Scala习题-学生成绩分析
题目概述
有一个成绩表 sc.txt
Tom,DataBase,80
Tom,Algorithm,50
Tom,DataStructure,60
Jim,DataBase,90
Jim,Algrddorithm,60
Jim,DataStructure,80
John,DataStructure,80
Zhang,DataStructure,80
Liu,DataStructure,66
Li,DataStructure,84
Huang,DataStructure,85
Li,DataBase,93
Zhang,Java,87
Smith,Java,90
Li,Java,87
John,DataBase,79
1) 该系总共有多少学生;
2)该系共开设来多少门课程;
3) Tom 同学的总成绩平均分是多少;
解题过程
#将数据写入sc.txt中
cd /usr/local/hadoop
vim sc.txt
#将sc.txt上传到hdfs中
cd /usr/local/hadoop
hdfs dfs -put /usr/local/hadoop/sc.txt
(1)
#启动spark-shell
val rdd1=sc.textFile("sc.txt")
#查看rdd1内容
rdd1.foreach(println)
#按逗号分隔,取得名字
val rdd2=rdd1.map(x=>x.split(",")(0))
rdd2.foreach(println)
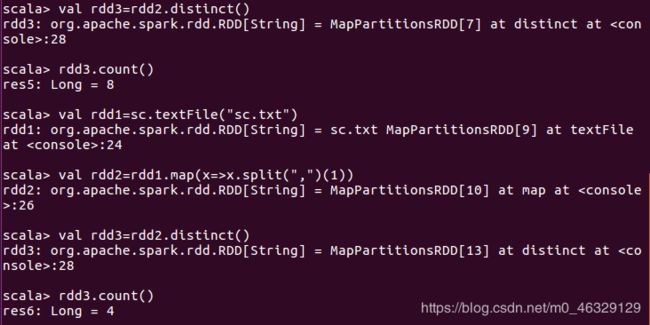
#去重处理
val rdd3=rdd2.distinct()
#计数
rdd3.count()
(2)
与第一题类似
#启动spark-shell
val rdd1=sc.textFile("sc.txt")
#查看rdd1内容
rdd1.foreach(println)
#按逗号分隔,取得名字
val rdd2=rdd1.map(x=>x.split(",")(1))
rdd2.foreach(println)
#去重处理
val rdd3=rdd2.distinct()
#计数
rdd3.count()
(3)
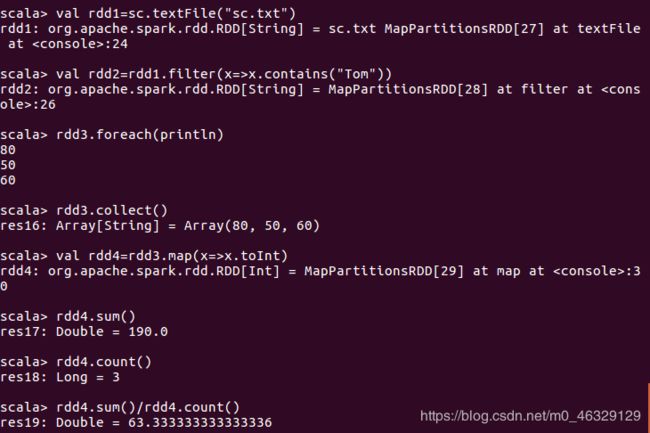
val rdd1=sc.textFile(“sc.txt”)
#查找包含Tom的信息
val rdd2=rdd1.filter(x=>x.contains(“Tom”))
#分割得到成绩
val rdd3=rdd2.map(x=>x.split(",")(2))
rdd3.foreach(println)
#rdd3为Array类型
rdd3.collect()
#强制转换
val rdd4=rdd3.map(x=>x.toInt)
rdd4.sum()
rdd4.count()
rdd4.sum()/rdd4.count()
结果1

结果2
结果3