【每周NLP论文推荐】从预训练模型掌握NLP的基本发展脉络
读论文是做AI的人必需要下的功夫,所以咱们开通了专栏《每周NLP论文推荐》。本着有三AI的一贯原则,即系统性学习,所以每次的论文推荐也会是成系统的,争取每次能够把一个领域内的“故事”基本说清楚。
先通过无监督学习在大规模语料上进行Pre-Training,再通过Fine-tune的方式,在一定语料上进行有监督学习,进行下游任务的学习,是NLP领域近来的以大趋势。这次论文推荐就从词向量开始,依次介绍到最新的XLnet。
作者&编辑 | 小Dream哥
1 词向量的提出
在这篇文章中,Bengio等人提出了神经语言模型(NNLM),而它的副产品,词向量,可以实现词的分布式表征。词向量模型是一个重要的工具,可以把真实世界抽象存在的文字转换成可以进行数学公式操作的向量,对这些向量的操作,是NLP所有任务都在做的事情。NNLM提出了一种可能的获得词向量的稠密式表征的手段,具有重要意义。
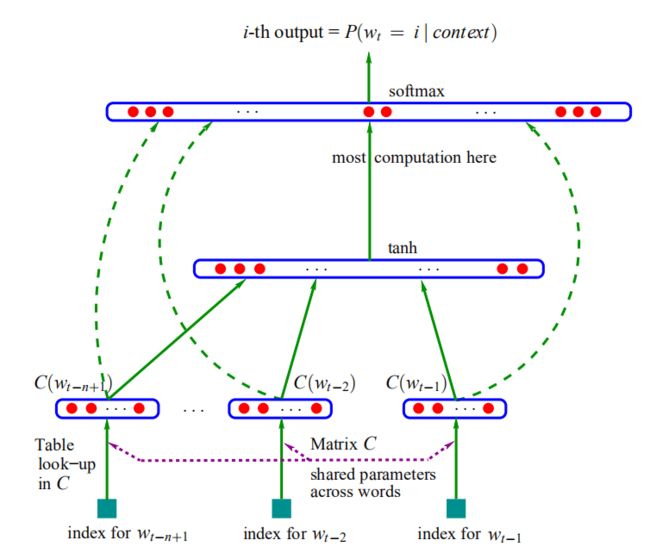
[1] D'informatique Et Recherche Operationnelle, Departement & Bengio, Y & Ejean Ducharme, R & Vincent, Pascal & De Recherche Mathematiques, Centre. (2001). A Neural Probabilistic Language Model.
2 Word2vec的提出
这篇文章提出了一种能够真正高效获得词向量的手段,进而促进了后续NLP的快速发展。Mikolov等研究者在这篇论文中提出了连续词袋模型CBOW和 Skip-Gram 模型,通过引入负采样等可行性的措施。使得学习高质量的词向量成为现实。
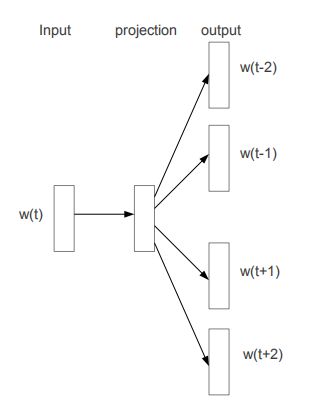
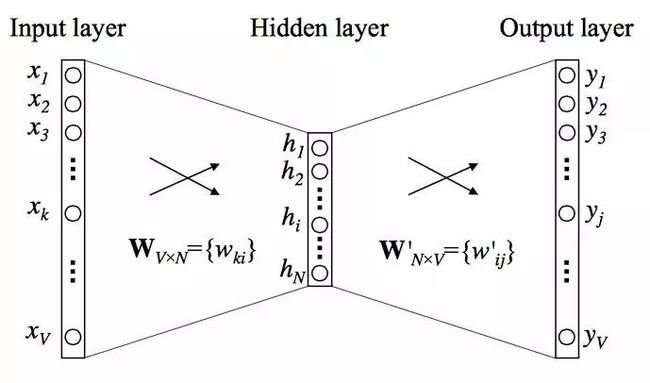
[2] Mikolov T , Sutskever I , Chen K , et al. Distributed Representations of Words and Phrases and their Compositionality[J]. Advances in Neural Information Processing Systems, 2013.
3 ELMo词向量的动态表征
训练得到的词向量表征的词语之间的信息其实有限。词向量一个难以解决的问题就是多义词的问题,例如“bank”在英文中有“河岸”和“银行”两种完全不同意思,但是在词向量中确实相同的向量来表征,这显然不合理。
ELMO的本质思想是:用事先训练好的语言模型学好一个单词的Word Embedding,此时多义词无法区分,不过这没关系。在实际使用Word Embedding的时候,单词特定的上下文就可以知道,这个时候模型可以根据上下文单词的语义去调整单词的Word Embedding表示,这样经过调整后的Word Embedding更能表达在这个上下文中的具体含义,也就能克服多义词动态表征的问题。

[3] Peters, Matthew E. , et al. "Deep contextualized word representations." (2018).
4 通用语言模型GPT
Generative Pre-Training(GPT)采用单向语言模型,用Transformer作为特征抽取器,在当时NLP领域的各项任务中都取得了非常不错的效果。
从GPT中可以看到一个明显的趋势:越来越多的将原来在下游任务中做的事情,搬到预训练时来做。
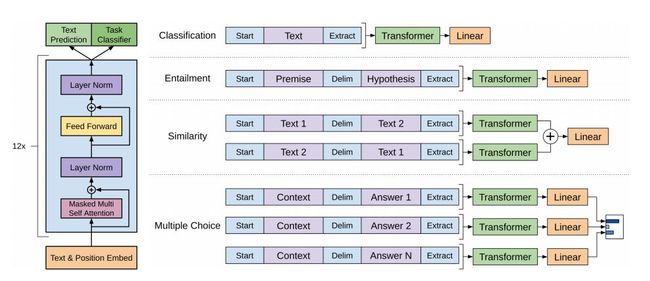
[4] Alec RadfordKarthik, NarasimhanTim, SalimansIlya Sutskever. (2018). Improving Language Understanding by Generative Pre-Training.
5 BERT的横空出世
谷歌推出BERT(Bidirectional Encoder Representation from Transformers)模型,刷新了几乎所有NLP任务的榜单,一时风头无两。仔细看BERT的实现,其与GPT的主要差别在于,BERT用的“双向语言模型”,它通过MASK掉预料中的部分词再重建的过程来学习预料中词语序列中的语义表示信息,同样采用Transformer作为特征抽取器。BERT的出现,因其效果太好,几乎让其他所有的NLP工作都黯然失色。
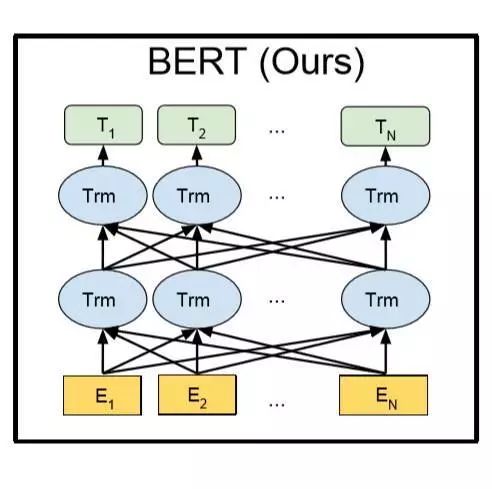
[5] Devlin, Jacob , et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." (2018).
6 能写故事的GPT2.0
2019年2月openAI用更大的模型,规模更大质量更好的数据推出了GPT2.0,其语言生成能力令人惊叹。相比于BERT,得益于以语言模型为训练任务,GPT2.0的生成能力要更强,在文本生成领域获得很大的反响。
值得关注的一点是,GPT的创造者们认为,Finetune的过程其实是不必要的,不同的任务用不同的处理方式即可。也就是说,自然语言处理中,几乎所有的事情都放在无监督中的预训练就可以了。是不是听着就觉得带劲?当然,这个还需要时间来考证,至少BERT还不这么认为。

[6] Alec Radford, Jeffrey Wu, Rewon Child, David Luan, Dario Amodei , Ilya Sutskever.(2019) Language Models are Unsupervised Multitask Learners.
7 GPT与BERT的结合体XLnet
在2019年6月,XLNet: Generalized Autoregressive Pretraining for Language Understanding诞生,其基于BERT和GPT等两类预训练模型来进行改进,分别吸取了两类模型的长处,获得的很好的效果。
在XLnet中,提出了AutoRegressive (AR) 语言模型和AutoEncoding (AE)语言模型的说法,分别对应GPT和BERT,分析他们的优劣势,然后做出结合,模型的效果超过BERT,暂时占据自然语言处理头牌。

[7] Zhilin Yang, Zihang Dai, Yiming Yang , Jaime Carbonell, Ruslan Salakhutdinov, Quoc V. Le(2019). XLNet: Generalized Autoregressive Pretraining for Language Understanding.
8 如何获取文章与交流
找到有三AI github开源项目即可获取。
https://github.com/longpeng2008/yousan.ai
文章细节众多,阅读交流都在有三AI-NLP知识星球中进行,感兴趣可以加入,扫描下图中的二维码即可。

总结
这一期我们从头到尾,看了现在最火爆的预训练语言模型的发展过程,细细看过来,你能够品味到NLP这些年发展的脉络,非常有益处。后面我们的每周论文分享会从不同的自然语言处理任务来展开。
转载文章请后台联系
侵权必究

往期NLP精选
【NLP】自然语言处理专栏上线,带你一步一步走进“人工智能技术皇冠上的明珠”。
【NLP】用于语音识别、分词的隐马尔科夫模型HMM
【NLP】用于序列标注问题的条件随机场(Conditional Random Field, CRF)
【NLP】经典分类模型朴素贝叶斯解读
【NLP】 NLP专栏栏主自述,说不出口的话就交给AI说吧
【NLP】 深度学习NLP开篇-循环神经网络(RNN)
【NLP】 NLP中应用最广泛的特征抽取模型-LSTM
【NLP】 聊聊NLP中的attention机制
【NLP】 理解NLP中网红特征抽取器Tranformer
【技术综述】深度学习在自然语言处理中的应用发展