中文分词 mmseg nginx 模块开发
一、nginx模块开发
Nginx 是一款高性能web服务器,因此,工作业务中需要借助nginx强大的网络服务功能,往往需要开发和定制相应的 Nginx 模块满足业务需求。
基本上作为第三方开发者最可能开发的就是三种类型的模块,即handler,filter和load-balancer。Handler模块就是接受来自客户端的请求并产生输出的模块,也是我们使用最多的一个模块。有关nginx模块开发的入门资料,作者十分推荐淘宝写的文档, 点我,点我。相信看完这个,对nginx模块开发会有一定的认识。要想对nginx源码有个认识也可以参考作者之前学习nginx写的源码学习文档 nginx源码分析。
二、mmseg算法
关于中文分词 参考之前写的jieba分词源码分析 jieba中文分词,有关mmseg分词算法见上一个博客介绍的 mmseg分词算法及实现。
mmseg的主要目录结构如下:
mmseg
├── build : 生成*.so 动态链接库
├── data :词典数据
└── src : 实现源码
└── util : 字符串处理通用库代码采用c++11实现(g++ version >= 4.8 is recommended),已有详细注释,源码。
https://github.com/ustcdane/mmseg 。
mmseg实现起来采用了{.h, .cpp} and {.hpp} 。Mmseg.hpp格式的代码在开发nginx模块时 好处是方便使用,无需链接,直接包含.hpp文件即可。此外有的时候需要向以动态库的方式提供给使用人员,并只想暴露一定的接口时,此时分词算法mmseg采用{.h, .cpp} 文件格式组成代码,这样可以把这部分代码编译成*.so的动态链接库,mmseg算法也支持生成动态链接库,进入目录build , 里面有已经写好的Makefile文件 直接make 即可生成 libmmseg.so的 动态链接库文件,从而方便在其它程序中调用。
三、mmseg nginx模块开发
nignx HTTP 模块开发网上也有很多例子,比较有名的就是nginx_hello 模块,有兴趣的先去网上找找这个例子看看,自己动手编译下。
下面介绍mmseg nginx模块开发的源码组织形式:
nginx_mmseg/ # mmseg nginx 模块源码目录
├── config # config文件,用来指导nginx生成makefile文件
├── Makefile_example # nginx objs/Makefile 样例
│ ├── Makefile.bk.hpp #mmseg无链接的 Makefile
│ └── Makefile.bk.so # 动态链接库形式的Makefile
├── mmseg # mmseg源码
│ ├── build # 生成动态链接库
│ ├── data
│ ├── LICENSE
│ ├── main.cpp
│ ├── README.md
│ └── src
├── ngx_http_handle_interface.cpp # 处理 HTTP请求的主要函数
├── ngx_http_handle_interface.h
├── ngx_http_mmseg_module.c
├── ngx_http_mmseg_module.h # nginx 模块配置相关
├── README.md
└── tags
下面介绍mmseg nginx模块开发的一些重要知识:
nginx模块开发
可以通过参考资料中了解 nginx模块的基本结构,包括:模块配置结构,模块配置指令,模块上下文结构,模块的定义,handler模块的基本结构等等,这部分内容参见源码{ngx_http_mmseg_module.h ngx_http_mmseg_module.c}。
其中,handler模块必须提供一个真正的处理函数,这个函数负责对来自客户端请求的真正处理。这个函数的处理,既可以选择自己直接生成内容,也可以选择拒绝处理,由后续的handler去进行处理,或者是选择丢给后续的filter进行处理。来看一下这个函数的原型申明。typedef ngx_int_t (*ngx_http_handler_pt)(ngx_http_request_t *r);r是http请求。 该函数处理成功返回NGX_OK,处理发生错误返回NGX_ERROR,拒绝处理(留给后续的handler进行处理)返回NGX_DECLINE。 返回NGX_OK也就代表给客户端的响应已经生成好了,否则返回NGX_ERROR就发生错误了。在我们的项目中这个处理回调函数是ngx_http_mmseg_module.c中的 static ngx_int_t ngx_http_mmseg_handler(ngx_http_request_t *r)。
当回调这个函数时,表示 Nginx 收到了 HTTP 请求,并且 HTTP 的 header 数据已经被解析完毕的时候(对HTTP不是很了解的话,可以参考 这篇HTTP讲解的blog。)。
一般情况下我们只处理HTTP的GET和POST请求,下面分别介绍下这两种情况:
- GET
GET 请求通常是只需要 header 数据即可,不需要 body 数据。 所以当 GET 请求过来的时候,我们只需要 在调用 ngx_http_handle_interface.cpp 中的 int ngx_http_do_get(ngx_http_request_t *r)函数处理,这个函数其实很简单,先获得请求ngx_http_request_t的配置信息,并解析request的参数信息(即获得要分词的句子),对分词句子进行转码后调用我们的mmseg算法进行分词,并把结果写入 ngx_chain_t out,再通过 ngx_http_output_filter(r, &out)函数将结果发送给客户端即可,这样就完成了get请求的过程。 - POST
处理 POST 请求时,不仅需要 HTTP 的 header,也需要 body 数据, body 数据大小是通过 header 里面的 content-length 长度指定。 处理post 方法时注意使用ngx_http_read_client_request_body(r, ngx_http_do_post),来看下 ngx_http_read_client_request_body方法的原型:
ngx_int_t
ngx_http_read_client_request_body(ngx_http_request_t *r,ngx_http_client_body_handler_pt post_handler);
参数r就是要处理的请求,post_handler则是body接收完成后的回调方法。在worker进程中,调用ngx_http_read_client_request_body是不会阻塞的,要么读完socket上的buffer发现不完整立刻返回,等待下一次EPOLLIN事件,要么就是读完body了(调用 recv 函数去接收数据。 并将该数据累加起来,当累计的数据量大于等于 content-length 时,代表该请求的 body 数据已经被接收完毕),调用用户定义的post_handler方法去处理body。因此,我们需要注册一个回调函数(post_handler)来告诉 nginx, 当 body 数据接收完毕之时,就是调用我 这个回调函数。 这个回调函数在源码是ngx_http_handle_interface.cpp 中的 void ngx_http_do_post(ngx_http_request_t *r)函数。
ngx_http_request_t
一个http请求,包含请求行、请求头、请求体、响应行、响应头、响应体。nginx中代表http请求的数据结构是ngx_http_request_t, ngx_http_request_s是nginx中非常重要的一个结构体,贯穿于htpp请求处理的整个过程中。其初始化过程为:函数ngx_epoll_process_events { src/event/modules/ngx_epoll_module.c }接收到网络IO事件EPOLLIN后(即socket上有数据可读),调用了这个回调方法ngx_http_init_request {src/http/ngx_http_request.c。ngx_http_init_request开始处理这个事件,首先它把基本的ngx_http_request_t变量(nginx HTTP框架中由始至终用到的)初始化,并从内存池中为每个连接ngx_http_request_t * r 分配一个内存池,你可以经常看到 ngx_palloc(r->pool, …) or ngx_pcalloc (r->pool, …)之类的内存分配,其中ngx_pcalloc对分配的内存进行置零。 通过 ngx_palloc or ngx_pcalloc 分配出来的内存不需要手动回收。 因为该 r->pool 这个内存池是每个连接创建一个内存池。 当该连接断开的时候,该内存池会被整个释放掉。所以不需要担心内存泄露的问题。有关ngx_http_request_t结构体详解 可以看源码或者上网查下,这方面的资料也挺多的。
四、nginx_mmseg 安装编译
需要先下载 pcre软件包,假设下载了pcre-8.37 并放在user目录下。
下载源码
git clone https://github.com/ustcdane/nginx_mmseg.git /user/nginx_mmseg
configure
进入nginx目录,cd nginx-1.8.0,运行configure生成Makefile文件,Makefile文件在objs目录下:
./configure –prefix=/user/nginx-1.8.0/bin –add-module=/user/nginx_mmseg/ –with-pcre=/user/pcre-8.37
解释下各个意义:
—prefix=nginx的运行目录,还有—add-module=自己的module目录,—with-pcre=pcre目录。
修改Makefile
因为 nginx_mmseg 是 C++ 源码,所以作为 nginx 模块编译的时候需要 修改 obj/Makefile,
修改后的Makefile一定要备份,因为重新configure或者make clean都会把这个makefile给删掉,这样心血就白费了。
1. 首先把CC=cc改为CC=gcc,然后加入CXX=g++,并把LINK指定为CXX
CXXFLAGS=$(CFLAGS) -std=c++11 -g
2. 在ALL_INCS中添加你用到的.h文件的路径
3. 在ADDON_DEPS中添加你的模块需要依赖的.h文件(不需要扯到mmseg的.h or .hpp)
4. 在objs目录下添加你的module下的.c或者.cpp文件生成的.o文件
5. 在LINK后面也加上这些.o
6. 加上这些.o文件所需要的编译选项,cpp用CXX编译,c用CC编译,然后再make就完事了。把objs目录下的nginx可执行文件拷贝到运行目录下/user/nginx-1.8.0/bin,然后修改bin/conf的nginx.conf文件,添加我们需要的words_path和charFreq_path参数,即词典的路径,如下面的代码所示,执行bin/nginx就能提供mmseg的HTTP服务了。
location / {
root html;
index index.html index.htm;
}
location /test {
words_path /user/nginx_mmseg/mmseg/data/words.dic;
charFreq_path /user/nginx_mmseg/mmseg/data/chars.dic;
} 有不清楚的可以参考目录下 Makefile_example 文件 Makefile.bk.hpp和 Makefile.bk.so,
这是把mmseg算法两种形式供nginx模块调用的方式:Makefile.bk.hpp是在模块开发时直接包含分词算法Mmseg.hpp 无需额外的链接;Makefile.bk.so是把分词算法mmseg包装成.so的动态链接库形式供nginx模块调用。两个 Makefile不同之处在于$(LINK) 的时候,.so在LINK时的写法是:
-L$(MMSEG_PATH)/../build -lmmseg -lpthread -lcrypt /search/daniel/pcre-8.37/.libs/l ibpcre.a -lz
注意 在使用动态链接库 .so会出现如下情况:
./nginx: error while loading shared libraries: libmmseg.so: cannot open shared object file: No such file or directory。
这是因为nginx 找不到我们的动态链接库 libmmseg.so,因此需要在路径LD_LIBRARY_PATH中添加,方法如下:
在 /etc/profile 中添加
export LD_LIBRARY_PATH=$LD_LIBRARY_PATH:/user/nginx_mmseg/mmseg/build/
然后 source /etc/profile 即可。
测试
- GET
curl “http://127.0.0.1/test?data=研究生命起源”
结果:研究 生命 起源
浏览器打开上述链接也可以,浏览器的页面编码设置为 utf-8 。 - POST
curl –data “研究生命起源” “http://127.0.0.1/test”
结果:研究 生命 起源
具体源码注释见:
github 。
细心的童鞋,注意到了上面mmseg基于nginx的HTTP模块开发,每个worker进程都会加载数据,当数据量比较大,显然太费内存了,又由于Linux系统进程fork时采用了copy on write的技术,因此,只要master进程加载了数据,master进程fork的worker就会共享这些数据,所以写了一个基于mater加载数据的例子,详情见: github [data_load_on_master]
在nginx_mmseg_new/mmseg/src/Mmseg.cpp 中函数load加载数据阶段,为了测试大数据添加了如下代码:
#ifdef DEBUG_LEVEL // 内存占用测试
typedef struct test_ {
long long l1;
long long l2;
long long l3;
long long l4;
long long l5;
}test_;
mmsegSpace::MMSeg::test_* p_memory_test = new test_[100000000];
memset(p_memory_test, 0, sizeof(test_)*100000000);
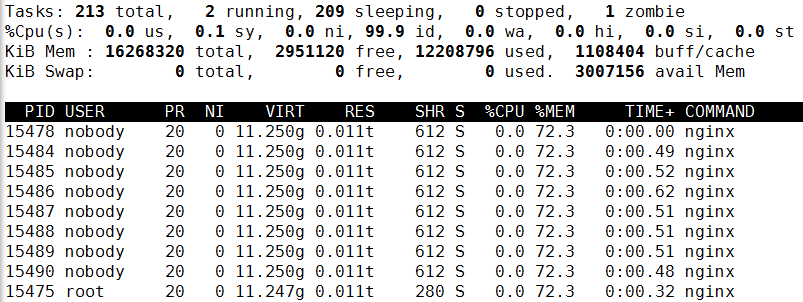
#endif效果如下图:

通过图中可以看出来, 机器实际内存16GB。结合上面的内存占用测试代码我们也能计算出来:p_memory_test 所占内存为:(100000000*5*8)/(1024*1024)=3814MB=3.72G,加上分词字典、词频所占内存符合top所示3.771GB,但top命令显示1个master和8个worker各占用了3.771GB的内存空间(),这样算的话nginx大概占用了9*3.7=33.94GB,显然不符实际情况,因为我的机器内存才16GB!所以可见cow生效了!!,详情见代码。
当master申请的内存超过机器内存一半时,会出现nginx [emerg] fork() failed (12: Cannot allocate memory,这是由于系统级的限制,当所申请内存超过机器内存一半时会出现这个错误,需要修改文件/etc/sysctl.conf 中的 overcommit_memory值,其取值有0,1,2对应的含义如下:
- 0表示内核将检查是否有足够的可用内存供应用进程使用;如果有足够的可用内存,内存申请允许;否则,内存申请失败,并把错误返回给应用进程。
- 1表示内核允许分配所有的物理内存,而不管当前的内存状态如何。
- 2 表示内核允许分配超过所有物理内存和交换空间总和的内存
利用如下三种方法之一修改overcommit_memory值:
vim /etc/sysctl.conf 添加 vm.overcommit_memory=1
sysctl vm.overcommit_memory=1
echo 1 > /proc/sys/vm/overcommit_memory
在我的机器(16GB内存)上实验结果如下:
参考
- http://blog.csdn.net/russell_tao/article/details/5637451
- http://tengine.taobao.org/book/chapter_03.html#handler