变7T图像。
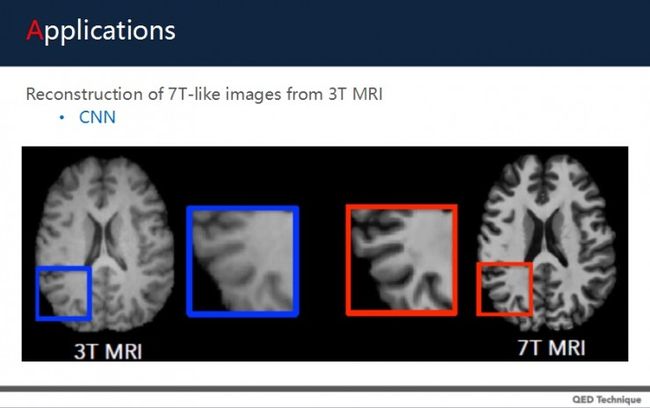
上图可以看出,左边3T图像中,脑部边缘有些模糊,但处理过后的右图变得清晰了。这是用低成本的方法做重建。
智能医学影像分析的挑战

以上就是深度学习在医学影像上的应用案例。那深度学习在应用当中,还有哪方面的挑战呢?
目前论文的实验,主要是探讨结构效度的评估,一般是在实验架构的基础上,评估CNN配合哪一个patch,哪些在实验中是好是坏。但没有思考,在实际使用深度学习的过程当中,表现是否如预期想的那么好。
使用模型当中,也常常选择很多不一样类型的特征去训练,这个过程中怎么样找出好的有效特征?另外,在建构深度学习模型中,如何透过那么多参数做调整。这些都是深度学习的挑战。

另外,想要发展一个有效的深度理论学习模型,要基于经验资料,去调试与评估网络的效果,这也是主要挑战的目标。在这个过程中,要评估与测量模型复杂的程度,比如:
一是深度学习过程中有神经元的概念,那到底要多少数量?到底要多少patch?
二是还要考虑计算单元的形态,要放置多少的隐藏层、卷积层?这部分是深度学习要思考的。
三是考虑到模型的架构和拓扑的结构,怎么样将CNN与不同类型的机器学习模型,做互相的结合与比较?
四是是怎么样有效地将模型产生与建立起来?
最后是学习中效率问题。深度学习早在80年代就有所发展,但由于计算机的限制,其发展也并不如意。最近计算力的进步才将机器学习的机制建立起来。回过头来看,到了如今的情况,硬件越来越好,那怎么样让学习效率做更有效的分配或调整呢?怎么样将学习效率调整到比较好的阶段,达到很好的结果?这都是深度学习的挑战。
另外,也需要采集数据的量到底需要有多大?听到了很多大数据的概念,但MR图像可能是128*128维度,也有很多的训练。大的数据量的分析与统计都会影响到大数据分析与学习。怎么样做权衡和评估的一个挑战。

我们需要融合经验资料,建构深度的理论学习模型,以取得好的评估效果。要做到这些,我们就需要定义一个理论策略,通过这个策略,去评估、调试模型。
在这个过程中,有一个常规化的机制。即最简单的输入-隐藏-处理-输出训练模型。但我们如何调整顺序,使得对模型的调试更加明确、更加常规化,也是值得探讨的地方。
我们在做深度学习的过程中,有个很一致的概念:我们都希望多放些层,或者减少内容。有时候,可能需要多一些特殊的加成层。但如何明确定义这个概念,使其常规化,也是我们要挑战的目标。
另一个挑战是:我们在做深度学习的过程中,最常使用的是非深度学习的架构。那我们要怎样评估这个架构,找出一个好方法呢?
最后,是关于计算效率。我们先前也有提到,机器效能和数据都会直接或间接影响计算效率。如何取得平衡点,是之后的深度学习研究中很好的一个研究方向。

我们做一个最简单的总结:深度学习主要用来做什么?
深度学习有很大的潜力,能分析大量资料,通过学习给出分析结论和答案。所以其应用广泛,不仅是在医学影像领域,在其他领域也有很大的贡献。并且在我们分析大数据时,深度学习可以为我们提供精简信息。深度学习的可发展性还是非常大的,还有很多东西值得去挑战,值得大家一起去探讨。
在2016年RANA会议上,深度学习、智能学习非常热门,医生们意识到深度学习可以辅助诊断,甚至能帮他们找出更有效的治疗方法,并且最近的一些会议中,我们都可以发现深度学习、智能分析的庞大市场和发展潜力
我相信,深度学习在智能医学影像分析中一定有很大的价值。
雷锋网原创文章,未经授权禁止转载。详情见转载须知。