学习目标
1. 文本聚类概念 Explain the concept of text clustering and why it is useful.
2. 概念生成模型 Explain how we can design a probabilistic generative model for performing text clustering, and explain the similarity and difference between such a model and a topic model such as PLSA.
3. 阶层式汇聚分群法 Explain how Hierarchical Agglomerative Clustering and k-Means clustering work.
4. 评价 Explain how to evaluate text clustering
5. 文本分类概念 Explain the concept of text categorization and why it is useful.
6. Naïve Bayes 分类 Explain how Naïve Bayes classifier works.

一、聚类
1.1 聚类概念
聚类的目的:发现数据的内在结构,将相似的文本对象聚集起来
聚焦:如何定义相似性——取决于看问题的角度(聚类偏差)。即定义聚类问题时,要指定如何界定相似性,这对于聚类的评价也是十分重要的
聚类的应用:
对术语进行聚类——定义概念、主题
对文本片段——深入探究
对大型文本——找出相似,消除冗余 , 给文本增添额外特性,将文本数据结构化,建立结构的层次关系(微博)例如:搜索结构聚类与对邮件进行聚类
二、概念生成模型( generating probabilistic model)
2.1 文本聚类方法:
概念生成模型,基于相似性的方法
2.2 主题模型之模型 生成 回忆:
原始:
输入:文本C,话题K,词汇V,
输出:theta i表示一组主题的分布,pi ij表示每个文档涵盖每个主题的概率。
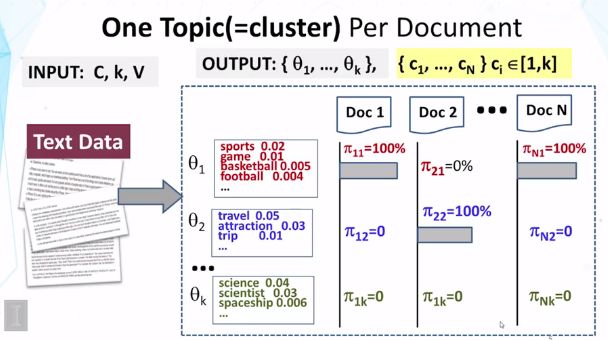
现在的文本分类概念生成模型:若假设一个主题是一个集群,则只允许一个文档涵盖一个主题,不再是一个文档可涵盖多个主题的情况。
Ci是文件i的分类,进行了集群分配决策
重点:强制每个文件是从一个主题生成的,而不是在主题模型中的k个主题
问题:主题模型中,生成的每个单词独立,但是要首先要选择哪种分配(p(θi)),再使用分布进行抽样 。
结果:希望“text”从第二个分布θ2产生,但更可能是从θ1中生成的。因为“text”在θ1中出现概率更高。0.5*0.04>0.5*0.000006
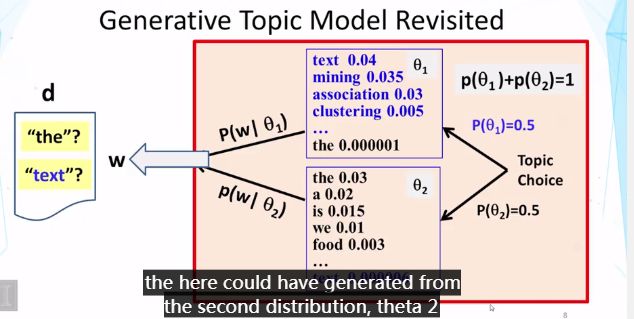
即单词可能来自多个分布。而文本聚类希望所有单词来自于一个主题,所以此种方法不适。
2.3 概念生成模型的区别与改进:
文本分类:定了一个词属于的θ,那么剩下的词就都是在这个θ中生成。词的分布就是整体文章的词分布
主题模型:定了整个分布的p,对于每个词,都要确定其是哪个θ,乱七八糟生成词的分布情况并不代表生成文章的情况
需注意:文本分类亦是混合模型,需要确定是哪个θ,虽然只有一次
2.4 似然函数:
假设每个单词都是独立生成的,整个文档的概率是文件中每个单词概率的乘积

所以,似然函数到底代表什么?——生成一篇文档的概率——所以既可能选择1,也可能选择2,所有概率需要相加。即:

似然函数与先验(p(θi))结合来得到d。
2.5 EM算法:(需回顾)
M:推断用哪个θ来生成文档,计算给定文档的后验概率——隐形变量Zd(1~k)




三、基于相似性的方法
3.1原理
指定相似度函数来度量两个文本对象之间的相似度,定义了聚类偏差。
目标:最大化组内相似性(同一个组中的对象是相似的),最小化组间相似性(不同组的对象 是不相似的)
3.2 方法:
逐步构建集群的层次结构:(HAC)
1.自下而上:凝聚
2.自上而下:分裂
平坦聚类:从最初的试探性聚类开始然后迭代地改进它,例如k-Means
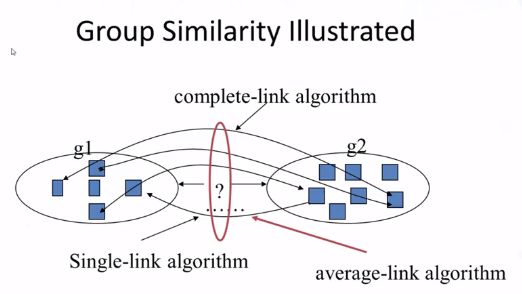
区别:计算组相似度的方式
HAC方法:
单链:最近的一对的相似度。可预测一些松散的群。将两个组进行组合。对异常值敏感
复杂链:最远的。可预测群体的紧张性。对异常值敏感。
平均链:平均值。由整个群体决定,对异常值不敏感
K—Means方法:
随机选择k,尝试聚类结果。选定的向量作为k个簇的质心。接着计算向量与每个质心的距离,将所有数据根据暂定质心分成k个类。基于此重新调整计算质心,直到它收敛(最小化群内平方和)。

四、聚类评估
4.1聚类基础
知道聚类偏差(bias),
4.2 评估方法
直接评估(与人评估结果(黄金评估)的区别):
从多重视点得到的,表征质量,

间接评估:在应用中有多有用,系统基准线

文本聚类:无监督通用文本挖掘工具
五、文本分类(text categorization)
5.1应用实例:

二分类、多分类、层次分类(主题层次)、合并分类(根据任务间的相关性)

5.2 文本分类方法:
类别必须是明确的,能够用规则确定。
缺点:人工设置标签,需要给予规则,不能很好地扩展。不能处理规则的不确定性。
解决方法:给机器带标签的数据进行训练。 为计算机提供一些基本的功能:短语,语法结构
优点:有监督
两种分类器:
生成分类器(general setup):试图了解每个类别中的数据。模拟数据的联合分布标签x和y。使用贝叶斯规则来分配标签。只能间接地捕捉训练错误(损失函数),特征:(非)线性

判别分类器(discriminative):试图了解每个类别的特征。直接给出数据点的标签的条件概率,目标函数往往直接衡量训练集中分类的错误。包括逻辑回归,支持向量机和k最近邻

(需理解)
六、生成概率模型进行文本分类:
6.1生成概率模型
与文本聚类区别:文本聚类不知道什么是预定义的类别,什么是集群(聚类目标) 而分类给出了类别。
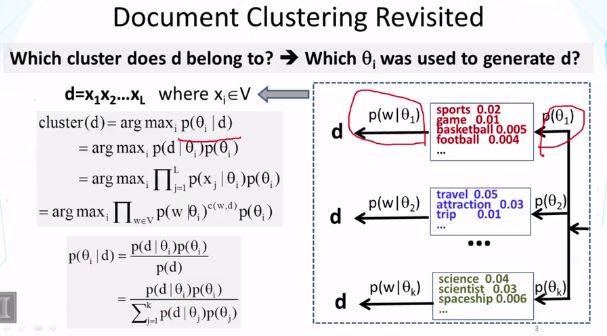
p(θi)是先验概率,要选择最大化的话题,p(θi|d)是后验概率。

如何确保θi恰好代表我们的分类i


平滑化:

当数据集过小的话,在利用极大似然估计求概率时会出现概率为0的情况,但这是不准确的,为了避免这种情况我们应该作平滑化处理,即分子分母都加上平滑因子。
二分类得分:

普遍化:

实际上,这种一般形式非常接近于一个称为logistic回归的分类器。这式子里的f是指文件,beta是指权重,即表示一个文件更属于哪一个类别的偏置。