NameNode生成DataNode的网络拓扑图的源码分析---NetworkTopology
NetworkTopology将整个集群中的DN存储成了一个树状网络拓扑图, 表示一个具有树状网络拓扑结构的计算机集群, 一个集群可能由多个数据中心Data Center组成, 在这些数据中心分布着为计算需求而设置的很多计算机的机架Rack. InnerNode内部类, 表示数据中心/机架的转换器/或路由
- /** The class represents a cluster of computer with a tree hierarchical network topology.
- * For example, a cluster may be consists of many data centers filled with racks of computers. In a network topology,
- * leaves represent data nodes (computers) and inner nodes represent switches/routers that manage traffic in/out of data centers or racks. */
- public class NetworkTopology {
- public final static String DEFAULT_RACK = "/default-rack"; // 默认机架名称
- public final static int DEFAULT_HOST_LEVEL = 2; // 主机层次
- InnerNode clusterMap = new InnerNode(InnerNode.ROOT); // the root 定义网络拓扑的根结点
- private int depthOfAllLeaves = -1; // Depth of all leaf nodes
- private int numOfRacks = 0; // rack counter 机架数量
- }
InnerNode
每一个`Node`在网络拓扑中应该有一个名称及其位置(使用类似文件路径的方式来定义), 例如一个Datanode名称为hostname:port,
并且该Datanode在数据中心dog里的orange机架上, 则这个Datanode在网络拓扑中的位置(网络地址)为/dog/orange.
- /** The interface defines a node in a network topology. Node接口表示网络拓扑中的结点的抽象, 一个Node可能是一个Datanode,
- * A node may be a leave representing a data node or an inner node representing a datacenter or rack. 也可能是一个表示数据中心或机架的内部结点.
- * Each data has a name and its location in the network is decided by a string with syntax similar to a file name.
- * For example, a data node's name is hostname:port# and if it's located at rack "orange" in datacenter "dog",
- * the string representation of its network location is /dog/orange. the path of this node is /dog/orange/hostname */
- public interface Node {
- public String getNetworkLocation(); /** Return the string representation of this node's network location 返回表示该结点的网络地址的字符串*/
- public void setNetworkLocation(String location); /** Set the node's network location */
- public String getName(); /** Return this node's name 获取该结点的名称*/
- public Node getParent(); /** Return this node's parent 获取该结点的父结点*/
- public void setParent(Node parent); /** Set this node's parent */
- public int getLevel(); /** Return this node's level in the tree. E.g. the root of a tree returns 0 and its children return 1 */
- public void setLevel(int i); /** Set this node's level in the tree.*/
- }
`NodeBase`实现了Node接口, 是一个最基本的结点的实现. 该类定义的属性都是与一个结点的基本属性信息相关的
假设DN节点的路径path=/a/b/c, 则节点名称name=c, 节点路径location=/a/b. 节点的`path`不需要定义, 由`location/name`组成
- /** A base class that implements interface Node 实现了Node接口, 是一个最基本的结点的实现*/
- public class NodeBase implements Node {
- public final static char PATH_SEPARATOR = '/'; // 路径分隔符
- public final static String PATH_SEPARATOR_STR = "/";
- public final static String ROOT = ""; // string representation of root 网络拓扑的根结点
- protected String name; // host:port#
- protected String location; // string representation of this node's location 该结点的网络位置
- protected int level; // which level of the tree the node resides 该结点在网络拓扑中的层次
- protected Node parent; // its parent 该结点的父结点
- public String getName() { return name; } /** Return this node's name */
- public String getNetworkLocation(){return location;} /** Return this node's network location */
- public static String getPath(Node node) { /** Return this node's path */
- return node.getNetworkLocation()+PATH_SEPARATOR_STR+node.getName();
- }
- public String toString() { return getPath(this); } /** Return this node's string representation */
- }
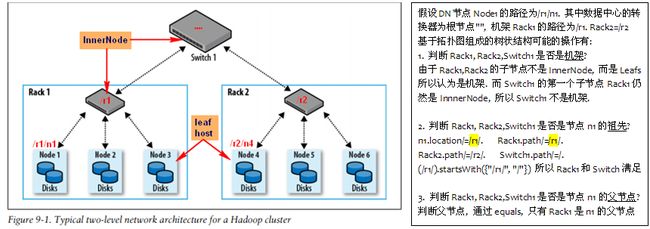
`InnerNode`表示数据中心DC的转换器Switch或机架Rack的路由器Router. 不同于网络拓扑中的叶结点:主机, 它具有非空的孩子结点
下图表示同一数据块中心的网络拓扑图. 其中Switch和Router都表示InnerNode. 叶子节点连接到不同Rack的Router上, 不同Rack连接到Switch上.
判断InnerNode是否是Rack(router)的依据是InnerNode的第一个字节点不为InnerNode. 否则如果是Switch, 其子节点是router,仍然是InnerNode.
树状结构要考虑的是祖先-父-子关系. 叶子节点的父节点只可能有一个, 即其连接到的Rack的Router. 但是祖先可以有多个(祖先的祖先...), 包括父节点.
- /* Inner Node represent a switch/router of a data center or rack. Different from a leave node, it has non-null children. */
- private class InnerNode extends NodeBase {
- private ArrayList
children= new ArrayList(); // 子节点. InnerNode可以是router或switch. 对应子节点分别是叶子节点和机架. - private int numOfLeaves; // 叶子节点的数量: 仅表示树状拓扑图中所有Datanodes的数量
- boolean isRack() { // 判断当前节点是否是一个机架. 因为InnerNode表示数据中心的转换器, 或者机架的路由器.
- if (children.isEmpty()) return true; // 没有子节点, 是机架. 机架下没有挂载任何数据节点, 空的机架.
- Node firstChild = children.get(0); // 第一个子节点
- if (firstChild instanceof InnerNode) return false; // 如果第一个子节点还是InnerNode, 说明这不是机架, 是数据中心?
- return true; // 第一个子节点不是InnerNode, 说明这是一个机架.
- }
- boolean isAncestor(Node n) { // 判断当前节点是否是节点Node n的祖先节点
- return getPath(this).equals(NodeBase.PATH_SEPARATOR_STR) ||
- (n.getNetworkLocation()+NodeBase.PATH_SEPARATOR_STR).startsWith(getPath(this)+NodeBase.PATH_SEPARATOR_STR);
- }
- boolean isParent(Node n) { // 判断当前节点是否是节点Node n的父节点
- return n.getNetworkLocation().equals(getPath(this));
- }
- }
InnerNode.add(Node n)
在上面isAncestor(), isParent()方法的基础上, 可以将节点添加到树状网络拓扑图中或从拓扑图中删除. isRack()会用于getLeaf()获取叶子节点.
按照NodeBase的实现, `子节点的location=父节点的path. 比如节点/r1/n1的location=/r1, n1的父节点r1的path=/r1.`
- private String getNextAncestorName(Node n) { /* Return a child name of this node who is an ancestor of node n */
- if (!isAncestor(n)) throw new IllegalArgumentException(this + "is not an ancestor of " + n);// this current node must be the ancestor of Node n
- String name = n.getNetworkLocation().substring(getPath(this).length()); // 当前节点this是参数Node n的祖先!
- if (name.charAt(0) == PATH_SEPARATOR) name = name.substring(1); // 去掉开头的路径分隔符/. 比如/a/b/c -> a/b/c
- int index=name.indexOf(PATH_SEPARATOR);
- if (index !=-1) name = name.substring(0, index); // 从路径开头到第一个路径分隔符/之间的节点名称 -> a
- return name;
- /** Add node n to the subtree of this node 添加节点n到当前节点的子树中
- * @param n node to be added 如果当前节点不是n的父节点, 需要递归直到找到n的父节点, 往n的父节点的子树中添加节点n
- * @return true if the node is added; false otherwise */
- boolean add(Node n) {
- if (!isAncestor(n))throw new IllegalArgumentException("this current node must be the ancestor of Node n");
- if (isParent(n)) {
- n.setParent(this); // ③ this node is the parent of n; add n directly
- n.setLevel(this.level+1);
- for(int i=0; i
- if (children.get(i).getName().equals(n.getName())) {
- children.set(i, n);
- return false; // if to be added node n is already in subtree, don’t add it
- }
- }
- children.add(n); // ④ add node n to parent’s children list
- numOfLeaves++;
- return true;
- } else {
- String parentName = getNextAncestorName(n); // ① find the next ancestor node
- InnerNode parentNode = null;
- for(int i=0; i
- if (children.get(i).getName().equals(parentName)) {
- parentNode = (InnerNode)children.get(i);
- break;
- }
- }
- if (parentNode == null) { // create a new InnerNode
- parentNode = new InnerNode(parentName, getPath(this), this, this.getLevel()+1);
- children.add(parentNode); // add parentNode to this current caller node
- }
- if (parentNode.add(n)) { // ② add n to the subtree of the next ancestor node 递归调用!
- numOfLeaves++; // ⑤ 递归调用后面的语句在递归调用返回后才执行.
- return true;
- } else {
- return false;
- }
- }
- }

InnerNode的剩余三个方法remove, getLoc, getLeaf都通过这种递归调用的方式, 来寻找到最终要操作的目标节点.
测试用例1 - TestNetworkTopology
- public class TestNetworkTopology extends TestCase {
- private final static NetworkTopology cluster = new NetworkTopology();
- private final static DatanodeDescriptor dataNodes[] = new DatanodeDescriptor[] {
- new DatanodeDescriptor(new DatanodeID("h1:5020"), "/d1/r1"),
- new DatanodeDescriptor(new DatanodeID("h2:5020"), "/d1/r1"),
- new DatanodeDescriptor(new DatanodeID("h3:5020"), "/d1/r2"),
- new DatanodeDescriptor(new DatanodeID("h4:5020"), "/d1/r2"),
- new DatanodeDescriptor(new DatanodeID("h5:5020"), "/d1/r2"),
- new DatanodeDescriptor(new DatanodeID("h6:5020"), "/d2/r3"),
- new DatanodeDescriptor(new DatanodeID("h7:5020"), "/d2/r3")
- };
- static {
- for(int i=0; i
- cluster.add(dataNodes[i]);
- System.out.println("叶子节点数量:" + cluster.getNumOfLeaves());
- System.out.println("[ADD]网络拓扑图:" + cluster);
- }
- public void testNumOfChildren() throws Exception {
- assertEquals(cluster.getNumOfLeaves(), dataNodes.length);
- }
- }
调试add
在调试之前, 我们对add()进行简化, 分成五个步骤. 这几个步骤是调试过程的重点. 在递归调用过程中, 注意this, parentNode,children和numOfLeaves
- boolean add(Node n) {
- if (isParent(n)) { // ③ 调用者是节点的父节点(机架)
- children.add(n); // ④ add node n to parent’s children list
- numOfLeaves++;
- return true;
- } else { // ① 调用者是节点n的祖先
- String parentName = getNextAncestorName(n); // find the next ancestor node
- InnerNode parentNode = null;
- // ...根据parentName到children中找parentNode, 如果存在跳出循环, 下面直接使用parentNode
- if (parentNode == null) { // create a new InnerNode
- parentNode = new InnerNode(parentName, getPath(this), this, this.getLevel()+1);
- children.add(parentNode); // add parentNode to this current caller node
- }
- if (parentNode.add(n)) { // ② add n to the subtree of the next ancestor node 递归调用!
- numOfLeaves++; // ⑤ 递归调用后面的语句在递归调用返回后才执行.
- return true;
- }
- }
- }
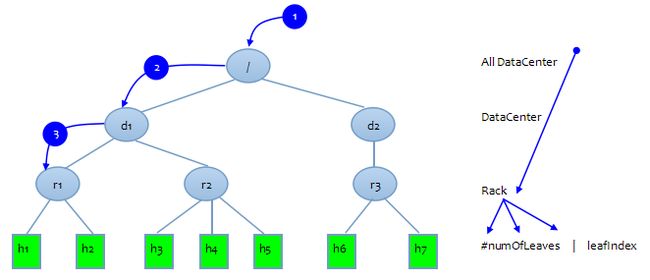
上面的测试用例添加了7个DN节点到树状网络拓扑图中. 我们以添加第一个节点h1为例. 在add(Node n)的if(isParent())上添加断点开始调试.
在上面的测试用例中第一个DN节点是new DatanodeDescriptor(new DatanodeID("h1:5020"), "/d1/r1"). cluster会使用NetworkTopology的成员变量InnerNode clusterMap根节点开始调用InnerNode.add(Node n). 其中Node n就是第一个DN节点. 节点n的name=h1:5020, location=/d1/r1




**陷阱与解答**
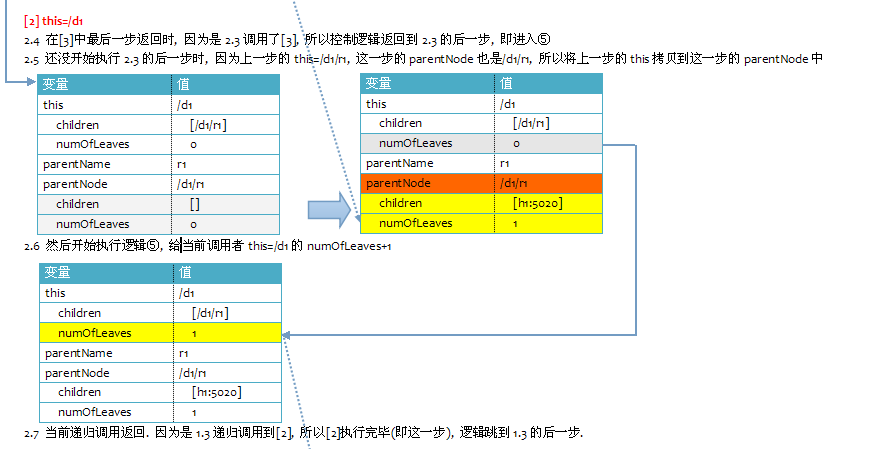
InnerNode.add()的else部分的处理会递归调用. 在递归调用后面变量numOfLeaves++.
以上面添加/d1/r1/n1为例, 总共发生了两次递归调用. 最后一次逻辑是在if中处理. 在if中也将变量numOfLeaves++.
那么你可能就会认为numOfLeaves总共加了3次. 值应该为3才是. 但是实际上在添加/d1/r1/n1后, numOfLeaves=1.
这是因为对于每次的递归调用, 当前调用的对象即this引用的节点都是不同的. 对于不同的InnerNode对象,
因为numOfLeaves是对象的成员变量, 即每个InnerNode对象都有自己的numOfLeaves值.
(如果把numOfLeaves定义在和InnerNode同等级, 即在NetworkTopology中. 那么变量就是所有InnerNode对象共享的.)
add()的调用者最初是root根节点. 那么调用add()完成后, 得到的返回值numOfLeaves也应该是来自于root节点的.
而不是其他InnerNode的numOfLeaves. 尽管其他InnerNode的numOfLeaves的值也是1(/d1和/d1/r1都是InnerNode).
如果将else部分递归调用后面的numOfLeaves++注释掉. 那么root.add(n)最后得到的numOfLeaves=0.
(尽管此时/d1/r1的numOfLeaves的值仍然=1, 但是递归调用返回后没有保证/d1/r1的父节点/d1和/d1的父节点root的numOfLeaves也+1.)
**getNextAncestorName**
1. name = n.location.substring(getPath(this).lenth)
2. 如果name以/开头, 去掉开头的/: name.substring(1)
3. 如果name以/分隔, 则取开头到第一个/之间的内容

**测试用例的打印信息**
上面测试用例TestNetworkTopology的打印信息如下.
- 叶子节点数量:7
- [ADD]网络拓扑图:Number of racks: 3
- Expected number of leaves:7
- 0: /d1/r1/h1:5020
- 1: /d1/r1/h2:5020
- 2: /d1/r2/h3:5020
- 3: /d1/r2/h4:5020
- 4: /d1/r2/h5:5020
- 5: /d2/r3/h6:5020
- 6: /d2/r3/h7:5020
如果在NetworkTopology.InnerNode.add的两处numOfLeaves++后面加上打印语句打印numOfLeaves的值: 则每个节点的打印信息是一个before, 两个after
其中Before是节点h1:5020的父节点/d1/r1进入if的打印信息. After是在递归调用结束后, /d1/r1的parent=/d1和/d1的parent=/打印的信息(两次递归调用).
下面是测试用例的树状网络拓扑图:
InnerNode.remove(Node n)
- /** Remove node n from the subtree of this node */
- boolean remove(Node n) {
- String parent = n.getNetworkLocation(); // node's location equals to parent's path
- String currentPath = getPath(this); // current caller's path must be ancestor of node n
- if (!isAncestor(n)) throw new IllegalArgumentException(n.getName()+", which is located at "+parent+", is not a descendent of "+currentPath);
- if (isParent(n)) { // ① this node is the parent of n; remove n directly
- for(int i=0; i
- if (children.get(i).getName().equals(n.getName())) { // 添加时不应存在, 删除时应该存在
- children.remove(i); // 从父节点的children中移除要删除的节点n
- numOfLeaves--;
- n.setParent(null); // 上面仅移除父节点和要删除的节点的关系, 现在设置n的parent=null
- return true; // 一旦节点的父节点引用为null, 该节点就不在树状拓扑图中.
- }
- }
- return false;
- } else { // ② find the next ancestor node: the parent node
- String parentName = getNextAncestorName(n);
- InnerNode parentNode = null; // 获取当前调用者的子节点, 让子节点递归调用删除
- int i;
- for(i=0; i
- if (children.get(i).getName().equals(parentName)) {
- parentNode = (InnerNode)children.get(i);
- break;
- }
- }
- if (parentNode==null) return false; // 如果子节点不存在, 返回false. 无法递归下去, 当然返回false
- boolean isRemoved = parentNode.remove(n); // remove n from the parent node 递归调用!
- if (isRemoved) { // 递归后的语句在①调用返回时, 依次逆序执行
- if (parentNode.getNumOfChildren() == 0) { // ③ if the parent node has no children, remove the parent node too
- children.remove(i);
- }
- numOfLeaves--;
- }
- return isRemoved;
- }
- } // end of remove

假设根节点root调用remove(/d1/r1/n1)要删除节点n1. 由于root不是n1的父节点, 但却是n1的祖先, 所以需要递归直到找到n1的父节点来删除n1.
[1]. root.remove(/d1/r1/n1)
1.1 root是n1的祖先, 通过getNextAncestorName得到下一个祖先节点为d1
1.2 parentNode=/d1, root.children包括d1
然后使用d1递归调用自身, 即/d1.remove(/d1/r1/n1)
1.3 递归调用自身后面的语句需要等到/d1.remove(/d1/r1/n1)调用返回后才会被执行->[5]. 调用时是顺序调用, 返回时是逆序返回.
[2]. /d1.remove(/d1/r1/n1)
2.1 d1是n1的祖先, 通过getNextAncestorName得到下一个祖先节点parentName=r1 : /d1/r1.substring(/d1) -...->r1
2.2 parentNode=/d1/r1, d1.children包括r1.
然后使用r1递归调用自身, 即/d1/r1.remove(/d1/r1/n1)
2.3 递归调用后的语句也需等待/d1/r1.remove(/d1/r1/n1)调用返回后才会执行->[4]
[3]. /d1/r1.remove(/d1/r1/n1)
3.1 r1是n1的父节点, 不走getNextAncestorName了, 即进入if(isParent(n))逻辑
因为要将n1从r1中删除, 即将n1从r1的children子节点列表中删除,
3.2 同时设置n1.parent=null, 一个叶子节点一旦父节点的引用为null, 那么它就不会在树状网络拓扑图NetworkTopology中了.
3.3 最后开始返回, 上面等待下一个递归调用返回后面的语句就可以开始执行了.
[4]. 控制逻辑回到[2]的最后一步2.3
4.1 parentNode=/d1/r1, 判断r1.children.length如果为0则将r1也删除掉
因为在[3]中已经将n1从r1的children中删除, 假设r1现在都没有其他节点了, 即r1.children.length=0
4.2 将r1从d1.children中移除. 现在r1和[3]中被删除的节点n1一样, 都不会出现在NetworkTopology中了
[5]. 控制逻辑回到[1]的最后一步1.3
5.1 parentNode=/d1, 判断d1.children.length如果也为0, 也要将d1删除掉
因为在上一步[4]中删除了r1, 假设d1现在也都没有其他节点了, 那么d1.children.length=0
5.2 将d1从root.children中移除. d1也会和r1, n1一样, 都不会出现在NetworkTopology中.
[6]. END. 如果上图中r3不存在, 则也会删除root节点, 整个NetworkTopology也为空了.
测试用例2 - TestNetworkTopology
- public void testRemove() throws Exception {
- for(int i=0; i
- cluster.remove(dataNodes[i]); // 移除所有DN节点
- }
- for(int i=0; i
- assertFalse(cluster.contains(dataNodes[i])); // 现在拓扑图中不包括任何DN节点了
- }
- assertEquals(0, cluster.getNumOfLeaves()); // 叶子节点的个数=0
- System.out.println("[remove]网络拓扑图:" + cluster);
- for(int i=0; i
- cluster.add(dataNodes[i]); // 重新添加所有DN节点
- }
- }
打印信息:
- [remove]网络拓扑图:Number of racks: 0
- Expected number of leaves:0
InnerNode.getLoc()
- /** Given a node's string representation, return a reference to the node 参数loc说明了不会传递dn节点名称进来 */
- private Node getLoc(String loc) {
- if (loc == null || loc.length() == 0) return this;
- String[] path = loc.split(PATH_SEPARATOR_STR, 2); // 如果loc=r1/r2, path=[r1, r2]; 如果loc=r1/r2/r3, path=[r1, r2/r3]
- Node childnode = null;
- for(int i=0; i
- if (children.get(i).getName().equals(path[0])) {
- childnode = children.get(i);
- }
- }
- if (childnode == null) return null; // non-existing node
- if (path.length == 1) return childnode;
- if (childnode instanceof InnerNode) {
- return ((InnerNode)childnode).getLoc(path[1]); // 递归调用
- } else {
- return null;
- }
- }
1. root.getLoc(r1/r2)
将loc以路径分隔符/分成两部分, 第二部分可能还会包括/分隔的路径, 因此在后面会使用第二部分继续递归调用.
path[0]应该是当前调用者的一个子节点. r1/r2分隔后的path=[r1, r2], path[0]=r1正是调用者root的子节点.
childnode = r1, 然后递归调用r1.getLoc(path[1]) = r1.getLoc(r2)
2. r1.getLoc(r2)
对r2进行split, 此时r2只有一个元素. path = [r2]. path.length=1
同样path[0]=r2应该也是当前调用者r1的一个子节点. 即r2是r1的childnode
childnode=r2, 因为path.length=1, 直接return childnode=return r2
3. 所以root.getLoc(r1/r2)通过递归调用, 最终返回的是r2节点.
InnerNode.getLeaf()
- InnerNode clusterMap = new InnerNode(InnerNode.ROOT); // the root 定义网络拓扑的根结点
- public String toString() { /** convert a network tree to a string */
- StringBuffer tree = new StringBuffer();
- tree.append("Number of racks: " + numOfRacks + "\n"); // print the number of racks
- int numOfLeaves = getNumOfLeaves(); // print the number of leaves
- tree.append("Expected number of leaves:" + numOfLeaves + "\n");
- for(int i=0; i
- tree.append(NodeBase.getPath(clusterMap.getLeaf(i, null)));
- tree.append("\n");
- }
- return tree.toString();
- }
- public int getNumOfLeaves() { /** Return the total number of nodes */
- return clusterMap.getNumOfLeaves();
- }
NetworkTopology通过网络拓扑图的根节点来索引整个树状结构. 只需定义InnerNode(ROOT), 不需要定义List
因为树状结构从根节点开始到达叶子节点, 都是有父子节点的关联关系的. 这些关系都在内部类InnerNode中实现.
clusterMap.getNumOfLeavers()就是获得InnerNode的成员变量numOfLeavers的值. 该变量表示拓扑图中叶子节点(Datanodes)的数量.
在InnerNode的add()和remove()中添加一个DN节点就+1, 移除一个DN节点就-1. 以此来记录树状网络拓扑图的叶子节点的数量.
- private class InnerNode extends NodeBase {
- private ArrayList
children= new ArrayList(); - private int numOfLeaves;
- int getNumOfLeaves() {
- return numOfLeaves;
- }
- }
getLeaf的leafIndex为叶子节点的索引, 从0开始到numOfLeaves. excludedNode表示要排除的节点. 在该方法前需进行检查:
1. 判断excludeNode是否是叶子节点: 为空或者不是InnerNode的实例. 因为InnerNode只表示机架的路由器或者数据中心的转换器. 不表示主机叶子节点.
2. 如果excludeNode不为null, 且是InnerNode的实例, 说明是router/switch, 不是叶子节点. 那么router/switch下的所有叶子节点都会被排除.
如果excludedNode是叶子节点(包括excludedNode=null), 则只排除对应的一个DN节点, 即numOfExcludedLeaves=1.
- /** get leafIndex leaf of this subtree if it is not in the excludedNode*/
- ivate Node getLeaf(int leafIndex, Node excludedNode) {
- System.out.println("leafIndex:" + (leafIndex+1));
- int count=0;
- boolean isLeaf = excludedNode == null || !(excludedNode instanceof InnerNode); // 1. check if the excluded node a leaf
- int numOfExcludedLeaves = isLeaf ? 1 : ((InnerNode)excludedNode).getNumOfLeaves(); // 2. calculate the total number of excluded leaf nodes
- if (isRack()) { // children are leaves 机架下是主机叶子节点.
- if (isLeaf) { // excluded node is a leaf node 被排除的节点是叶子节点
- int excludedIndex = children.indexOf(excludedNode);
- if (excludedIndex != -1 && leafIndex >= 0) {
- leafIndex = leafIndex>=excludedIndex ? leafIndex+1 : leafIndex; // excluded node is one of the children so adjust the leaf index
- }
- }
- if (leafIndex<0 || leafIndex>=this.getNumOfChildren()) { return null; } // range check
- System.out.println(this + ":" + children + "-" + children.size() + "[" + (leafIndex+1) + "]");
- return children.get(leafIndex);
- } else { // 调用者不是机架, 要继续递归到机架上. 因为获取叶子节点应该是从机架上才能获取. 不是机架不能获取.
- for(int i=0; i
- InnerNode child = (InnerNode)children.get(i); // 当前调用者的子节点
- if (excludedNode == null || excludedNode != child) { // not the excludedNode
- int numOfLeaves = child.getNumOfLeaves(); // 子节点的叶子节点的个数
- if (excludedNode != null && child.isAncestor(excludedNode)) { // excludedNode可能是叶子节点, 或者是一个InnerNode. 如果为null, 不减
- numOfLeaves -= numOfExcludedLeaves; // 假设是叶子节点, child是其祖先, numOfExcludedLeaves=1, numOfLeaves-1
- }
- if (count+numOfLeaves > leafIndex) { // the leaf is in the child subtree
- return child.getLeaf(leafIndex-count, excludedNode);
- } else {
- count = count+numOfLeaves; // go to the next child
- }
- } else { // it is the excluededNode
- excludedNode = null; // skip it and set the excludedNode to be null
- }
- }
- return null;
- }
- }
在getLeaf中添加了2个打印语句, 运行测试用例. cluster变量会调用NetworkTopology.toString(). toString()中会循环所有叶子索引调用getLeaf.
if中的打印信息为this: children-children.size[leafIndex]. 其中this为当前调用者, children为当前调用者的子节点. 只有当前调用者是机架时才会执行if.
toString()中numOfLeaves的循环遍历i从0开始. 为了结合网络拓扑图的理解(leaf从1开始), 在打印语句中将leafIndex+1(leafIndex参数即为传入的i遍历).
前面我们已经解释了numOfLeaves是属于每个InnerNode自己的叶子节点的数量. 不是共享的变量. 同样InnerNode的children变量也是对象私有的.
因为InnerNode表示数据中心的转换器或者机架的路由器. 即InnerNode最低只到机架这一层. 因此对于机架而言, children存放了机架上的所有DN节点.
在调用getLeaf()如果调用者不是机架, 就会继续递归调用. 比如对于h1节点, 根节点/和/d1都不是机架, 进入的是else部分. 所以会继续递归调用.
如果是机架, 比如/d1/r1, 就进入if部分. 从当前(机架)的children中获取出对一个leafIndex的叶子节点即DN节点.
(在前面的add, remove都是通过判断当前调用者是否是节点Node n的parent来进入if语句. 节点n的parent其实就是机架.)
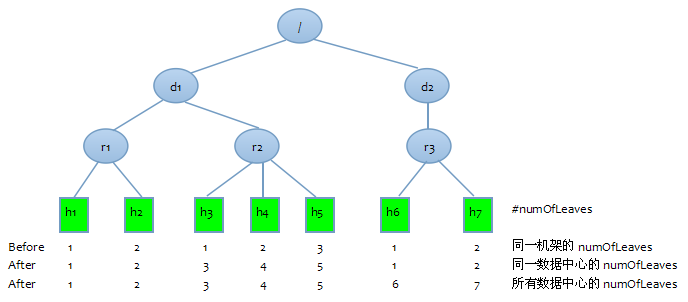
从上面打印的第一部分日志可以看出: /d1/r1机架有2个叶子节点, /d1/r2有3个叶子节点, /d1/r3有2个叶子节点. leafIndex从0开始(打印时leafIndex+1了)
比较add操作打印的numOfLeaves和此处getLeaf打印的leafIndex. 发现数据分别为:
1. 同一机架的节点数量/索引.
2. 同一数据中心的节点数量/索引.
3. 所有数据中心的节点数量/索引.
InnerNode小结
至此已经分析完了内部类InnerNode的所有方法. NetworkTopology的方法都是基于InnerNode的方法.
InnerNode表示网络拓扑图中的(数据中心上的)转换器或(机架上的)路由器. 由于数据节点即叶子节点是连接到机架的路由器上, 不同机架间连接到数据中心的转换器上. 因此用InnerNode表示转换器时, 其children表示的子节点为机架. InnerNode用来表示机架时, children表示的子节点就是叶子节点.
InnerNode的几个方法:add(), remove(), getLoc(), getLeaf()都用到了递归调用. 这是因为如果是从根节点开始调用这些方法. 由于根节点不是叶子节点的parent. 需要经过层层递归, 直到找到叶子的parent: 一般就是机架. 对于两层(level=1)的网络拓扑图比如/r1/h1, 递归调用只需一次就能找到: 根节点调用时通过getNextAncestorName得到r1, 而r1正是h1的parent. 两层的拓扑图一般只有一个数据中心. 一个数据中心下有多个机架.
三层(level=3)的网络拓扑图比如/d1/r1/h1. 即有多个数据中心. 从根节点开始到叶子就需要两次递归. 同上根节点通过getNextAncestorName得到d1, 由于d1不是h1的parent, 因此有了第一次递归调用. 使用d1发起第一次递归调用. d1通过getNextAncestorName得到r1, 就和上面的一样了发起第二次递归调用. 当然如果要算上调用者的调用. 即根节点的第一次调用. 则总共发生了三次方法的调用. 这也正是上面我们看到打印的信息都是一个节点三次信息.
一旦当前的调用者是叶子节点的parent(add方法)或者是机架(getLeaf方法)时, 就不会再进入递归调用模式了. 方法中的两部分逻辑if表示当前调用者是机架, else逻辑表示当前调用者不是叶子的父节点, 而是其祖先. 对于三层的网络拓扑图, 根节点/和/d1都是叶子的祖先. 但只有机架/d1/r1才是叶子的parent.
对于递归调用中的变量numOfLeaves[add]和leafInex[getLeaf]的值在调试过程中要特别注意. 递归过程中的变量如果是局部变量, 即当前调用的对象自有的. 那么对于不同的调用对象, 他们的变量值不会相互影响. 即不是全局共享的. 由于InnerNode代表了/, d1或r1, 因此InnerNode的成员变量children分别表示各自的孩子节点. 但是变量numOfLeaves只表示网络拓扑图中的叶子节点的数量. 不包括机架和数据中心的数量.
在add使用的变量numOfLeaves和getLeaf中使用的变量leafIndex. 在发生递归调用时打印的信息按照同一机架->同一数据中心->整个拓扑图的级别上升.