知识图谱表示学习 TransE: Translating Embeddings for Modeling Multi-relational Data
知识图谱表示学习 TransE: Translating Embeddings for Modeling Multi-relational Data
表示学习是深度学习的基础,将数据用更有效的方式表达出来,才能让深度学习发挥出更强大的作用。表示学习避免了手动提取数据特征的繁琐,允许计算机学习特征的同时,也学习如何提取特征。尽管举例基于翻译(translation)的知识图谱表示学习已经过去了五六年的时间,但是仍不可忽略其重要意义。本文聚焦于TransE模型。
1. 引言
多元关系数据(Multi-relational data)对应一个有向图,常用 ( h e a d , l a b e l , t a i l ) (head, label, tail) (head,label,tail)的三元组来表示,有时也记作 ( h e a d , r e l a t i o n , t a i l ) (head, relation, tail) (head,relation,tail)。head表示头结点,tail表示尾结点,在图中对应一个实体,故也称作头实体和尾实体。本文的工作集中于对知识图谱中的多元关系数据进行建模,在不引入额外知识的情况下,可以高效自动获取新的知识。
多元关系数据建模:通常来讲,建模的过程最终落于提取实体之间局部或者全局的连接模式,通过这些连接模式来预测一个特定实体和其他实体之间的关系。难点在于关系数据中包含的实体或者关系可能属于不同的类型,所以对多元关系数据进行建模需要选择合适的方法考虑到不同关系的异质性。
关系作为嵌入空间的转换关系:本文中,我们提出TransE,其中关系作为向量空间转变的桥梁。若存在 ( h , l , t ) (h, l ,t) (h,l,t)的三元组,则实体 t t t的嵌入表示应该等于头实体 h h h的向量+关系向量 l l l。
2. 相关工作
(1) 结构化嵌入表示 Structured Embeddings(SE):将实体嵌入进 R K R^K RK,将关系嵌入进两个变换矩阵 L 1 ∈ R K × K , L 2 ∈ R K × K L_1 \in R^{K \times K}, L_2 \in R^{K \times K} L1∈RK×K,L2∈RK×K, 使得 d ( L 1 h , L 2 t ) d(L_1h, L_2t) d(L1h,L2t)对于一些不存在的关系,距离更大。目标函数为 m i n d ( L 1 h , L 2 t ) min \ d(L_1h, L_2t) min d(L1h,L2t)。
(2) 神经张量网络 Neural Tensor Model(NTM):此处使用的是NTM的特殊形式,对于一个三元组 ( h , l , t ) (h, l, t) (h,l,t),得分为
s ( h , l , t ) = h T L t + l 1 T h + l 2 T t s(h,l,t)=h^TLt+l_1^Th+l_2^Tt s(h,l,t)=hTLt+l1Th+l2Tt
其中, L ∈ R k × k L\in R^{k \times k} L∈Rk×k, L 1 ∈ R k L_1 \in R^k L1∈Rk, L 2 ∈ R k L^2 \in R^k L2∈Rk。与原文略有出入。
3. 基于翻译的模型 TransE
TransE将实体和关系嵌入进 k k k维的空间向量中, k k k为超参数。对于一个知识图谱中的三元组 ( h , l , t ) (h, l, t) (h,l,t),其应该满足向量加法,即 h + l = t h+l=t h+l=t,所以设定能量函数 d ( h + l , t ) d(h+l, t) d(h+l,t),对于所有知识图谱中的三元组,最小化 d d d,具体而言,损失函数 L L L为:
L = ∑ ( h , l , t ) ∈ S ∑ ( h ′ , l , t ′ ) ∈ S ′ [ γ + d ( h + l , t ) − d ( h ′ + l , t ′ ) ] + L = \sum_{(h,l,t)\in S}\sum_{(h',l,t')\in S'} [\gamma + d(h+l, t) - d(h' + l, t')]_{+} L=(h,l,t)∈S∑(h′,l,t′)∈S′∑[γ+d(h+l,t)−d(h′+l,t′)]+
注意到,训练的损失分为正样本和负样本(负采样)两个部分,通过最小化正样本的损失,最大化负样本的距离,达到优化嵌入表示的目的。负样本 S ′ S' S′通过选取一个三元组 ( h , l , t ) (h, l, t) (h,l,t),替换其的一个头实体为其他的头实体 h ′ h' h′,替换其的一个尾实体为其他的尾实体 t ′ t' t′,最终得到 ( h ′ , l , t ) (h', l, t) (h′,l,t)和 ( h , l , t ′ ) (h, l, t') (h,l,t′)来构造负样本。文中同时强调,要约束实体嵌入表示的L2范数为1,防止模型仅增大实体嵌入表示的模长来优化损失函数。
4. 实验
(1) 实验数据:选取Wordnet和Freebase,具体数据如图
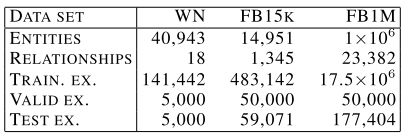
(2) 评价任务和评价指标:使用链接预测(Link prediction)作为评价任务。对于测试集中的每一个三元组 ( h , l , t ) (h,l,t) (h,l,t),使用 h , l h,l h,l计算出 h + l h+l h+l,并计算和其他所有实体的距离 d ( h + l , t ) d(h+l, t) d(h+l,t),按照距离升序排序。使用 m e a n r a n k mean \ rank mean rank和 h i t @ 10 hit@10 hit@10作为评价指标。其中 m e a n r a n k mean \ rank mean rank指的是,对于所有待预测实体 t t t,计算排序位置的均值;而 h i t @ 10 hit@10 hit@10指的是排序出现在前十的实体数目占总测试集实体数目的百分比。
在测试中,可能会出现某些实体排序比测试集实体(gtround truth)靠前的情况,但是这些实体又是真实出现在训练集或者验证集中的(因为知识图谱的链接数量巨大)。为了避免这种情况的出现对评价指标带来的影响,将把去除掉训练集、验证集和测试集中造成影响的三元组得到的结果记为 f i l t e r e d filtered filtered,没有去除过的称为 r a w raw raw。
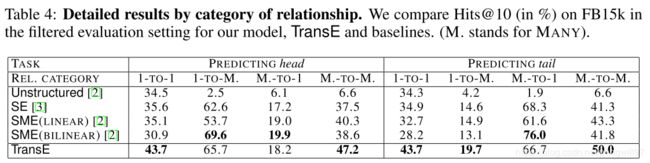
(3) 实验结果:

此外,文章还针对一对一、多对一、一对多、多对多的关系单独进行了测试并给出结果。
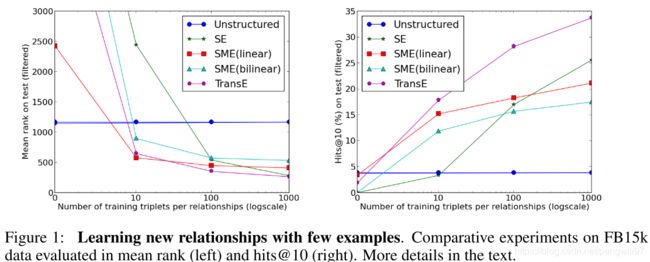
最后,文章给出了再少样本情况下,随着样本数目的增多,各个模型在两个评价指标上的表现。
5. 结论
相较于先前其他模型,TransE模型可以使用最小的参数量得到知识图谱的实体和关系向量表示。尽管无法确定是否所有类型的关系均使用这种方法进行建模,但通过对不同关系类型的进行评估(一对一、一对多等),可以看出和其他模型相比,表现也较为不错。