list和hash list
链表是linux内核源码中非常重要的数据结构,内核中大量的对象都是通过链表组织连接的,以此来展示内核对象之间的关系。在linux内核源码中,使用了两种链表:普通的循环双向链表list和双向链表hash list。关于循环双向链表list的讨论文章已经足够多,我这里主要剖析令人迷惑的hash list。
我们先从普通list的操作入手,然后讨论hash list和它的差异,这样能便于清晰地理解hash list。
一、普通链表list操作
list链表的常规操作包括插入,删除,替换,移动,以及拼接。这里只讨论能引起节点关系变动的操作,而链表遍历是“只读”的。其中list链表的拼接也可以看作是插入操作的特例,移动操作是删除和插入操作的合体。
下面重点讨论list链表的插入、删除和替换操作而引起的节点关系变动。
1. list插入操作
list链表的插入操作包括如下4个指针的改变:
>>>待插入节点自身的next和prev
>>>前驱节点的next
>>>后继节点的prev
我们先从普通list的操作入手,然后讨论hash list和它的差异,这样能便于清晰地理解hash list。
一、普通链表list操作
list链表的常规操作包括插入,删除,替换,移动,以及拼接。这里只讨论能引起节点关系变动的操作,而链表遍历是“只读”的。其中list链表的拼接也可以看作是插入操作的特例,移动操作是删除和插入操作的合体。
下面重点讨论list链表的插入、删除和替换操作而引起的节点关系变动。
1. list插入操作
list链表的插入操作包括如下4个指针的改变:
>>>待插入节点自身的next和prev
>>>前驱节点的next
>>>后继节点的prev
2. list删除操作
list链表的删除操作包括2个指针的变动:
>>>前驱节点的next
>>>后继节点的prev
3. list替换操作
list链表的替换类同于插入操作,也包括如下4个指针的改变:
>>>前驱节点的next
>>>后继节点的prev
>>>待插入节点自身的next和prev
我们下面以插入操作为例,来讨论链表各节点之间的链接关系变动。
如果待插入操作的节点和插入点(如在某节点之前或之后)已知,那么需要进行两种更新操作:待插入节点的prev和next,使其分别指向其前驱节点和后继节点。更新前驱节点的next和后继节点的prev,二者都指向待插入节点。这时list操作的时间复杂度为O(1)。
比如我们要在一个list链表的node1和node2之间插入节点new,为了表述方便,这里假定指针n指向new,
list链表的删除操作包括2个指针的变动:
>>>前驱节点的next
>>>后继节点的prev
3. list替换操作
list链表的替换类同于插入操作,也包括如下4个指针的改变:
>>>前驱节点的next
>>>后继节点的prev
>>>待插入节点自身的next和prev
我们下面以插入操作为例,来讨论链表各节点之间的链接关系变动。
如果待插入操作的节点和插入点(如在某节点之前或之后)已知,那么需要进行两种更新操作:待插入节点的prev和next,使其分别指向其前驱节点和后继节点。更新前驱节点的next和后继节点的prev,二者都指向待插入节点。这时list操作的时间复杂度为O(1)。
比如我们要在一个list链表的node1和node2之间插入节点new,为了表述方便,这里假定指针n指向new,
即n = &new。
上面描述的插入操作引起的节点关系变动则为:
>>>待插入节点new自身的next和prev
待插入new节点的next和prev分别指向链表插入点的前驱和后继节点。更新n->next和n->prev,
>>>待插入节点new自身的next和prev
待插入new节点的next和prev分别指向链表插入点的前驱和后继节点。更新n->next和n->prev,
使其分别指向链表插入点的后继和前驱节点, 即n->next = &node2; n->prev = &node1;
>>>前驱节点的next:
n->prev中保存的是前驱节点指针,然后很自然的就能找到其前驱节点的next, 即n->prev->next。
更新n->prev->next,使其指向new,即n->prev->next = n;
>>>后继节点的prev
n->next中保存的是后继节点指针,后继节点的prev则为n->next->prev。
更新n->next->prev,使其指向new,即n->next->prev = n;
下图是一个有三个节点(head, node1, node2)的链表在插入new节点后,链表的链接关系:
n->prev中保存的是前驱节点指针,然后很自然的就能找到其前驱节点的next, 即n->prev->next。
更新n->prev->next,使其指向new,即n->prev->next = n;
>>>后继节点的prev
n->next中保存的是后继节点指针,后继节点的prev则为n->next->prev。
更新n->next->prev,使其指向new,即n->next->prev = n;
下图是一个有三个节点(head, node1, node2)的链表在插入new节点后,链表的链接关系:
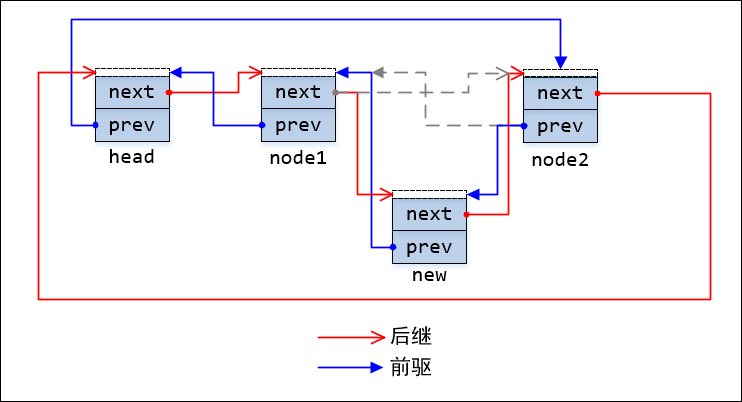
图1
上图中,节点前端的虚框表示节点自身的地址,灰色虚线箭头表示链表未插入new之前node1和node2之间的链接关系。
链表节点间的链接关系是一目了然的,且很对称:prev均指向前一个节点,next指向下一个节点,链表的头尾节点都是如此。
二、hash list操作
上面的讨论限于常规的list,而hash list操作情况有些不同。
内核设计者为了在hash表中,为了节省链表头部的存储空间,特别设计了hash list。在hash list中,头部节点使用
链表节点间的链接关系是一目了然的,且很对称:prev均指向前一个节点,next指向下一个节点,链表的头尾节点都是如此。
二、hash list操作
上面的讨论限于常规的list,而hash list操作情况有些不同。
内核设计者为了在hash表中,为了节省链表头部的存储空间,特别设计了hash list。在hash list中,头部节点使用
struct hlist_head来表示,普通节点则使用了struct hlist_node数据结构,且其和list结构prev对应的成员更改为
二级指针变量pprev。
在hlist_node结构中,只有单一的指针first成员(该first也相当于head的next成员),这样相较于前面所述的常规list,少了一个prev指针,在32位机上,一个表头由此可以节省4个字节的存储空间,这对为了避免哈希冲突而空间分配尽可能大的hash table数组来说,累积节省的存储空间就很可观了。
在hlist_node结构中,只有单一的指针first成员(该first也相当于head的next成员),这样相较于前面所述的常规list,少了一个prev指针,在32位机上,一个表头由此可以节省4个字节的存储空间,这对为了避免哈希冲突而空间分配尽可能大的hash table数组来说,累积节省的存储空间就很可观了。
但这样做也会带了一些问题:由于头节点和普通节点的数据类型不一致,上述list的涉及到头部节点的操作代码实现就不可用了,hash list就必须有自己的一套链表操作实现机制。
我们下面先讨论在一个链表的node1和node2之间插入节点new时,hash list和list两种操作上的区别,然后再以实际的头部插入节点为例,详细说明其代码实现。
为了和list区别,这里使用指针hn指向new,即hn = &new。
<一> 、hash list和list操作上的区别
1. 待插入节点new自身的next和prev
在hashi list中执行插入操作时,待插入节点new的next还是指向后继节点,即n->next = &node2;
但new节点的prev(这里为pprev)却和list中的prev指向不同,此时,它指向的是前驱节点的next的指针,
<一> 、hash list和list操作上的区别
1. 待插入节点new自身的next和prev
在hashi list中执行插入操作时,待插入节点new的next还是指向后继节点,即n->next = &node2;
但new节点的prev(这里为pprev)却和list中的prev指向不同,此时,它指向的是前驱节点的next的指针,
即hn->prev = &node1.next; 注意这里的"&"不是取node1的地址。 由于前驱节点的next是一个指针,所以指
向指针的指针,hn->prev是一个二级指针。
2. 前驱节点的next
由于hn->prev不再像list那样用来保存前驱节点的指针,而直接保存的是指向前驱节点的next的指针。这样,引用“前驱节点 的next”,就不像上面list中的那样,通过hn->prev->next,而是直接使用hn->prev来引用前驱节点的next,也即*(hn->prev)。这里并无前驱节点的直接引用,因为n->prev并不代表前驱节点。
hn->prev存在的目的只是为了找到new的前驱节点的next,而hn->prev表述的仅仅是这样一种关系:hn->prev指向的next是new的指针。
从链表的前驱和后继的本质来看:后继是进行正序访问(沿链表头部到节点的方向)节点的保证;前驱则是进行反序访问(沿链表尾部到节点的方向)节点的保证。如在此"双向"含义的基础上,hash list则不能称为严格意义上的双向链表。因为hash list的prev和next都是围绕next来布置的,节点的prev中保存的也只是它的前驱节点中的next而已,而非该节点的前驱节点。所以hash list是不能反向遍历的:需要再次强调的是hash list节点中并未保存指向前驱节点的指针,保存的只是指向前驱节点的next的指针。这里的hn->prev存在的目的不是为了链表的反向访问,它存在的目的只是为了方便上述的插入、删除等操作,并使操作的时间复杂度简化为O(1)。
3. 后继节点的prev
后继节点还用hn->next来指向,那么后继节点的prev则为:hn->next->prev,就像下图所示,很显然它指向的 是hn->next。
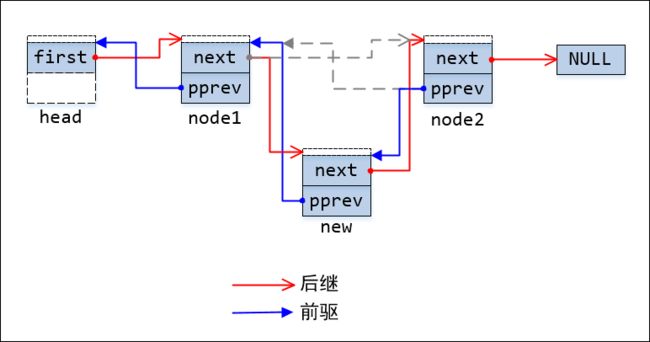
图2:在node1和node2之间插入节点new
注意,上图中pprev指向的是next的地址,而非图1中的指向节点前端的虚框(节点地址)。最后,还可以看到hlist尾节点的next指针为空,无法进行沿链表尾部到节点方向的访问。
那么hn->prev为何不像list中的n->prev一样直接指向前驱(保存前驱节点指针)呢?
因为如果按照list中的定义,n->prev指向的前驱节点中,头结点和普通节点统一为list_head结构类型。在hash list中,节点的前驱有可能是头结点,而头结点却是hlist_head结构类型,hn->prev则是hlist_node结构类型指针。两者数据类型的不同导致hn->prev不能指向单一的hlist_node结构,内核设计者巧妙的将hn->prev设计成指向前驱节点的next的指针,这样就解决了链表操作中“前驱节点的next"的引用问题,而hash list的头结点成员first也被设计为这样一个指针。这样就将hash list的头结点和普通节点操作中对节点的引用统一起来。这样在链表操作中,就无需另设一个函数,来对应链表操作涉及到头结点时的例外。
<二>、头部插入节点代码剖析:
图2是链表中间插入节点的关系图,其实现函数包括:hlist_add_before和hlist_add_after。
本节重点讨论在链表头部插入节点。
下面的函数hlist_add_head是在hash list的头部插入节点的代码实现:
这里有两种情况:
1. 链表第一次插入节点:
此时链表只有一个头节点,且头结点的first为NULL(链表初始化时,first会被初始化为NULL)。
后继节点还用hn->next来指向,那么后继节点的prev则为:hn->next->prev,就像下图所示,很显然它指向的 是hn->next。
图2:在node1和node2之间插入节点new
注意,上图中pprev指向的是next的地址,而非图1中的指向节点前端的虚框(节点地址)。最后,还可以看到hlist尾节点的next指针为空,无法进行沿链表尾部到节点方向的访问。
那么hn->prev为何不像list中的n->prev一样直接指向前驱(保存前驱节点指针)呢?
因为如果按照list中的定义,n->prev指向的前驱节点中,头结点和普通节点统一为list_head结构类型。在hash list中,节点的前驱有可能是头结点,而头结点却是hlist_head结构类型,hn->prev则是hlist_node结构类型指针。两者数据类型的不同导致hn->prev不能指向单一的hlist_node结构,内核设计者巧妙的将hn->prev设计成指向前驱节点的next的指针,这样就解决了链表操作中“前驱节点的next"的引用问题,而hash list的头结点成员first也被设计为这样一个指针。这样就将hash list的头结点和普通节点操作中对节点的引用统一起来。这样在链表操作中,就无需另设一个函数,来对应链表操作涉及到头结点时的例外。
<二>、头部插入节点代码剖析:
图2是链表中间插入节点的关系图,其实现函数包括:hlist_add_before和hlist_add_after。
本节重点讨论在链表头部插入节点。
下面的函数hlist_add_head是在hash list的头部插入节点的代码实现:
static inline void hlist_add_head(struct hlist_node *n, struct hlist_head *h)
{
struct hlist_node *first = h->first;
n->next = first;
if (first)
first->pprev = &n->next;
h->first = n;
n->pprev = &h->first;
}
这里有两种情况:
1. 链表第一次插入节点:
此时链表只有一个头节点,且头结点的first为NULL(链表初始化时,first会被初始化为NULL)。
上述代码首先将头节点的后继节点指针赋值给变量first,即头结点的first指向其后继节点。
n->next = first语句,则将插入节点的next指向后继节点,即n->next = NULL;
如果first为空,跳过first->pprev = &n->next; 接着执行h->first = n; 该语句将头结点的first指向插入节点。
最后,n->pprev = &h->first; 将插入节点的prev指向头结点的first。
这里头结点的first结构成员,就相当于普通节点的next结构成员。
链表插入节点new后的链接关系如下面图3所示:
n->next = first语句,则将插入节点的next指向后继节点,即n->next = NULL;
如果first为空,跳过first->pprev = &n->next; 接着执行h->first = n; 该语句将头结点的first指向插入节点。
最后,n->pprev = &h->first; 将插入节点的prev指向头结点的first。
这里头结点的first结构成员,就相当于普通节点的next结构成员。
链表插入节点new后的链接关系如下面图3所示:
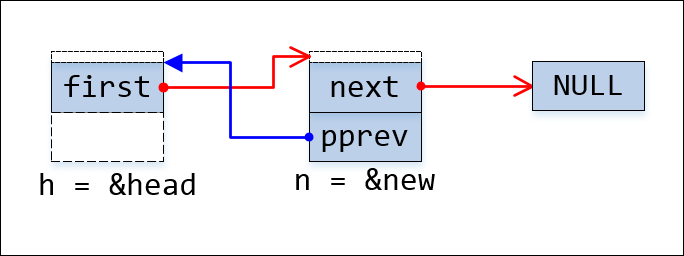
图3:链表第一次插入节点new
2. 链表非第一次插入节点:
如果链表中除了头结点外,还有其他节点,此时插入新的节点时,和上述1中唯一的不同是:
需要更新待插入节点的后继中的pprev指针,也即是将后继节点的pprev更新为新节点的成员next的指针。
即上述函数hlist_add_head中的代码first->pprev = &n->next;
hlist_add_head执行完,节点间的链接关系如下面图4所示:
hlist_add_head执行完,节点间的链接关系如下面图4所示:
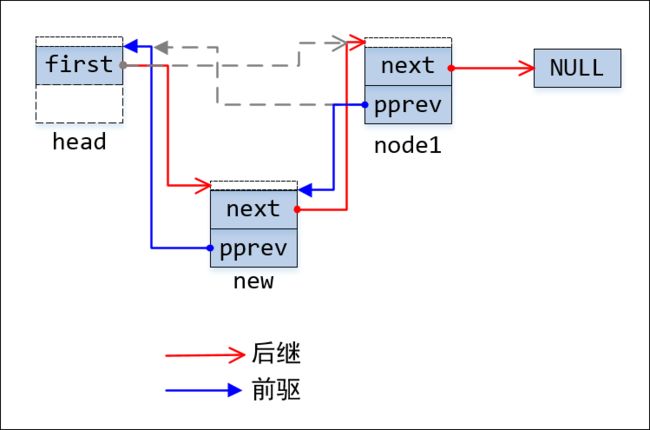
图4:在头结点和node1之间插入节点new
综上所述,hash list的存在以及其操作演进逻辑如下:
为了节省存储空间-->使用单指针表头--->数据类型不一致--->节点的prev指向发生改变
--->当链表操作涉及到头部节点是,实现代码发生变化。
但同时,根本的是,hash list的链表结构是不同于list:节点无真正意义上的前驱,hash链表的内在逻辑是单链表,在内核中也是作为单链表的实际应用。