如何用深度学习来写歌词(神经网络实现)
学习神经网络一段时间了,也写了些小项目,比如说chatbot,中英翻译…最近在网上看到深度学习来写歌词的,心血来潮于是便开始coding了。下面我将介绍一下整个过程吧(先贴上项目地址吧generate-lyrics-using-PyTorch,欢迎大家follow、fork哦,平时会和大家分享更多有意思的项目)
以下代码基于PyTorch实现,如果你没有了解过PyTorch请先学习PyTorch
一、循环神经网络(RNN)能创作歌词的原理
如果对RNN有了解,相信你肯定看过这幅图吧
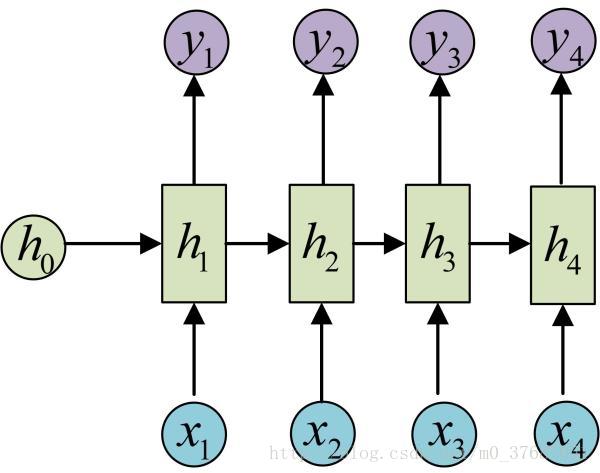
对于序列问题的建模,RNN引入了隐状态h(hidden state),h可以对序列形的数据提取特征,接着再转换为输出。
歌词向量化后输入x1, x2, …..xn,输出y1, y2, …yn。x和记忆单元预测输出y,随着不断学习预测效果会越来越好。以下的图可以很好的显示能RNN能写歌词的原因(图片来源于网络,侵立删)

训练到一定程度后,神经网络已经学到足够东西了。这时候你可以看到,当输入“如”时它会预测输出是“果”,输入“果”时预测输出为“不”…
二、数据准备
有点懒,没有时间去搜集歌词数据,所以用了别人实例的数据(【玩转数据系列十五】机器学习PAI为你自动写歌词,妈妈再也不用担心我的freestyle了(提供数据、代码))如果有侵权,请告诉我哦!
三、代码实现
首先是数据处理,向量化,数据随机切割并封装用于训练
# -*- coding: utf-8 -*-
import string
import random
import torch
from torch.autograd import Variable
from config import *
class Lang(object):
def __init__(self, filename):
self.char2idx = {}
self.idx2char = {}
self.n_words = 0
self.process(filename)
def process(self, filename):
with open(filename, 'r') as f:
for line in f.readlines():
words = set(line)
comm = words & set(self.char2idx)
for word in words:
if word not in comm:
self.char2idx[word] = self.n_words
self.idx2char[self.n_words] = word
self.n_words += 1
class Dataset(object):
def __init__(self, filename):
self.lang = Lang(filename)
#print(self.lang.idx2char)
self.data = self.load_file(filename)
def load_file(self, filename):
data = []
with open(filename, 'r') as f:
data = f.read()
return data
def random_chunk(self, chunk_len = CHUNK_LEN):
start_idx = random.randint(0, len(self.data) - chunk_len)
end_idx = start_idx + chunk_len + 1
return self.data[start_idx:end_idx]
def get_variable(self, string):
tensor = torch.zeros(len(string)).long() # FloatTensor->LongTensor
for c in range(len(string)):
tensor[c] = self.lang.char2idx[string[c]]
return Variable(tensor)
def random_training_set(self):
chunk = self.random_chunk()
input = self.get_variable(chunk[:-1])
target = self.get_variable(chunk[1:])
return input, target
接着是神经网络,本项目采用了GRU来实现RNN,歌词数据向量化后首先Embedding接着通过GRU层训练,最后输出层解码。由于损失函数使用了交叉熵损失函数已经含有softmax,故不做softmax处理
# !/usr/bin/env python
# -*- coding:utf-8 -*-
import torch
import torch.nn as nn
from torch.autograd import Variable
class RNN(nn.Module):
def __init__(self, input_size, hidden_size, output_size, n_layers = 1, dropout_p=0.1):
super(RNN, self).__init__()
self.input_size = input_size
self.hidden_size = hidden_size
self.output_size = output_size
self.n_layers = n_layers
self.encoder = nn.Embedding(input_size, hidden_size)
self.gru = nn.GRU(hidden_size, hidden_size, n_layers)
self.dropout = nn.Dropout(dropout_p)
self.decoder = nn.Linear(hidden_size, output_size)
def forward(self, input, hidden):
# input.view(1, -1) size 1 x input_size
# input size 1 x 1 x hidden_size
input = self.encoder(input.view(1, -1))
input = self.dropout(input)
# input.view(1 ,1 ,-1) size seq_len x batch x input_size => 1 x 1 x input_size
# hidden size n_layers x batch x hidden_size => n_layers x 1 x input_size
# output size seq_len x batch x hidden_size * num_directions => 1 x 1 x hidden_size
output, hidden = self.gru(input.view(1, 1, -1), hidden)
# output.view(1, -1) size 1 x (1 x hidden_size)
# output size 1 x output_size
output = self.decoder(output.view(1, -1))
return output, hidden
def init_hidden(self):
# size self.n_layers x 1 x self.hidden_size
return Variable(torch.zeros(self.n_layers, 1, self.hidden_size))好了,接下来就可以开始训练了
# !/usr/bin/env python
# -*- coding: utf-8 -*-
import os
import pickle
import string
import time
import torch
import torch.nn as nn
import matplotlib.pyplot as plt
from torch.autograd import Variable
from config import *
from model import RNN
from dataset import Dataset
from utils import *
def evaluate(model, dataset, prime_str='我只', predict_len = 100, temperature = 0.8):
hidden = model.init_hidden()
prime_input = dataset.get_variable(prime_str)
predicted = prime_str
for p in range(len(prime_str)-1):
_, hidden = model(prime_input[p], hidden)
input = prime_input[-1]
for p in range(predict_len):
output, hidden = model(input, hidden)
# 多项分布随机采样
# exp()保证各项均为正数
output_dist = output.data.view(-1).div(temperature).exp()
top_i = torch.multinomial(output_dist, 1)[0] # int
# 拼接预测出的字符
predicted_char = dataset.lang.idx2char[top_i]
predicted += predicted_char
input = dataset.get_variable(predicted_char)
return predicted
def train(model, optimizer, loss_fn, dataset, start_epoch=1):
start = time.time()
loss_avg = 0
for epoch in range(start_epoch, N_EPOCHS+1):
input, target = dataset.random_training_set()
hidden = model.init_hidden()
optimizer.zero_grad()
loss = 0
for c in range(CHUNK_LEN):
output, hidden = model(input[c], hidden)
loss += loss_fn(output, target[c])
loss.backward()
optimizer.step()
each_loss_avg = loss.data[0] / CHUNK_LEN
loss_avg += each_loss_avg
if epoch % PRINT_EVERY == 0:
print('[%s (%d %d%%) %.4f]' % (time_since(start), epoch, epoch/N_EPOCHS*100, each_loss_avg))
print(evaluate(model, dataset, '你要', 100),'\n')
save_model(model, epoch)
def generate(model, dataset, word, gen_len):
print("gen> ", evaluate(model, dataset, word, gen_len))
def main():
path = './runtime/data.pkl'
if not os.path.exists(path):
with open(path, 'wb') as f:
dataset = Dataset('./data/lyrics.txt')
pickle.dump(dataset, f)
else:
with open(path, 'rb') as f:
dataset = pickle.load(f)
model = RNN(dataset.lang.n_words, HIDDEN_SIZE, dataset.lang.n_words, N_LAYERS)
model, start_epoch = load_previous_model(model)
optimizer = torch.optim.Adam(model.parameters(), lr=LEARNING_RATE)
loss_fn = nn.CrossEntropyLoss()
train(model, optimizer, loss_fn, dataset, start_epoch=start_epoch)
if __name__ == '__main__':
main()四、训练效果
在CPU机子上跑了一天,还没收敛,试着让神经网络写了几首词,有的想过还不错,有的就一般般了。大家可以把项目clone下来继续跑模型,估计想过会变好
《情人》
如果我遇见世界的梦想
那为了永远
永远不会看不到
如果你看我的幸福
你的温柔像羽毛
巷口甩上的画面
一天看你看清楚的名字就像日历上一件
没有你可以爱你的微笑
洋溢幸福的味道
还原谅了我的情人节
你是我唯一的爱情
只有这生变我的爱
《安静了》
我听闻 你看不见罪的国度
请原谅我有多难熬多少关得我
亲手一直不变的二独
我要的天堂景象魔法的离开
记忆在街上
为了陌生的地方,
我看远看见你看见
我摊开去走的十八般武艺
多么想幻化之前
让我用不孤独朋友
我很喜欢我的疼痛
嘿而不少绝不能不说
却始终淋不到
没有了你的泪洒满人的空间
前面的微笑
洋溢幸福的味道五、推荐阅读
- RNN入门必读 The Unreasonable Effectiveness of Recurrent Neural Networks
- PyTorch教程 当然你也可以学习其它深度学习框架
由于学力有限,还有很多东西很难描述出来,日后会慢慢补充的哦。大家可看clone项目下来试着运行以下,如果觉得可以欢迎fork或者like一下哦!