时区处理
在Python中,时区信息来自第三方库pytz,它使Python可以使用Olson数据库(汇编了世界时区信息)。
有关pytz库的更多信息,请查阅其文档,时区名可以在文档中找到,也可以通过交互的方式查看
from pandas import Series,DataFrame
import pandas as pd
import numpy as np
import pytz
pytz.common_timezones[-5:]
['US/Eastern', 'US/Hawaii', 'US/Mountain', 'US/Pacific', 'UTC']
要从pytz中获取时区对象,使用pytz.timezone
tz=pytz.timezone('US/Eastern')
tz
pandas中的方法既可以接受时区名也可以接受这种对象。建议只用时区名
本地化和转换
默认情况下,pandas中的时间序列是单纯的(naive)时区
rng=pd.date_range('3/9/2017 10:30',periods=6,freq='D')
ts=Series(np.random.randn(len(rng)),index=rng)
ts
2017-03-09 10:30:00 -0.010633
2017-03-10 10:30:00 -1.026320
2017-03-11 10:30:00 0.001829
2017-03-12 10:30:00 -0.221503
2017-03-13 10:30:00 -1.658208
2017-03-14 10:30:00 0.559757
Freq: D, dtype: float64
print(ts.index.tz) #其索引的tz字段为None
None
在生成日期范围的时候还可以加上一个时区集
pd.date_range('10/1/2017 10:30',periods=10,freq='D',tz='UTC')
DatetimeIndex(['2017-10-01 10:30:00+00:00', '2017-10-02 10:30:00+00:00',
'2017-10-03 10:30:00+00:00', '2017-10-04 10:30:00+00:00',
'2017-10-05 10:30:00+00:00', '2017-10-06 10:30:00+00:00',
'2017-10-07 10:30:00+00:00', '2017-10-08 10:30:00+00:00',
'2017-10-09 10:30:00+00:00', '2017-10-10 10:30:00+00:00'],
dtype='datetime64[ns, UTC]', freq='D')
从单纯到本地化的转换是通过tz_localize方法处理的
ts_utc=ts.tz_localize('UTC')
ts_utc
2017-03-09 10:30:00+00:00 -0.010633
2017-03-10 10:30:00+00:00 -1.026320
2017-03-11 10:30:00+00:00 0.001829
2017-03-12 10:30:00+00:00 -0.221503
2017-03-13 10:30:00+00:00 -1.658208
2017-03-14 10:30:00+00:00 0.559757
Freq: D, dtype: float64
一旦时间序列被本地化到某个特定时区,就可以用tz_convert将其转换到别的时区了
ts_utc.tz_convert('US/Eastern')
2017-03-09 05:30:00-05:00 -0.010633
2017-03-10 05:30:00-05:00 -1.026320
2017-03-11 05:30:00-05:00 0.001829
2017-03-12 06:30:00-04:00 -0.221503
2017-03-13 06:30:00-04:00 -1.658208
2017-03-14 06:30:00-04:00 0.559757
Freq: D, dtype: float64
对于上面这种时间序列(它跨越了美国东部时区的夏令时转变期),我们可以将其本地化到EST,然后转换为UTC或柏林时间
ts_eastern=ts_utc.tz_convert('US/Eastern')
ts_eastern.tz_convert('UTC')
2017-03-09 10:30:00+00:00 -0.010633
2017-03-10 10:30:00+00:00 -1.026320
2017-03-11 10:30:00+00:00 0.001829
2017-03-12 10:30:00+00:00 -0.221503
2017-03-13 10:30:00+00:00 -1.658208
2017-03-14 10:30:00+00:00 0.559757
Freq: D, dtype: float64
ts_eastern.tz_convert('Europe/Berlin')
2017-03-09 11:30:00+01:00 -0.010633
2017-03-10 11:30:00+01:00 -1.026320
2017-03-11 11:30:00+01:00 0.001829
2017-03-12 11:30:00+01:00 -0.221503
2017-03-13 11:30:00+01:00 -1.658208
2017-03-14 11:30:00+01:00 0.559757
Freq: D, dtype: float64
tz_localize和tz_convert也是DatetimeIndex的实例方法
ts.index.tz_localize('Asia/Shanghai')
DatetimeIndex(['2017-03-09 10:30:00+08:00', '2017-03-10 10:30:00+08:00',
'2017-03-11 10:30:00+08:00', '2017-03-12 10:30:00+08:00',
'2017-03-13 10:30:00+08:00', '2017-03-14 10:30:00+08:00'],
dtype='datetime64[ns, Asia/Shanghai]', freq='D')
警告: 对单纯时间戳的本地化操作还会检查夏令时转变期附近容易混淆或不存在的时间。
操作时区意识型Timestamp对象
跟时间序列和日期范围差不多,Timestamp对象也能被从单纯型(naive)本地化为时区意识型(time zone-aware),并从一个时区转换到另一个时区
stamp=pd.Timestamp('2017-06-12 06:00')
stamp_utc=stamp.tz_localize('utc')
stamp_utc
Timestamp('2017-06-12 06:00:00+0000', tz='UTC')
stamp_utc.tz_convert('US/Eastern')
Timestamp('2017-06-12 02:00:00-0400', tz='US/Eastern')
在创建Timestamp时,还可以传入一个时区信息
stamp_moscow=pd.Timestamp('2017-06-29 06:30',tz='Europe/Moscow')
stamp_moscow
Timestamp('2017-06-29 06:30:00+0300', tz='Europe/Moscow')
时区意识型Timestamp对象在内部保存了一个UTC时间戳值(自UNIX纪元(1970年1月1日)算起的纳秒数)。这个UTC值在时区转换过程中是不会发生变化的
stamp_utc.value
1497247200000000000
stamp_utc.tz_convert('US/Eastern').value
1497247200000000000
当使用pandas的DateOffset对象执行时间算术运算时,运算过程会自动关注是否存在夏令时转变期
from pandas.tseries.offsets import Hour
stamp=pd.Timestamp('2017-06-29 06:30',tz='US/Eastern')
stamp
Timestamp('2017-06-29 06:30:00-0400', tz='US/Eastern')
stamp+Hour() # 夏令时转变前30分钟
Timestamp('2017-06-29 07:30:00-0400', tz='US/Eastern')
stamp=pd.Timestamp('2017-12-05 00:30',tz='US/Eastern')
stamp
Timestamp('2017-12-05 00:30:00-0500', tz='US/Eastern')
stamp+2*Hour() # 夏令时转变前90分钟
Timestamp('2017-12-05 02:30:00-0500', tz='US/Eastern')
不同时区之间的运算
如果两个时间序列的时区不同,在将它们合并到一起时,最终结果就会是UTC。由于时间戳其实是以UTC存储的,所以这是一个很简单的运算,并不需要发生任何转换
rng=pd.date_range('3/9/2017 10:30',periods=10,freq='B')
ts=Series(np.random.randn(len(rng)),index=rng)
ts
2017-03-09 10:30:00 -0.221934
2017-03-10 10:30:00 -0.026261
2017-03-13 10:30:00 -0.582364
2017-03-14 10:30:00 -1.488370
2017-03-15 10:30:00 -0.766432
2017-03-16 10:30:00 -0.114979
2017-03-17 10:30:00 -0.708361
2017-03-20 10:30:00 -0.745198
2017-03-21 10:30:00 0.896473
2017-03-22 10:30:00 0.505825
Freq: B, dtype: float64
ts1=ts[:7].tz_localize('Europe/London')
ts1
2017-03-09 10:30:00+00:00 -0.221934
2017-03-10 10:30:00+00:00 -0.026261
2017-03-13 10:30:00+00:00 -0.582364
2017-03-14 10:30:00+00:00 -1.488370
2017-03-15 10:30:00+00:00 -0.766432
2017-03-16 10:30:00+00:00 -0.114979
2017-03-17 10:30:00+00:00 -0.708361
Freq: B, dtype: float64
ts2=ts[2:].tz_localize('Europe/London')
ts2
2017-03-13 10:30:00+00:00 -0.582364
2017-03-14 10:30:00+00:00 -1.488370
2017-03-15 10:30:00+00:00 -0.766432
2017-03-16 10:30:00+00:00 -0.114979
2017-03-17 10:30:00+00:00 -0.708361
2017-03-20 10:30:00+00:00 -0.745198
2017-03-21 10:30:00+00:00 0.896473
2017-03-22 10:30:00+00:00 0.505825
Freq: B, dtype: float64
result=ts1+ts2
result.index
DatetimeIndex(['2017-03-09 10:30:00+00:00', '2017-03-10 10:30:00+00:00',
'2017-03-13 10:30:00+00:00', '2017-03-14 10:30:00+00:00',
'2017-03-15 10:30:00+00:00', '2017-03-16 10:30:00+00:00',
'2017-03-17 10:30:00+00:00', '2017-03-20 10:30:00+00:00',
'2017-03-21 10:30:00+00:00', '2017-03-22 10:30:00+00:00'],
dtype='datetime64[ns, Europe/London]', freq='B')
时期及其算术运算
时期(period)表示的是时间区间,比如数日、数月、数季、数年等。
Period类所表示的就是这种数据类型,其构造函数需要用到一个字符串或整数,以及表10-4中的频率。
p=pd.Period(2010,freq='A-DEC')
p
Period('2010', 'A-DEC')
这个Period对象表示的是从2010年1月1日到2010年12月31日之间的整段时间。只需对Period对象加上或减去一个整数即可达到根据其频率进行位移的效果
p+7
Period('2017', 'A-DEC')
p-6
Period('2004', 'A-DEC')
如果两个Period对象拥有相同的频率,则它们的差就是它们之间的单位数量
pd.Period('2017',freq='A-DEC')-p
7
period_range函数可用于创建规则的时期范围
rng=pd.period_range('2/1/2017','12/25/2017',freq='M')
rng
PeriodIndex(['2017-02', '2017-03', '2017-04', '2017-05', '2017-06', '2017-07',
'2017-08', '2017-09', '2017-10', '2017-11', '2017-12'],
dtype='period[M]', freq='M')
PeriodIndex类保存了一组Period,它可以在任何pandas数据结构中被用作轴索引
Series(np.random.randn(11),index=rng)
2017-02 -0.319098
2017-03 -0.151707
2017-04 0.848815
2017-05 1.755160
2017-06 -2.718766
2017-07 0.921045
2017-08 -0.287053
2017-09 -0.720153
2017-10 0.827423
2017-11 -1.147326
2017-12 0.480532
Freq: M, dtype: float64
PeriodIndex类的构造函数还允许直接使用一组字符串
values=['2010Q3','2013Q2','2016Q1']
index=pd.PeriodIndex(values,freq='Q-DEC')
index
PeriodIndex(['2010Q3', '2013Q2', '2016Q1'], dtype='period[Q-DEC]', freq='Q-DEC')
时期的频率转换
Period和PeriodIndex对象都可以通过其asfreq方法被转换成别的频率。假设我们有一个年度时期,希望将其转换为当年年初或年末的一个月度时期。
p=pd.Period('2017',freq='A-DEC')
p.asfreq('M',how='start')
Period('2017-01', 'M')
p.asfreq('M',how='end')
Period('2017-12', 'M')
可以将Period('2017','A-DEC')看做一个被划分为多个月度时期的时间段中的游标。图10-1对此进行了说明。对于一个不以12月结束的财政年度,月度子时期的归属情况就不一样了
p=pd.Period('2017',freq='A-JUN')
p.asfreq('M','start')
Period('2016-07', 'M')
p.asfreq('M','end')
Period('2017-06', 'M')
在将高频率转换为低频率时,超时期(superperiod)是由子时期(subperiod)所属的位置决定的。例如,在A-JUN频率中,月份“2017年8月”实际上是属于周期“2018年”的
p=pd.Period('2017-08','M')
p.asfreq('A-JUN')
Period('2018', 'A-JUN')
PeriodIndex或TimeSeries的频率转换方式也是这样
rng=pd.period_range('2010','2018',freq='A-DEC')
ts=Series(np.random.randn(len(rng)),index=rng)
ts
2010 -0.433900
2011 -0.494450
2012 0.668362
2013 -0.728913
2014 -0.062562
2015 0.764723
2016 -1.962189
2017 -2.107805
2018 2.432714
Freq: A-DEC, dtype: float64

按季度计算的时期频率
季度型数据在会计、金融等领域中很常见。许多季度型数据都会涉及“财年末”的概念,通常是一年12个月中某月的最后一个日历日或工作日。就这一点来说,时期"2012Q4"根据财年末的不同会有不同的含义。pandas支持12种可能的季度型频率,即Q-JAN到Q-DEC
p=pd.Period('2012Q4',freq='Q-JAN')
p
Period('2012Q4', 'Q-JAN')
在以1月结束的财年中,2012Q4是从11月到1月(将其转换为日型频率就明白了)。图10-2对此进行了说明
p.asfreq('D','start')
Period('2011-11-01', 'D')
p.asfreq('D','end')
Period('2012-01-31', 'D')
因此,Period之间的算术运算会非常简单。例如,要获取该季度倒数第二个工作日下午4点的时间戳
p4pm=(p.asfreq('B','e')-1).asfreq('T','s')+16*60
p4pm
Period('2012-01-30 16:00', 'T')
p4pm.to_timestamp()
Timestamp('2012-01-30 16:00:00')

eriod_range还可用于生成季度型范围。季度型范围的算术运算也跟上面是一样的
rng=pd.period_range('2011Q3','2012Q4',freq='Q-JAN')
ts=Series(np.arange(len(rng)),index=rng)
ts
2011Q3 0
2011Q4 1
2012Q1 2
2012Q2 3
2012Q3 4
2012Q4 5
Freq: Q-JAN, dtype: int32
new_rng=(rng.asfreq('B','e')-1).asfreq('T','s')+16*60
new_rng
PeriodIndex(['2010-10-28 16:00', '2011-01-28 16:00', '2011-04-28 16:00',
'2011-07-28 16:00', '2011-10-28 16:00', '2012-01-30 16:00'],
dtype='period[T]', freq='T')
ts.index=new_rng.to_timestamp()
ts
2010-10-28 16:00:00 0
2011-01-28 16:00:00 1
2011-04-28 16:00:00 2
2011-07-28 16:00:00 3
2011-10-28 16:00:00 4
2012-01-30 16:00:00 5
dtype: int32
将Timestamp转换为Period(及其反向过程)
通过使用to_period方法,可以将由时间戳索引的Series和DataFrame对象转换为以时期索引
rng=pd.date_range('1/1/2017',periods=3,freq='M')
rng
DatetimeIndex(['2017-01-31', '2017-02-28', '2017-03-31'], dtype='datetime64[ns]', freq='M')
ts=Series(np.random.randn(3),index=rng)
ts
2017-01-31 -0.126709
2017-02-28 0.477945
2017-03-31 -1.665440
Freq: M, dtype: float64
由于时期指的是非重叠时间区间,因此对于给定的频率,一个时间戳只能属于一个时期。新PeriodIndex的频率默认是从时间戳推断而来的,你也可以指定任何别的频率。结果中允许存在重复时期
rng=pd.date_range('1/29/2010',periods=6,freq='D')
ts2=Series(np.random.randn(6),index=rng)
ts2.to_period('M')
2010-01 0.453939
2010-01 -0.116637
2010-01 0.211619
2010-02 1.552368
2010-02 0.583840
2010-02 0.219376
Freq: M, dtype: float64
要转换为时间戳,使用to_timestamp即可
pts=ts.to_period()
pts
2017-01 -0.126709
2017-02 0.477945
2017-03 -1.665440
Freq: M, dtype: float64
通过数组创建PeriodIndex
固定频率的数据集通常会将时间信息分开存放在多个列中。例如,在下面这个宏观经济数据集中,年度和季度就分别存放在不同的列中
data=pd.read_csv('pydata_book/ch08//macrodata.csv')
data[:8]

data.year
0 1959.0
1 1959.0
2 1959.0
3 1959.0
...
199 2008.0
200 2009.0
201 2009.0
202 2009.0
Name: year, Length: 203, dtype: float64
data.quarter
0 1.0
1 2.0
2 3.0
3 4.0
...
199 4.0
200 1.0
201 2.0
202 3.0
Name: quarter, Length: 203, dtype: float64
将这两个数组以及一个频率传入PeriodIndex,就可以将它们合并成DataFrame的一个索引
index=pd.PeriodIndex(year=data.year,quarter=data.quarter,freq='Q-DEC')
index
PeriodIndex(['1959Q1', '1959Q2', '1959Q3', '1959Q4', '1960Q1', '1960Q2',
'1960Q3', '1960Q4', '1961Q1', '1961Q2',
...
'2007Q2', '2007Q3', '2007Q4', '2008Q1', '2008Q2', '2008Q3',
'2008Q4', '2009Q1', '2009Q2', '2009Q3'],
dtype='period[Q-DEC]', length=203, freq='Q-DEC')
data.index=index
data.infl
1959Q1 0.00
1959Q2 2.34
1959Q3 2.74
1959Q4 0.27
1960Q1 2.31
1960Q2 0.14
1960Q3 2.70
...
2008Q2 8.53
2008Q3 -3.16
2008Q4 -8.79
2009Q1 0.94
2009Q2 3.37
2009Q3 3.56
Freq: Q-DEC, Name: infl, Length: 203, dtype: float64
重采样及频率转换
重采样(resampling)指的是将时间序列从一个频率转换到另一个频率的处理过程。将高频率数据聚合到低频率称为降采样(downsampling),而将低频率数据转换到高频率则称为升采样(upsampling)。并不是所有的重采样都能被划分到这两个大类中。例如,将W-WED(每周三)转换为W-FRI既不是降采样也不是升采样。
pandas对象都带有一个resample方法,它是各种频率转换工作的主力函数
rng=pd.date_range('1/1/2017',periods=100,freq='D')
ts=Series(np.random.randn(len(rng)),index=rng)
ts.resample('M',how='mean')
e:\python\lib\site-packages\ipykernel_launcher.py:3: FutureWarning: how in .resample() is deprecated
the new syntax is .resample(...).mean()
This is separate from the ipykernel package so we can avoid doing imports until
2017-01-31 0.256096
2017-02-28 0.206771
2017-03-31 -0.103452
2017-04-30 -0.105697
Freq: M, dtype: float64
ts.resample('M').mean()
2017-01-31 0.256096
2017-02-28 0.206771
2017-03-31 -0.103452
2017-04-30 -0.105697
Freq: M, dtype: float64
ts.resample('M',kind='period').mean()
2017-01 0.256096
2017-02 0.206771
2017-03 -0.103452
2017-04 -0.105697
Freq: M, dtype: float64
resample是一个灵活高效的方法,可用于处理非常大的时间序列。


降采样
将数据聚合到规整的低频率是一件非常普通的时间序列处理任务。待聚合的数据不必拥有固定的频率,期望的频率会自动定义聚合的面元边界,这些面元用于将时间序列拆分为多个片段。例如,要转换到月度频率('M'或'BM'),数据需要被划分到多个单月时间段中。各时间段都是半开放的。一个数据点只能属于一个时间段,所有时间段的并集必须能组成整个时间帧。在用resample对数据进行降采样时,需要考虑两样东西:
·各区间哪边是闭合的。
如何标记各个聚合面元,用区间的开头还是末尾。
首先,我们来看一些“1分钟”数据
rng=pd.date_range('1/1/2017',periods=12,freq='T')
ts=Series(np.arange(12),index=rng)
ts
2017-01-01 00:00:00 0
2017-01-01 00:01:00 1
2017-01-01 00:02:00 2
2017-01-01 00:03:00 3
2017-01-01 00:04:00 4
2017-01-01 00:05:00 5
2017-01-01 00:06:00 6
2017-01-01 00:07:00 7
2017-01-01 00:08:00 8
2017-01-01 00:09:00 9
2017-01-01 00:10:00 10
2017-01-01 00:11:00 11
Freq: T, dtype: int32
如果你想要通过求和的方式将这些数据聚合到“5分钟”块中
注意:这里与书本的代码结果不同。
ts.resample('5min').sum()
2017-01-01 00:00:00 10
2017-01-01 00:05:00 35
2017-01-01 00:10:00 21
Freq: 5T, dtype: int32
传入的频率将会以“5分钟”的增量定义面元边界。默认情况下,面元的右边界是包含的,因此00:00到00:05的区间中是包含00:05的注1。传入closed='left'会让区间以左边界闭合
这里可能版本不同,上面的那个与书上结果不同的。
ts.resample('5min',closed='left').sum()
2017-01-01 00:00:00 10
2017-01-01 00:05:00 35
2017-01-01 00:10:00 21
Freq: 5T, dtype: int32
ts.resample('5min',closed='left',label='left').sum()
2017-01-01 00:00:00 10
2017-01-01 00:05:00 35
2017-01-01 00:10:00 21
Freq: 5T, dtype: int32
最终的时间序列是以各面元右边界的时间戳进行标记的。传入label='left'即可用面元的左边界对其进行标记
图10-3说明了“1分钟”数据被转换为“5分钟”数据的处理过程。

图10-3:各种closed、label约定的“5分钟”重采样演示
比如从右边界减去一秒以便更容易明白该时间戳到底表示的是哪个区间。只需通过loffset设置一个字符串或日期偏移量即可实现这个目的
ts.resample('5min',loffset='-1s').sum()
2016-12-31 23:59:59 10
2017-01-01 00:04:59 35
2017-01-01 00:09:59 21
Freq: 5T, dtype: int32
也可以通过调用结果对象的shift方法来实现该目的,这样就不需要设置loffset了
OHLC重采样
金融领域中有一种无所不在的时间序列聚合方式,即计算各面元的四个值:第一个值(open,开盘)、最后一个值(close,收盘)、最大值(high,最高)以及最小值(low,最低)。
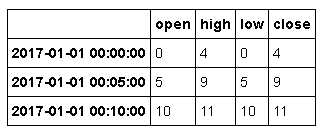
传入how='ohlc'即可得到一个含有这四种聚合值的DataFrame。整个过程很高效,只需一次扫描即可计算出结果
ts.resample('5min').ohlc()
通过groupby进行重采样
另一种降采样的办法是使用pandas的groupby功能。例如,你打算根据月份或星期几进行分组,只需传入一个能够访问时间序列的索引上的这些字段的函数即可
rng=pd.date_range('1/1/2017',periods=100,freq='D')
ts=Series(np.arange(100),index=rng)
ts.groupby(lambda x: x.month).mean()
2017-01-01 0
2017-01-02 1
2017-01-03 2
2017-01-04 3
2017-01-05 4
2017-01-06 5
Freq: D, dtype: int32
ts.groupby(lambda x: x.weekday).mean()
0 50.0
1 47.5
2 48.5
3 49.5
4 50.5
5 51.5
6 49.0
dtype: float64
升采样和插值
在将数据从低频率转换到高频率时,就不需要聚合了
frame=DataFrame(np.random.randn(2,4),
index=pd.date_range('1/1/2017',periods=2,freq='W-WED'),
columns=['Colorado','Texas','New York','Ohio'])
frame[:5]

将其重采样到日频率,默认会引入缺失值(与书上结果不同)
df_daily=frame.resample('D')
df_daily
DatetimeIndexResampler [freq=, axis=0, closed=left, label=left, convention=start, base=0]
假设你想要用前面的周型值填充“非星期三”。resampling的填充和插值方式跟fillna和reindex的一样
frame.resample('D',fill_method='ffill')
e:\python\lib\site-packages\ipykernel_launcher.py:1: FutureWarning: fill_method is deprecated to .resample()
the new syntax is .resample(...).ffill()
"""Entry point for launching an IPython kernel.

这里也可以只填充指定的时期数(目的是限制前面的观测值的持续使用距离)
frame.resample('D').ffill(limit=2)

注意,新的日期索引完全没必要跟旧的相交
frame.resample('W-THU').ffill()

通过时期进行重采样
对那些使用时期索引的数据进行重采样是件非常简单的事情
frame=DataFrame(np.random.randn(12,4),
index=pd.period_range('1-2017','12-2017',freq='M'),
columns=['Colorado','Texas','New York','Ohio'])
frame[:5]
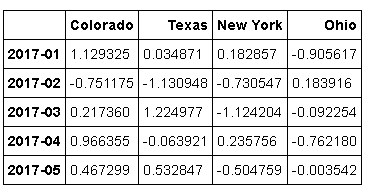
annual_frame=frame.resample('A-DEC').mean()
annual_frame

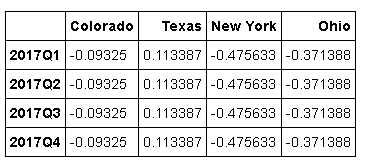
升采样要稍微麻烦一些,因为你必须决定在新频率中各区间的哪端用于放置原来的值,就像asfreq方法那样。convention参数默认为'end',可设置为'start'
annual_frame.resample('Q-DEC').ffill() # Q-DEC: 季度型(每年以12月结束)

annual_frame.resample('Q-DEC',convention='start').ffill()
由于时期指的是时间区间,所以升采样和降采样的规则就比较严格:
1.在降采样中,目标频率必须是源频率的子时期(subperiod)。
2.在升采样中,目标频率必须是源频率的超时期(superperiod)。
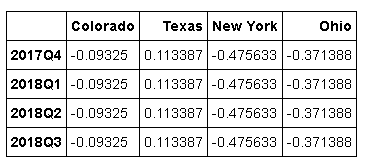
如果不满足这些条件,就会引发异常。这主要影响的是按季、年、周计算的频率。例如,由Q-MAR定义的时间区间只能升采样为A-MAR、A-JUN、A-SEP、A-DEC等
annual_frame.resample('Q-MAR').ffill()
在本章节有些函数舍弃了,比如:resample() is deprecated,the new syntax is .resample(...).mean()。这里使用的是Python3以上的版本练习的。