一、sort
sort命令用于将文本文件内容以行排序
sort [选项参数] [-o<输出文件>] [-t<分隔字符>] [+<起始栏位> -<结束栏位>] [文件]
-c ===> 检查文件是否已经按照顺序排序
-b ===> 忽略每行前面开始处的空格字符
-i ===> 排序时,除了040至176之间的ASCII字符外,忽略其他的字符
-d ===> 排序时,处理英文字母、数字及空格字符外,忽略其他的字符
-f ===> 排序时,将小写字母视为大写字母
-M ===> 将前面3个字母依照月份的缩写进行排序
-n ===> 依照数值的大小排序
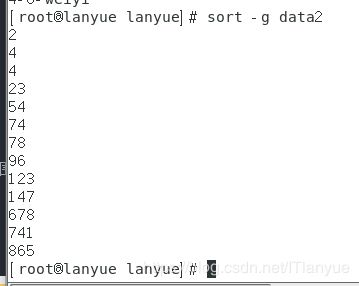
-g ===> 按通用数值排序,支持科学计数法
-r ===> 以相反的顺序来排序
-u ===> 对排序后的数据去重
-m ===> 将几个排序好的文件进行合并
-t ===> <分隔字符> 指定排序时所用的栏位分隔字符
-k ===> POS1[,POS2] (配合-t)排序从POS1开始,若指定POS2,则POS2结束,否则以pos1排序
+ ===> <起始栏位> -<结束栏位> 以指定的栏位来排序,范围由起始栏位到结束栏位的前一栏位(从0开始)
-o ===> <输出文件> 将排序后的结果存入指定的文件1.sort [file]
后面直接跟文件名时,会以每一行的第一个字符进行排序,如果第一个字符相同则比第二个,以此类推

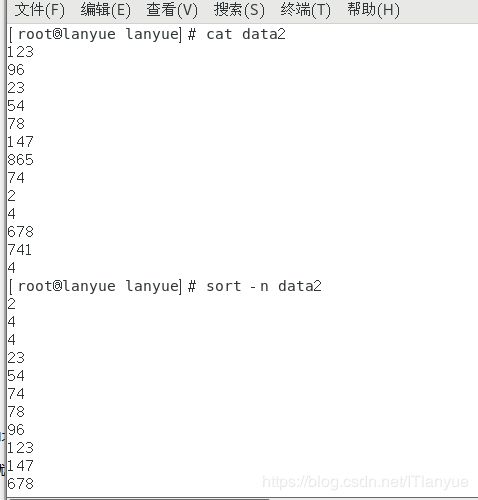
2.sort -n/g
根据数值进行排位
3.sort -n -t [分隔符] -k [排序参考栏目标号]

4.
du -h [目录] | sort -h
或
du -h /root/ | grep -v '^0' | sort -h
将某目录下的文件按文件大小排序

二、uniq
uniq用于重复数据处理,使用前数据必须完成排序(一般指sort排序)
uniq [选项参数] [输入文件] [输出文件]
-c ===> 在每列旁边显示该行重复出现的次数
-d ===> 只打印重复的行,重复的行只显示一次
-D ===> 只打印重复的行,重复的行出现多少次就显示多少次
-f ===> 忽略行首的几个字段
-i ===> 忽略大小写
-s ===> 忽略行首的几个字母
-u ===> 只打印唯一的行
-w ===> 比较不超过n个字母
-z ===> 使用'\0'作为行结束符,而不是新换行1.uniq -c
统计某文本每行数据出现的次数

2.uniq -D
统计某文件重复行,并把重复行都显示出来

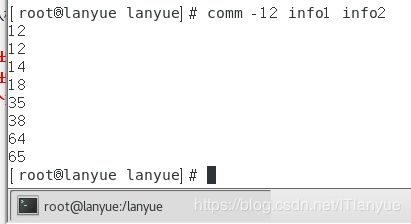
三、comm
对已存在有序文件进行比较:第一列只在文件1中出现的文件,第二列只在文件2中出现的文件,第三列在文件1和文件2中同事出现的文件
comm [-123] [第一个文件] [第二个文件]
-1 ===> 不显示在第1个文件中出现的列
-2 ===> 不显示在第2个文件中出现的列
-3 ===> 不显示只在第1或第2个文件中出现的列两个文件中重复出现的行
四、diff
1.参数说明
diff [选项] [文件1或目录1] [文件2或目录2] (四种组合方式)
diff [-abBcdefHilnNpPqrstTuvwy] [-<行数>] [-C <行数>] [-D <巨集名称>] [-I <字符或字符串>] [-S <文件>] [-W <宽度>] [-x <文件或目录>] [-X <文件>] [--left-column] [--suppress-common-line] [文件或目录1] [文件或目录2]
注意:
=====================================================================================
1.diff命令一般比较两个文件的不同,如果使用”-”代替文件参数,则要比较的内容将来自标准输入
2.diff命令是以逐行的方式比较文本文件的异同
3.如果指定比较的是目录的时候,diff命令会比较两个目录下名字相同的文本文件,但不会比较其中子目录
=====================================================================================
-a ===> diff预设只会逐行比较文本文件。
-b ===> 不检查空格字符的不同。
-B ===> 不检查空白行
-c ===> 显示全部内文,并标出不同之处
-d ===> 使用不同的演算法,以较小的单位来做比较
-e ===> 此参数的输出格式可用于ed的script文件
-f ===> 输出的格式类似ed的script文件,但按照原来文件的顺序来显示不同处
-H ===> 比较大文件时,可加快速度
-i ===> 不检查大小写的不同。
-l ===> 将结果交由pr程序来分页
-n ===> 将比较结果以RCS的格式来显示
-p ===> 若比较的文件为C语言的程序码文件时,显示差异所在的函数名称
-N ===> 在比较目录时,若文件A仅出现在某个目录中,预设会显示
-P ===> 与-N类似,但只有当第二个目录包含了一个第一个目录所没有的文件时,才会将这个文件与空白的文件做比较
-q ===> 仅显示有无差异,不显示详细的信息
-r ===> 比较子目录中的文件
-s ===> 若没有发现任何差异,仍然显示信息
-t ===> 在输出时,将tab字符展开
-T ===> 在每行前面加上tab字符以便对齐
-w ===> 忽略全部的空格字符。
-y ===> 以并列的方式显示文件的异同之处。
–left-column ===> 在使用-y参数时,若两个文件某一行内容相同,则仅在左侧的栏位显示该行内容
–suppress-common-lines ===> 在使用-y参数时,仅显示不同之处
-<行数> ===> 指定要显示多少行的文本(此参数必须与-c或-u参数一并使用)
-C<行数> ===> 与执行”-c-<行数>”指令相同
-W<宽度> ===> 在使用-y参数时,指定栏宽
-u(U)<列数> ===> 以合并的方式来显示文件内容的不同
-D<巨集名称> ===> 此参数的输出格式可用于前置处理器巨集
-S<文件> ===> 在比较目录时,从指定的文件开始比较
-X<文件> ===> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件
-X<文件> ===> 您可以将文件或目录类型存成文本文件,然后在=<文件>中指定此文本文件
-x<文件名或目录> ===> 不比较选项中所指定的文件或目录
-x<文件名或目录> ===> 不比较选项中所指定的文件或目录
-l<字符或字符串> ===> 若两个文件在某几行有所不同,而这几行同时都包含了选项中指定的字符或字符串,则不显示这两个文件的差异
2.结果说明
diff的输出结果表明需要对一个文件做怎样的操作之后才能与第二个文件相匹配
| ===> 表示前后2个文件内容有不同
< ===> 表示后面文件比前面文件少了1行内容
> ===> 表示后面文件比前面文件多了1行内容
a ===> add
c ===> change
d ===> delete
例如:
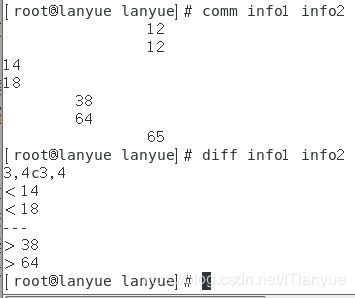
从图中可以看出
3,4c3,4
这句输出的意思就是第一个文件的第三四行需要进行改变(c=change)操作才能与第二个文件的三四行数据相同