干货 | 视频显著性目标检测(文末附有完整源码)

显著性检测近年来引起了广泛的研究兴趣。这种日益流行的原因在于在各种视觉任务(如图像分割、目标检测、视频摘要和压缩等)中有效地使用了这些模型。显著性模型大致可分为两类:人眼注视预测和显著目标检测。根据输入类型,可进一步分为静态显著性模型和动态显著性模型。
背 景
将CNN应用于视频显著性的第一个问题是缺乏足够大、标记密集的视频训练数据。据我所知,CNN在计算机视觉方面的成功在很大程度上归功于大规模标注图像的可用性。然而,现有的视频数据集太小,无法为CNN提供足够的训练数据。

[9] O. Russakovsky, J. Deng, H. Su, J. Krause, S. Satheesh, S. Ma, Z. Huang,A. Karpathy, A. Khosla, M. Bernstein et al., “Imagenet large scale visual recognition challenge,” International Journal of Computer Vision, vol.115, no. 3, pp. 211–252, 2015.
[10] T. Brox and J. Malik, “Object segmentation by long term analysis of point trajectories,” in European Conference on Computer Vision, 2010, pp. 282–295.
[11] F. Li, T. Kim, A. Humayun, D. Tsai, and J. M. Rehg, “Video segmentation by tracking many figure-ground segments,” in IEEE International Conference on Computer Vision, 2013, pp. 2192–2199.
[12] F. Galasso, N. Shankar Nagaraja, T. Jimenez Cardenas, T. Brox, and B. Schiele, “A unified video segmentation benchmark: Annotation, metrics and analysis,” in IEEE International Conference on Computer Vision, 2013, pp. 3527–3534.
[13] F. Perazzi, J. Pont-Tuset, B. McWilliams, L. V. Gool, M. Gross, and A. Sorkine-Hornung, “A benchmark dataset and evaluation methodology for video object segmentation,” in IEEE Conference on Computer Vision and Pattern Recognition, 2016.
在上表中,列出了ImageNet数据集的统计数据和广泛采用的视频目标分割数据集,包括FBMS、SegTrackV 2、VSB 100和Davis。
可以看到,现有的视频数据集在质量和数量上都很少与现有的图像数据集(如ImageNet)相匹配。另外,考虑到同一视频片段帧间的高度相关性,现有的视频数据集远远不能满足像视频显著目标检测等像素级视频应用的CNN训练需求。另一方面,就目前而言,创建如此大规模的视频数据集通常是不可行的,因为注释视频既复杂又耗时。
为此就提出了一种综合生成标记视频训练数据的视频数据增强方法,该方法充分利用了现有的大规模图像分割数据集。模拟视频数据易于获取和快速生成,接近真实视频序列,呈现各种运动模式、变形,伴随着自动生成的注解和光流。通过这些自动生成的视频的实验结果,很好地证明了新策略的实用性。
摘 要 & 概 述
为了有效地检测视频中的显著区域,提出了一种深度学习模型。它解决了两个重要的问题:(1)深度视频显著性模型训练,缺乏足够大的像素标注视频数据;(2)快速视频显著性训练和检测。
提出的深度视频显著性网络由两个模块组成,分别用于捕获视频的时空显著性信息。动态显著性模型显式地结合了静态显著性模型中的显著性估计,直接产生时空显著性推理,而不需要耗时的光流计算。进一步提出了一种新的数据增强技术,它模拟现有带注释的图像数据集中的视频训练数据,使新的网络能够学习不同的显著性信息,并防止与有限数量的训练视频过度匹配。利用合成视频数据(150K视频序列)和真实视频,新提出的深度视频显著性模型成功地学习了时空显著性线索,从而产生了准确的时空显著性估计。
相 关 工 作
 1、显著性检测
1、显著性检测
显著性检测在计算机视觉中得到了广泛的研究,其显着性模型一般可分为视觉注意预测或显著目标检测。前几种方法:
L. Itti, C. Koch, E. Niebur et al., “A model of saliency-based visual attention for rapid scene analysis,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 20, no. 11, pp. 1254–1259, 1998.
J. Harel, C. Koch, and P. Perona, “Graph-based visual saliency,” in Advances in Neural Information Processing Systems, 2006, pp. 545–552.
T. Judd, K. Ehinger, F. Durand, and A. Torralba, “Learning to predict where humans look,” in IEEE International Conference on Computer Vision, 2009, pp. 2106–2113.
以上试图预测人类观察者可能注视的场景位置。显著目标检测旨在统一突出区域,这已被证明有利于广泛的计算机视觉应用。对显著性模型的更详细审查见:
A. Borji and L. Itti, “State-of-the-art in visual attention modeling,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 35, no. 1, pp. 185–207, 2013.
A. Borji, M.-M. Cheng, H. Jiang, and J. Li, “Salient object detection: A benchmark,” IEEE Transactions on Image Processing, vol. 24, no. 12, pp. 5706–5722, 2015.
根据显著性模型的输入,将显著性模型进一步分为静态模型和动态模型。在本次讲解中中,我们的目标是检测视频中的突出目标区域。图像显著性检测已经被广泛的研究了几十年,大多数的方法都是由众所周知的自下而上的策略驱动的。早期的自下而上模型主要是基于检测对比度,假设视场中的显著区域首先从周围环境中突出出来,然后根据不同的数学原理计算基于特征的对比度。同时,一些其他的机制也提出采用一些先验知识,例如背景先验或全局信息来检测静止图像中的突出物体。
Y. Wei, F. Wen, W. Zhu, and J. Sun, “Geodesic saliency using background priors,” in European Conference on Computer Vision, 2012, pp. 29–42.
W. Zhu, S. Liang, Y. Wei, and J. Sun, “Saliency optimization from robust background detection,” in IEEE Conference on Computer Vision and Pattern Recognition, 2014, pp. 2814–2821.
近年来,深度学习技术被引入到图像显著性检测中。这些方法通常使用CNN审查大量区域候选,从中选择突出的对象。目前,越来越多的方法倾向于以端到端的方式学习,并通过全卷积网络(FCNs)直接生成像素级显著性映射。
近年来,显著性检测的边界已经扩展到捕获相关图像/视频之间的共同显着性,用视频序列或场景理解推断显着性事件。然而,上述方法与传统的显著性检测方法存在显著差异,特别是考虑到它们的目标和核心困难。
W. Wang, J. Shen, X. Li, and F. Porikli, “Robust video object cosegmentation,” IEEE Transactions on Image Processing, vol. 24, no. 10, pp. 3137-3148, 2015.
W. Wang, and J. Shen, “Higher-order image co-segmentation,” IEEE Transactions on Multimedia, vol. 18, no. 6, pp. 1011–1021, 2016.
D. Zhang, D. Meng, and J. Han, “Co-saliency detection via a self-paced multiple-instance learning framework,” IEEE Transactions on Pattern Analysis and Machine Intelligence, vol. 39, no. 5, pp. 865–878, 2017.
动态场景中的深度学习模型
主要研究动态场景中计算机视觉应用的著名深入学习模型,包括行为识别,目标分割,目标跟踪,注意预测和语义切分,并探讨它们的结构和训练方案。这将有助于澄清新方法与以往的努力有何不同,并将有助于突出效力和效率方面的重要利益。许多方法直接将单个视频帧输入到对图像数据进行训练的神经网络中,并采用各种技术对结果进行时间或运动信息的后处理。
不幸的是,这些神经网络放弃了对时间信息的学习,而时间信息在视频处理应用中往往是非常重要的。(K. Simonyan and A. Zisserman, “Two-stream convolutional networks for action recognition in videos,” in Advances in Neural Information Processing Systems, 2014, pp. 568–576.)提出了一种著名的用于视频中动作识别的CNN训练结构,该结构结合了两个流卷积网络来学习图像和运动的互补信息。其他工作采用这种结构进行动态注意预测和视频对象分割。然而,这些方法在多帧密集光流下训练模型,计算量很大。在人体姿态估计和视频对象处理方面,引入了在线学习策略,以提高人体姿态估计和视频对象处理的性能。在处理输入视频之前,这些方法产生各种训练样本,用于微调从图像数据中学习到的神经网络,从而使模型能够针对测试视频序列中感兴趣的对象进行优化。显然,这些模型很费时,而精调的模型只专门针对特定的对象类。
视频显著性检测
框架概述
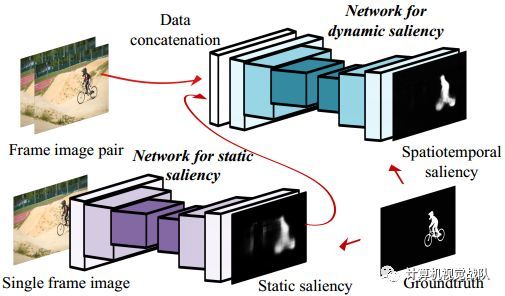
在下面详细介绍之前,我首先对深度视频显著性模型进行概述。在较高的层次上,将视频帧输入到神经网络中,网络依次输出显著性映射,其中较亮的像素表示更高的显著性值。该网络使用视频序列和图像进行训练,并在一般动态场景中学习时空显著性。
上图显示出了所提出的深度视频显著性模型的结构。在经典的人类视觉感知研究的启发下,即静态显著性线索和动态显著性线索对视频显著性的贡献,设计了两个模块,同时考虑了场景的时空特性。
第一个模块是以单帧图像为输入,捕获静态性。它采用全卷积网络(FCNs)生成像素级显著性估计,并利用以往优秀的预训练模型对大规模图像数据集进行预处理。在丰富的图像显著性基准的推动下,该模块被有效地训练来获取感兴趣对象的各种静态显著性信息。第二模块以来自第一模块的帧对和静态显著性作为输入,生成最终的动态显著性结果。这个网络是从合成的和真实的标记视频数据中训练出来的。
静态显著性深层网络

在网络顶部,采用1×1卷积核的卷积层将特征映射y通过sigmoid激活单元映射成精确的显著性预测映射p。对pred使用sigmoid层,以便输出中的每个条目在0和1的范围内有一个实际值。由于FCN的使用,网络允许对任意大小的输入图像进行操作,并保留空间信息。上图说明了深层网络的静态显着性的详细配置。
动态显著性的深层网络

现在我们来描述时空显著性网络。如上图所示,该网络与基于FCN的静态显著性网络结构相似,包括多层卷积和反卷积。动态网络与静态显著性结果一起学习动态显著性信息,从而直接生成时空显著性估计。
与某些技术中常用的双流网络结构相比,新技术将静态网络的输出合并为动态显著性模型,直接产生时空显著性结果。这种架构有两个优点。首先,将动态和静态显著性融合显式地嵌入到动态显著性网络中,而不是训练时空特征的双流网络,专门设计了一个时空特征融合网络。其次,该模型利用光流图像对相邻两帧的时间信息进行直接推断,而不是以往的方法,从而获得了较高的计算效率。
实验结果
实验结果可视化


(a)使用固定阈值分割显著性图,从而获得平均精确ROC曲线;(B)F-score;(C)平均MAE。注意,新技术的算法在不同的度量标准中始终优于其他方法。

静态显著性结果与最终时空显著性结果的定性比较。自上而下:输入帧图像,通过静态显著性网络获得显著性结果,通过整个视频显著性模型获得时空显著性结果。

新技术的计算负荷和处理480p视频的时间效率与最先进的视频显著性方法比较
![]()
源码:https://github.com/wenguanwang/ViSalientObject
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群。计算机视觉战队主要涉及机器学习、深度学习等领域,由来自于各校的硕博研究生组成的团队,主要致力于人脸检测、人脸识别,多目标检测、目标跟踪、图像分割等研究方向。
我们开创一段时间的“计算机视觉协会”知识星球,也得到很多同学的认可,我们定时会推送实践型内容与大家分享,在星球里的同学可以随时提问,随时提需求,我们都会及时给予回复及给出对应的答复。

微信学习讨论群也可以加入,我们会第一时间在该些群里预告!
