利用神经网络识别窃电用户
目标:
识别用户是否存在窃电行为
分析思路与流程:
识别用户是否存在窃电行为是预测模型中的分类问题,故采用分类模型
确定模型之后,需要根据模型的要求,归纳窃电用户的关键特征
关键特征的获取,可能需要对数据进行一定的清洗,探索分析及预处理
数据抽取 - 数据探索分析 - 数据预处理,包括清洗和处理缺失值等 - 数据指标构建 - 模型构建及评价
PS:由于数据隐私,本文着重讲 缺失值处理,模型构建和模型的评价,这也是挖掘模型的主要内容
一、数据抽取
二、数据探索分析
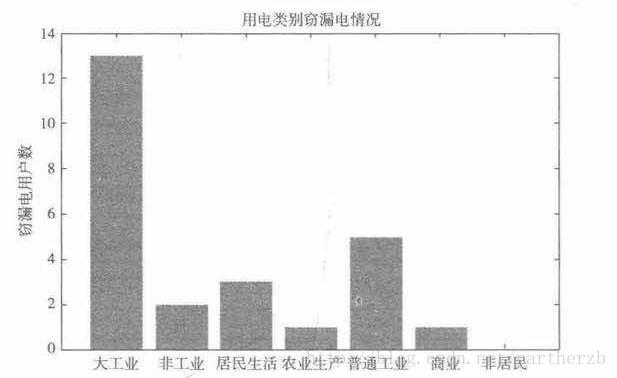
1 分布分析,分析不同用电类别窃电条形图,接下来的分析可以不考虑非居民类别的用电数据
2 周期性分析
正常用户用电量趋势。线形图,用点趋势较为平稳
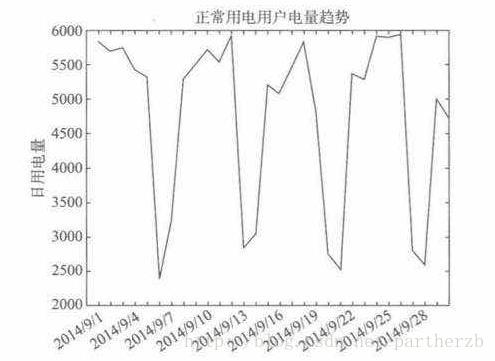
窃电用户用电量趋势。随着时间持续下降,可以作为异常用电的电量指标特征

三、数据预处理
1 数据清洗。清除无关数据,清除居民用电数据,节假日用电数据
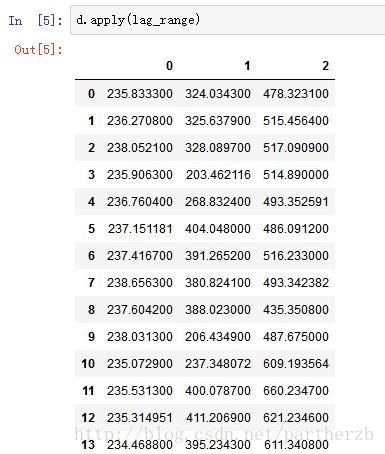
2 缺失值处理。利用拉格朗日插值法填补缺失值
用电量数据:

利用拉格朗日插值法,将缺失值补上。编写的拉格朗日插值函数,代码如下:
def lag_range(x):
from scipy.interpolate import lagrange
for i in range(len(x)):
if (x.isnull())[i]:
x1 = x[list(range(i-5,i)) + list(range(i+1,i+6))]
x2 = x1[x1.notnull()]
x[i]=lagrange(list(x2.index),list(x2))(i)
else:
pass
return x最后,得到插值的结果,并将插值补上
四、构建数据指标,构建专家样本。共有三类指标:电量趋势下降指标、线损指标、告警类指标。通过这三类指标来判断用户是否窃电

总共有291条数据,通过3列指标判断用户是否窃电
五、构建模型
首先,将专家样本划分为训练集和测试集。将数据打散,将前80%的数据(232条)划分为训练集,后20%的数据(59条)划分为测试集。代码如下:
from random import shuffle # 数据打散,建立训练样本和测试样本
m_d_a = d.as_matrix()
shuffle(m_d_a)
p = 0.8
train_a = m_d_a[:int(len(m_d_a)*p)] # 训练集
test_a = m_d_a[int(len(m_d_a)*p):] # 测试集其次,构建神经网络模型,代码如下:
from keras.models import Sequential
from keras.layers import Dense,Activation # 导入神经网络层函数、激活函数
model = Sequential()
model.add(Dense(input_dim=3, units=10)) # 输入层3个输入特征值,中间层10个中间节点
model.add(Activation('relu')) # 中间(隐藏)层使用 rule 函数,快速
model.add(Dense(input_dim=10, units=1)) # 10个中间节点,输出层1个节点
model.add(Activation('sigmoid')) # 输出层函数使用sigmoid函数,
model.compile(loss='binary_crossentropy', optimizer='adam') # 编译模型,损失函数,求解方法
model.fit(train_a[:,0:3], train_a[:,3:], epochs = 1000, batch_size=30) # epochs训练次数,batch_size每批训练数据的大小
predict_result = model.predict_classes(train_a[:,0:3]) # 预测结果最后,使用混淆矩阵,检验测试集的准确度,查看模型预测的效果,代码如下:
def cm_plot(y, yp): # 混淆矩阵函数
from sklearn.metrics import confusion_matrix
cm = confusion_matrix(y, yp)
plt.matshow(cm, cmap=plt.cm.Greens)
plt.colorbar()
for x in range(len(cm)):
for y in range(len(cm)):
plt.annotate(cm[x,y], xy=(x, y), horizontalalignment='center', verticalalignment='center')
cm_plot(test_a[:,3:], predict_result) # 显示混淆矩阵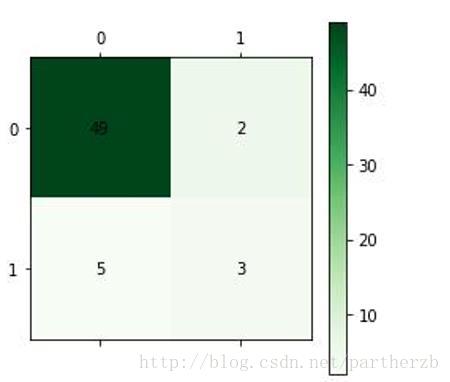
可以看出,分类的准确率为(49+3)/59 = 88.13%,结果还行。其实神经网络的预测结果还可以更高,通过输入更多的训练集量,训练更多的次数,会得到更好的结果