什么是Okio
Retrofit,OkHttp,Okio 是 Square 的开源的安卓平台网络层三板斧,它们逐层分工,非常优雅地解决我们对网络请求甚至更广泛的 I/O 操作的需求。其中最底层的 Okio 堪称小而美,功能也更基础,应用更广泛。它的主要功能封装在ByteString和Buffer这两个类中。
和JDK不同,Okio不区分字节流和字符流,具体的做法就是把比特数据都交给Buffer管理,然后Buffer实现BufferedSource和BufferedSink这两个接口,最后通过调用Buffer相应的方法对数据进行读写和编码。
PS:本文中设计的类大量运用链表操作,不熟悉的先补一下。
Okio的使用
下面是okio读文件的例子:
public static void main(String[] args) {
File file = new File("test.txt");
try {
readString(new FileInputStream(file));
} catch (IOException e) {
e.printStackTrace();
}
}
public static void readString(InputStream in) throws IOException {
BufferedSource source = Okio.buffer(Okio.source(in)); //创建BufferedSource
String s = source.readUtf8(); //以UTF-8读
System.out.println(s); //打印
source.close();
}
Okio是对Java底层io的封装,所以底层io能做的Okio都能做。
上面的大体流程如下:
第一步,首先是调用okio的source(InputStream in)方法获取Source对象
第二步,调用okio的buffer(Source source)方法获取BufferedSource对象
第三步,调用BufferedSource的readUtf8()方法读取String对象
第四步,关闭BufferedSource
Sink和Source
在JDK里面有InputStream和OutputStream两个接口,Source和Sink类似于InputStream和OutputStream,是io操作的顶级接口类,这两个接口均实现了Closeable接口。所以可以把Source简单的看成InputStream,Sink简单看成OutputStream,但是它们具有一些新特性:
1.超时机制,所有的流都有超时机制;
2.API 非常简洁,易于实现:Source 和 Sink 的 API 非常简洁,为了应对更复杂的需求,Okio 还提供了 BufferedSource和 BufferedSink 接口,便于使用(按照任意类型进行读写,BufferedSource 还能进行查找和判空等);
3.不再区分字节流和字符流,它们都是数据,可以按照任意类型去读写;
4.便于测试,Buffer 同时实现了 BufferedSource 和 BufferedSink 接口,便于测试;
结构图如下图:
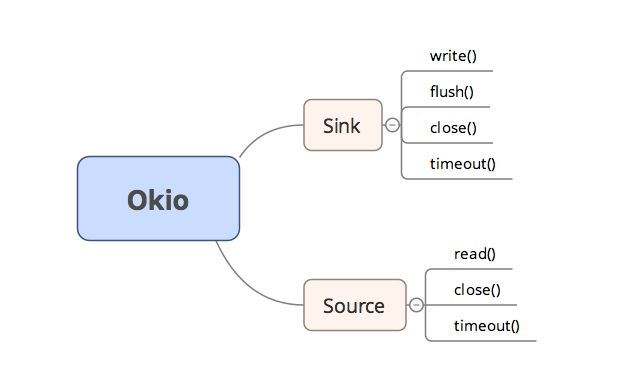
Sink和Source接口
输出流Sink接口:
public interface Sink extends Closeable, Flushable {
/** Removes {@code byteCount} bytes from {@code source} and appends them to this. */
//基础的写入方法,从source中写入字节
void write(Buffer source, long byteCount) throws IOException;
/** Pushes all buffered bytes to their final destination. */
@Override void flush() throws IOException;
/** Returns the timeout for this sink. */
Timeout timeout();
/**
* Pushes all buffered bytes to their final destination and releases the
* resources held by this sink. It is an error to write a closed sink. It is
* safe to close a sink more than once.
*/
@Override void close() throws IOException;
}
输入流Source接口:
public interface Source extends Closeable {
/**
* Removes at least 1, and up to {@code byteCount} bytes from this and appends
* them to {@code sink}. Returns the number of bytes read, or -1 if this
* source is exhausted.
*/
//读操作,将字节读入sink
long read(Buffer sink, long byteCount) throws IOException;
/** Returns the timeout for this source. */
Timeout timeout();
/**
* Closes this source and releases the resources held by this source. It is an
* error to read a closed source. It is safe to close a source more than once.
*/
@Override void close() throws IOException;
}
它们的子接口分别为BufferedSink和BufferedSource.
BufferedSink定义的方法为一系列写方法:

相应的BufferedSource定义了一系列读方法:

他们的实现类分别是RealBufferedSink和RealBufferedSource。因为RealBufferedSink和RealBufferedSource是一一对应的,我就讲解RealBufferedSink了,RealBufferedSource这里就不仔细讲解了,着重分析RealBufferedSink:
final class RealBufferedSink implements BufferedSink {
public final Buffer buffer = new Buffer();//真正的实现是通过buffer实现
public final Sink sink;//被装饰的sink
boolean closed;
RealBufferedSink(Sink sink) {
if (sink == null) throw new NullPointerException("sink == null");
this.sink = sink;
}
@Override public void write(Buffer source, long byteCount)
throws IOException {
if (closed) throw new IllegalStateException("closed");
buffer.write(source, byteCount);
emitCompleteSegments();
}
@Override public BufferedSink write(ByteString byteString) throws IOException {
if (closed) throw new IllegalStateException("closed");
buffer.write(byteString);
return emitCompleteSegments();
}
...
}
可以看出一系列的写方法都是通过buffer实现的,。
Segment和SegmentPool分析
Segment
Segment(片段)是Buffer的基本单元。Buffer将数据分割成一块块的片段,每个片段内维护定长字节数组,同时有前节点和后继节点,Buffer维护片段的双向链表。这样兼具连续读和插入、删除效率高的优点。下面看看Segment属性:
/** The size of all segments in bytes. */
static final int SIZE = 8192;//字节大小
/** Segments will be shared when doing so avoids {@code arraycopy()} of this many bytes. */
//用分享的方式避免复制数组
static final int SHARE_MINIMUM = 1024;
//维护的字节数组
final byte[] data;
/** The next byte of application data byte to read in this segment. */
//第一个可读的位置
int pos;
/** The first byte of available data ready to be written to. */
//第一个可写的位置,一个Segment的可读数据量为limit - pos
int limit;
/** True if other segments or byte strings use the same byte array. */
//当前存储的data数据是其它对象共享的则为真
boolean shared;
/** True if this segment owns the byte array and can append to it, extending {@code limit}. */
//自己持有标记
boolean owner;
/** Next segment in a linked or circularly-linked list. */
//前驱节点
Segment next;
/** Previous segment in a circularly-linked list. */
//后继节点
Segment prev;
总结一下就是:
SIZE就是一个segment的最大字节数,其中还有一个SHARE_MINIMUM,这个涉及到segment优化的另一个技巧,共享内存,然后data就是保存的字节数组,pos,limit就是开始和结束点的index,shared和owner用来设置状态判断是否可读写,一个有共享内存的sement是不能写入的,owner和shared互斥,pre,next就是前置后置节点。
Segment的构造方法
//无参构造
Segment() {
this.data = new byte[SIZE];
this.owner = true;
this.shared = false;
}
//带参构造
Segment(byte[] data, int pos, int limit, boolean shared, boolean owner) {
this.data = data;
this.pos = pos;
this.limit = limit;
this.shared = shared;
this.owner = owner;
}
常用方法:
1.pop:
/**
* Removes this segment of a circularly-linked list and returns its successor.
* Returns null if the list is now empty.
*/
public @Nullable Segment pop() {
Segment result = next != this ? next : null;//取后继节点next
prev.next = next;//连接当前的prev和next
next.prev = prev;
//断开与循环链表的联系
next = null;
prev = null;
return result;//返回下个segment
}
2.push方法
/**
* Appends {@code segment} after this segment in the circularly-linked list.
* Returns the pushed segment.
*/
public Segment push(Segment segment) {
//segment加入到本节点后面
segment.prev = this;
segment.next = next;
next.prev = segment;
next = segment;
return segment;//返回新加入的segment
}
- writeTo方法
/** Moves {@code byteCount} bytes from this segment to {@code sink}. */
//将本片段的byteCount字节数据移到sink片段
public void writeTo(Segment sink, int byteCount) {
//自己有写入的权利?
if (!sink.owner) throw new IllegalArgumentException();
//目标片段的可写位置到末尾的空间不够,需要先向前移动目标片段
if (sink.limit + byteCount > SIZE) {
// We can't fit byteCount bytes at the sink's current position. Shift sink first.
//sink.shared不能编辑
if (sink.shared) throw new IllegalArgumentException();
if (sink.limit + byteCount - sink.pos > SIZE) throw new IllegalArgumentException();//pos字段可能因为在片段被读取出数据后,pos会后移,pos之前的空间也可用,所以这里先判断移动后仍然空间是否足够,如果不够抛异常
//sink.pos-> sink.limit之间的数据移动到:0->sink.limit - sink.pos位置
System.arraycopy(sink.data, sink.pos, sink.data, 0, sink.limit - sink.pos);
//可读起始位置为0,可写位置前移
sink.limit -= sink.pos;
sink.pos = 0;
}
//本片段的数据复制到sink
System.arraycopy(data, pos, sink.data, sink.limit, byteCount);
//更新sink的写位置
sink.limit += byteCount;
//更新本片段的读位置
pos += byteCount;
}
4.压缩机制compact方法.
因为每个segment的片段size是固定的,为了防止经过长时间的使用后,每个segment中的数据被分割的十分严重,可能一个很小的数据却占据了整个segment,所以有了一个压缩机制。
/**
* Call this when the tail and its predecessor may both be less than half
* full. This will copy data so that segments can be recycled.
*/
public void compact() {
//双向循环链表只有一个节点,不用压缩
if (prev == this) throw new IllegalStateException();
//前驱几点不可写
if (!prev.owner) return; // Cannot compact: prev isn't writable.
//本片段的数据大小
int byteCount = limit - pos;
//计算前驱节点的可用空间,如果正在共享,则为SIZE - prev.limit,否则还要加上prev.pos前面的可用空间
int availableByteCount = SIZE - prev.limit + (prev.shared ? 0 : prev.pos);
//可用空间不够
if (byteCount > availableByteCount) return; // Cannot compact: not enough writable space.
//当前数据写入前驱节点
writeTo(prev, byteCount);
pop();//释放当前片段
SegmentPool.recycle(this);//加入片段回收池
}
总结下上述代码:如果前面的Segment是共享的,那么不可写,也不能压缩,然后判断前一个的剩余大小是否比当前打,如果有足够的空间来容纳数据,调用前面的writeTo方法写入数据,写完以后,移除当前segment,然后回收segment。
5.split()方法(共享机制)
/**
* Splits this head of a circularly-linked list into two segments. The first
* segment contains the data in {@code [pos..pos+byteCount)}. The second
* segment contains the data in {@code [pos+byteCount..limit)}. This can be
* useful when moving partial segments from one buffer to another.
*
* Returns the new head of the circularly-linked list.
*/
public Segment split(int byteCount) {
if (byteCount <= 0 || byteCount > limit - pos) throw new IllegalArgumentException();
Segment prefix;
// We have two competing performance goals:
// - Avoid copying data. We accomplish this by sharing segments.
// - Avoid short shared segments. These are bad for performance because they are readonly and
// may lead to long chains of short segments.
// To balance these goals we only share segments when the copy will be large.
//大于SHARE_MINIMUM才做共享,避免小片段被共享,浪费资源
if (byteCount >= SHARE_MINIMUM) {
prefix = sharedCopy();//copy片段,share标记为true
} else {
//从片段池中回收
prefix = SegmentPool.take();
//copy部分数组到新片段
System.arraycopy(data, pos, prefix.data, 0, byteCount);
}
//新片段可写位置
prefix.limit = prefix.pos + byteCount;
//当前片段可读位置设置
pos += byteCount;
//新片段push到前面
prev.push(prefix);
return prefix;//返回新建片段
}
SegmentPool
顾名思义SegmentPool是片段回收池,上面我们看到了SegmentPool的recycle和take方法,分别为存和取操作,下面看看它的具体实现:
/**
* A collection of unused segments, necessary to avoid GC churn and zero-fill.
* This pool is a thread-safe static singleton.
*/
final class SegmentPool {
/** The maximum number of bytes to pool. */
// TODO: Is 64 KiB a good maximum size? Do we ever have that many idle segments?
static final long MAX_SIZE = 64 * 1024; // 64 KiB.
/** Singly-linked list of segments. */
//片段单链表
static @Nullable Segment next;
/** Total bytes in this pool. */
static long byteCount;
private SegmentPool() {
}
static Segment take() {
synchronized (SegmentPool.class) {
if (next != null) {
//取表头片段
Segment result = next;
next = result.next;
result.next = null;
//byteCount-size
byteCount -= Segment.SIZE;
return result;
}
}
//如果单链表为空,则新建片段
return new Segment(); // Pool is empty. Don't zero-fill while holding a lock.
}
static void recycle(Segment segment) {
//segment没有从循环链表中断开,不能回收,抛异常
if (segment.next != null || segment.prev != null) throw new IllegalArgumentException();
//segment为共享片段,不能回收
if (segment.shared) return; // This segment cannot be recycled.
//同步操作
synchronized (SegmentPool.class) {
//容量超出限制
if (byteCount + Segment.SIZE > MAX_SIZE) return; // Pool is full.
//加入单链表
byteCount += Segment.SIZE;
segment.next = next;
//清空可用数据
segment.pos = segment.limit = 0;
next = segment;
}
}
}
代码比较简单,存和取都是处理单链表,看着注释应该容易明白,不再赘述。
ByteString
ByteString为不可变比特序列,官方文档说可以把它看成string的远方亲戚,且这个亲戚符合人工工学设计,逼格是不是很高。不过简单的讲,他就是一个byte序列(数组),以制定的编码格式进行解码。目前支持的解码规则有hex,base64和UTF-8等,机智如你可能会说String也是如此。是的,你说的没错,ByteString 只是把这些方法进行了封装。免去了我们直接输入类似的"utf-8"这样的错误,直接通过调用utf-8格式进行解码,还做了优化,在第一次调用uft8()方法的时候得到了一个该解码的String,同时在ByteString内部还保留了这个引用,当再次调用utf-8()的时候,则直接返回这个引用。
不可变对象有许多好处,首先本质是线程安全,不要求同步处理,也就是没有锁之类的性能问题,而且可以被自由的共享内部信息,当然坏处就是要创建大量类的对象,咱们看看ByteString的属性
static final char[] HEX_DIGITS =
{ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f' };
private static final long serialVersionUID = 1L;
/** A singleton empty {@code ByteString}. */
public static final ByteString EMPTY = ByteString.of();
final byte[] data;//字节数组
transient int hashCode; // Lazily computed; 0 if unknown.
//string数据,和字节数组互相转换没有开销,不会参与序列化和反序列化
transient String utf8; // Lazily computed.
ByteString(byte[] data) {
this.data = data; // Trusted internal constructor doesn't clone data.
}
对外的创建对象方法是of()方法:
/**
* Returns a new byte string containing a clone of the bytes of {@code data}.
* 重新创建一个byte数组。clone一个数组的原因很简单,我们确保ByteString的data指向byte[]没有被其他对象所引用,否则就容易破坏ByteString中存储的是一个不可变化的的比特流数据这一约束。
*/
public static ByteString of(byte... data) {
if (data == null) throw new IllegalArgumentException("data == null");
return new ByteString(data.clone());
}
/**
* Returns a new byte string containing a copy of {@code byteCount} bytes of {@code data} starting
* at {@code offset}.
*/
public static ByteString of(byte[] data, int offset, int byteCount) {
if (data == null) throw new IllegalArgumentException("data == null");
//边界检查
checkOffsetAndCount(data.length, offset, byteCount);
//局部拷贝
byte[] copy = new byte[byteCount];
System.arraycopy(data, offset, copy, 0, byteCount);
return new ByteString(copy);
}
public static ByteString of(ByteBuffer data) {
if (data == null) throw new IllegalArgumentException("data == null");
byte[] copy = new byte[data.remaining()];
data.get(copy);
return new ByteString(copy);
}
utf8()懒加载:
/** Constructs a new {@code String} by decoding the bytes as {@code UTF-8}. */
public String utf8() {
String result = utf8;
// We don't care if we double-allocate in racy code.
return result != null ? result : (utf8 = new String(data, Util.UTF_8));
}
Buffer
简介
Okio的核心类,前面讲到的RealBufferedSink、RealBufferedSource的读写功能都是通过Buffer实现的,它实现了BufferedSource, BufferedSink接口,它和前面提到的Sink\Source的实现关系如下:

属性如下:
public final class Buffer implements BufferedSource, BufferedSink, Cloneable, ByteChannel {
private static final byte[] DIGITS =
{ '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'a', 'b', 'c', 'd', 'e', 'f' };
static final int REPLACEMENT_CHARACTER = '\ufffd';
@Nullable Segment head;//Segment循环链表头
long size;//当前的数据量
]'0[
public Buffer() {
}
}
Buffer的读操作
先看最基本的读字节操作。
@Override public byte readByte() {
if (size == 0) throw new IllegalStateException("size == 0");
//从头片段开始读
Segment segment = head;
//取可读位置
int pos = segment.pos;
//limit-1为可读的最后位置
int limit = segment.limit;
byte[] data = segment.data;
//读取字节,pos后移
byte b = data[pos++];
size -= 1;
//读完数据发现该片段数据已经读完,弹出并回收片段
if (pos == limit) {
//head指向下一个片段
head = segment.pop();
SegmentPool.recycle(segment);
} else {
//当前片段更新可读位置
segment.pos = pos;
}
return b;
}
通过源码我们发现,读取过程中,片段的可读位置一直后移,读完数据后,判断pos == limit:如果为true,表明该片段数据已经读完,需要弹出此片段并回收它,然后head指向循环链表的下一个片段;如为false则更新当前片段的可读位置。简单来说,读操作都是从head片段开始读的,读完一个片段就回收它,未读完就将可读位置后移1位。如下图为Buffer和SegementPool的结构:

了解了读字节操作,读整形数方法就更容易理解了,其他读操作也是类似。
@Override public int readInt() {
//整个buffer的size必须大于4
if (size < 4) throw new IllegalStateException("size < 4: " + size);
//取头节点
Segment segment = head;
//可读位置
int pos = segment.pos;
//可读边界
int limit = segment.limit;
// If the int is split across multiple segments, delegate to readByte().
//如果小于4,借助readByte跨片段读满四个字节
if (limit - pos < 4) {
return (readByte() & 0xff) << 24
| (readByte() & 0xff) << 16
| (readByte() & 0xff) << 8
| (readByte() & 0xff);
}
//在当前片段中从高到低读取4字节
byte[] data = segment.data;
int i = (data[pos++] & 0xff) << 24
| (data[pos++] & 0xff) << 16
| (data[pos++] & 0xff) << 8
| (data[pos++] & 0xff);
size -= 4;//读完size-4
//下面的操作和readByte一样,片段数据被读完,回收片段
if (pos == limit) {
head = segment.pop();
SegmentPool.recycle(segment);
} else {
segment.pos = pos;
}
return i;
}
Buffer的写操作
还是先看writeByte方法:
@Override public Buffer writeByte(int b) {
//从尾节点追加写入,这里写入一个字节,所以传入容量为1
Segment tail = writableSegment(1);
//尾部片段字节数组写入byte
tail.data[tail.limit++] = (byte) b;
size += 1;//size++
return this;
}
先会调用writableSegment方法,顾名思义这个方法是获得一个可以写入数据的尾部片段,看看具体实现:
/**
* Returns a tail segment that we can write at least {@code minimumCapacity}
* bytes to, creating it if necessary.
* minimumCapacity为最小写入容量
*/
Segment writableSegment(int minimumCapacity) {
//写入大小越界处理
if (minimumCapacity < 1 || minimumCapacity > Segment.SIZE) throw new IllegalArgumentException();
//如果片段链表为空,创建单节点循环双向链表
if (head == null) {
//从回收池中取片段
head = SegmentPool.take(); // Acquire a first segment.
return head.next = head.prev = head;
}
//取尾片段
Segment tail = head.prev;
//判断tail片段容量够否?是不是可写?
if (tail.limit + minimumCapacity > Segment.SIZE || !tail.owner) {
//如果不满足写入条件,则从回收池中取,并加到尾部
tail = tail.push(SegmentPool.take()); // Append a new empty segment to fill up.
}
//满足写入条件,返回尾部片段
return tail;
}
PS:从上面我们也可以看到,Buffer的写方法构造了片段的循环链表结构,而前面讲的Segment仅仅是构建双向链表。再看writeInt方法:
@Override public Buffer writeInt(int i) {
Segment tail = writableSegment(4);//tail片段是可以写入的,容量够用
byte[] data = tail.data;//取tail的数据
int limit = tail.limit;//取写入位置
//写入顺序和读顺序一直,先搞位字节,后低位字节
data[limit++] = (byte) ((i >>> 24) & 0xff);
data[limit++] = (byte) ((i >>> 16) & 0xff);
data[limit++] = (byte) ((i >>> 8) & 0xff);
data[limit++] = (byte) (i & 0xff);
tail.limit = limit;//更新接入位置
size += 4;//size+4
return this;
}
小结
以上是Okio底层主要的核心类,另外Okio针对Socket实现了异步超时机制,以供OkHttp调用,截止目前数据其实一直围绕Buffer转悠,还未与InputStrean/OutputStream打交道,限于篇幅今天就到这里,下一篇我们接着学习它的异步超时机制和完整的读写流程。