DataFrame的apply()、applymap()、map()方法
对DataFrame对象中的某些行或列,或者对DataFrame对象中的所有元素进行某种运算或操作,我们无需利用低效笨拙的循环,DataFrame给我们分别提供了相应的直接而简单的方法,apply()和applymap()。其中apply()方法是针对某些行或列进行操作的,而applymap()方法则是针对所有元素进行操作的。
1 map()方法
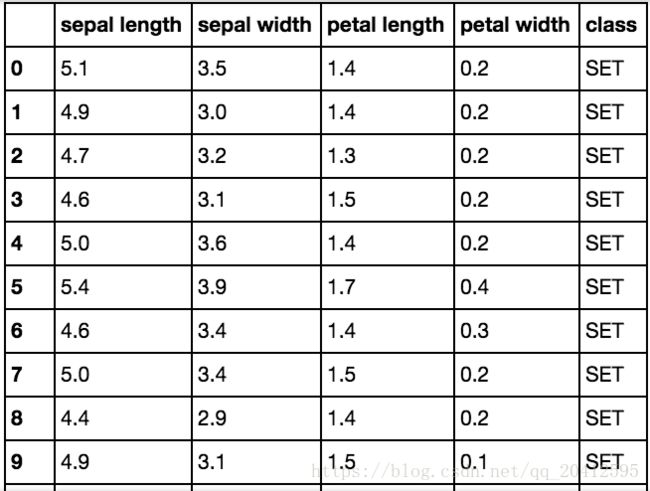
The map method works on series, so in our case, we will use it to transform a column of our DataFrame, which remember is just a pandas Series. Suppose that we decide that the class names are a bit long for our taste and we would like to code them using our special threeletter coding system. We'll use the map method with a Python dictionary as the argument toaccomplish this. We'll pass in a replacement for each of the unique iris types:
df['class'] = df['class'].map({'Iris-setosa': 'SET', 'Iris-virginica':'VIR', 'Iris-versicolor': 'VER'})
df
2 Apply()方法
The apply method allows us to work with both DataFrames and Series. We'll start with an example that would work equally well with map, then we'll move on to examples that would work only with apply.
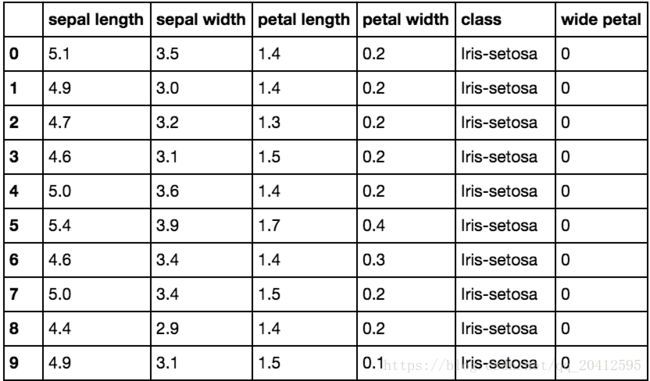
Using the iris DataFrame, let's make a new column based on the petal width. We previously saw that the mean for the petal width was 1.3. Let's now create a new column in our DataFrame, wide petal, that contains binary values based on the value in the petal width column. If the petal width is equal to or wider than the median, we will code it with a 1, and if it is less than the median, we will code it 0. We'll do this using the apply method on the petal width column:
df['wide petal'] = df['petal width'].apply(lambda v: 1 if v >= 1.3 else 0)
df
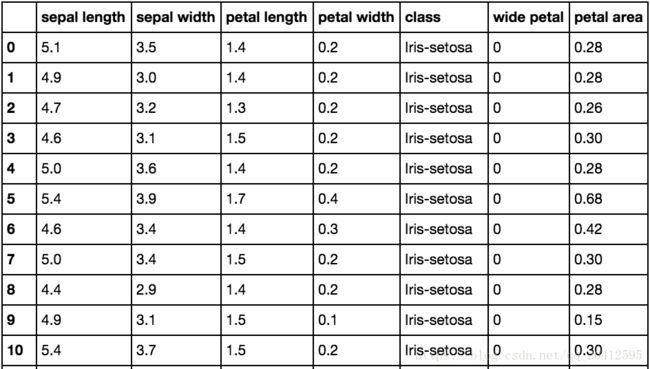
df['petal area'] = df.apply(lambda r: r['petal length'] * r['petal width'],axis=1)
df
3 Applymap()方法
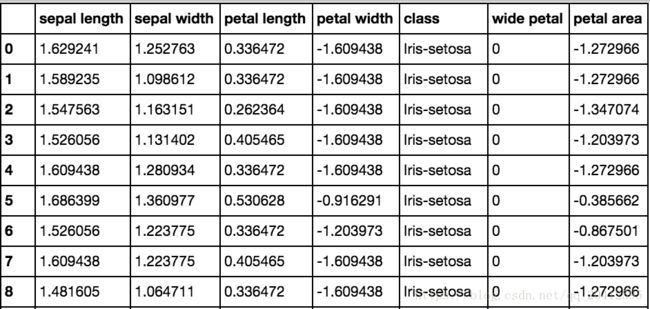
We've looked at manipulating columns and explained how to work with rows, but suppose that you'd like to perform a function across all data cells in your DataFrame; this is where applymap is the right tool. Let's take a look at an example:
df.applymap(lambda v: np.log(v) if isinstance(v, float) else v)
4 Groupby方法
df.groupby('class').mean()
df.groupby('petalwidth')['class'].unique().to_frame()
df.groupby('petalwidth')['class'].unique().to_frame()
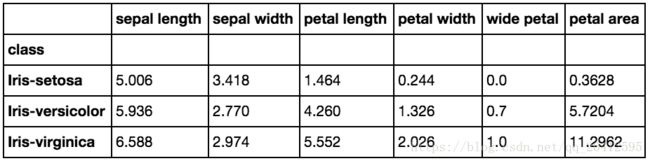
df.groupby('petal width')['class'].unique().to_frame()
df.groupby('class').describe()
df.groupby('class')['petal width'].agg({'delta': lambda x: x.max() - x.min(), 'max': np.max, 'min': np.min})
简单来说,apply()方法 可以作用于DataFrame 还有Series, 作用于一行或者一列时,我们不妨可以采用,因为可以通过设置axis=0/1 来把握,demo如下:
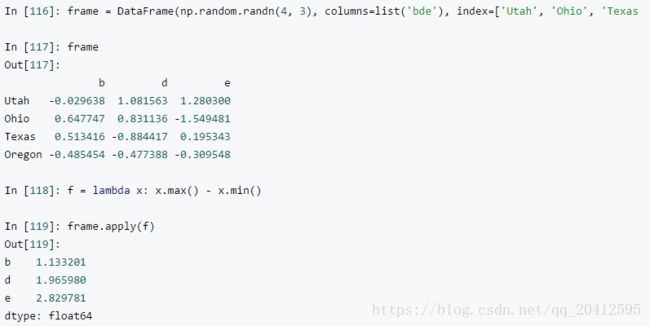
applymap() 作用于每一个元素
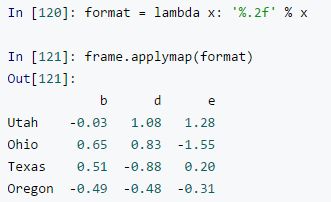
map可以作用于Series每一个元素的

总的来说,map()、aply()、applymap()方法是一种对series、dataframe极其方便的应用与映射函数。
最后,非常重要的一点,这些映射函数,里面都是可以放入自定义函数的。
tips.head()
Out[34]:
| total_bill | tip | smoker | day | time | size | tip_pct | |
|---|---|---|---|---|---|---|---|
| 0 | 16.99 | 1.01 | No | Sun | Dinner | 2 | 0.059447 |
| 1 | 10.34 | 1.66 | No | Sun | Dinner | 3 | 0.160542 |
| 2 | 21.01 | 3.50 | No | Sun | Dinner | 3 | 0.166587 |
| 3 | 23.68 | 3.31 | No | Sun | Dinner | 2 | 0.139780 |
| 4 | 24.59 | 3.61 | No | Sun | Dinner | 4 | 0.146808 |
def top(df,n=5,column='tip_pct'):
return df.sort_values(by=column)[-n:]
tips.groupby('smoker').apply(top)
Out[38]:
| total_bill | tip | smoker | day | time | size | tip_pct | ||
|---|---|---|---|---|---|---|---|---|
| smoker | ||||||||
| No | 88 | 24.71 | 5.85 | No | Thur | Lunch | 2 | 0.236746 |
| 185 | 20.69 | 5.00 | No | Sun | Dinner | 5 | 0.241663 | |
| 51 | 10.29 | 2.60 | No | Sun | Dinner | 2 | 0.252672 | |
| 149 | 7.51 | 2.00 | No | Thur | Lunch | 2 | 0.266312 | |
| 232 | 11.61 | 3.39 | No | Sat | Dinner | 2 | 0.291990 | |
| Yes | 109 | 14.31 | 4.00 | Yes | Sat | Dinner | 2 | 0.279525 |
| 183 | 23.17 | 6.50 | Yes | Sun | Dinner | 4 | 0.280535 | |
| 67 | 3.07 | 1.00 | Yes | Sat | Dinner | 1 | 0.325733 | |
| 178 | 9.60 | 4.00 | Yes | Sun | Dinner | 2 | 0.416667 | |
| 172 | 7.25 | 5.15 | Yes | Sun | Dinner | 2 | 0.710345 |