【Redis数据结构 String类型】String类型生产中的应用 缓存、计数器、限速器的实现
想要看更加舒服的排版、更加准时的推送
关注公众号“不太灵光的程序员”
每日八点有干货推送
公众号“不太灵光的程序员” 同时发布《【Redis数据结构 String类型】String类型生产中的应用 缓存、计数器、限速器的实现》
本文依旧会对学习内容进行拆分,建议阅读时间基本保持10分钟内,想学习之前章节内容点击《你不了解的Redis》阅读所有章节内容。
Redis数据结构系列是对Redis常用的String、List、Set、Sorted Set、Hashe和Stream6种数据结构进行介绍,并使用redis-py进行实践操作。
Redis数据结构 String
String是在Redis应用最的数据结构了,使用key-values做缓存、计数器、限流器。
我们先简单了解下String的操作命令再来使用这些功能做些小实验。
String常用操作命令
SET 将键key设定为指定的字符串值
SET key value [EX seconds] [PX milliseconds] [NX|XX]
- ex - 设置过期时间,单位秒
- px - 设置过期时间,单位毫秒
当SET命令执行成功之后,之前设置的过期时间都将失效,以最新的过期时间为准
- nx - 如果设置为True,则只有name不存在时,当前set操作才执行
- xx - 如果设置为True,则只有name存在时,当前set操作才执行
nx和xx的功能看上去鸡肋,可能环境初始的时候能用的上,默认情况都为False
使用SET创建一个key时,如果key已经存在,操作会直接覆盖原来的值,不管之前的key保存的数据是什么类型,也就是说如果我们之前使用message.mq 创建了一个List类型来实现消息队列,再次 SET 时也操作了 message.mq 这个key后,结果会使你的系统陷入瘫痪。
我们来测试一下:
print(r.lpush("user:server:message.mq", "Hello World"))
print(r.lrange("user:server:message.mq", 0, 0))
print(r.type("user:server:message.mq"))
print(r.set("user:server:message.mq", "Hello World"))
print(r.get("user:server:message.mq"))
print(r.type("user:server:message.mq"))
print(r.lpush("user:server:message.mq", "Hello World"))
> 1
> ['Hello World']
> list
> True
> Hello World
> string
> WRONGTYPE Operation against a key holding the wrong kind of value
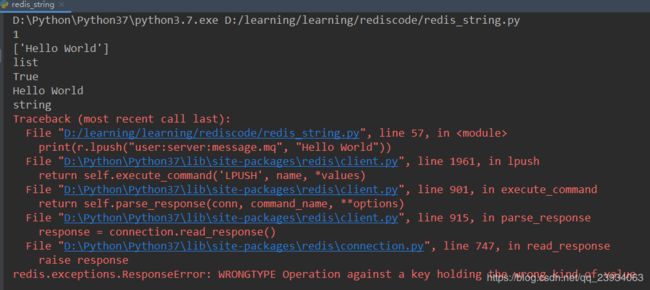
规范的命名key值是不就显的格外重要了,也可以将特定功能的key放在同一个命名空间中来避免错误。
GET 获取key对应的数值
- GET key
GET的操作就比较合理了,只可以获取时String类型的数值,当key不存在时返回None对象
在redis-py中会返回两种空值,需要特别注意下
print(r.lpush("user:server:message.mq", "Hello World"))
print(r.rpop("user:server:message.mq"))
print(r.type("user:server:message.mq"))
print(type(r.type("user:server:message.mq")))
print(r.type("user:server:message.mq") is None)
print(r.get("user:1000:index"))
print(r.get("user:1000:index") is None)
> 1
> Hello World
> none
> <class 'str'>
> False
> None
> True
注:我们对一个空的List类型进行操作,获取它的数值类型返回值是none字符串,并不是None对象,GET获取一个不存在的key时返回的是None对象。
MSET/MGET 同时对多个key进行读写操作
- MSET key value [key value …]
- MGET key [key …]
使用MSET/MGET一次操作多个键值对来减少客户端和服务端的通信次数,从而提升操作效率
print(r.mset({"user:1001:index": 1, "user:1002:index": "100"}))
print(r.mget("user:1001:index", "user:1002:index"))
print(r.mget(["user:1001:index", "user:1002:index"]))
> True
> ['1', '100']
> ['1', '100']
原子性操作命令
- INCR key 对数值执行原子的加1操作
- DECR key 对数值执行原子的减1操作
- INCRBY key increment 对数值执行原子的加increment操作,默认1
- DECRBY key increment 对数值执行原子的减increment操作,默认1
- INCRBYFLOAT key increment 对数值执行原子的加increment(浮点数)操作,默认1.0
- 没有写错 就是没有命令 DECRBYFLOAT
当values的数值是可以表示数字的字符串,就可以使用该原子性操作对数值进行增加或减少操作,如果操作的key不存在时会先将key的值设定为0再做加1操作。
原子操作是一个操作或者一系列不可分割的操作,在执行完毕之前不会被任何其它任务或事件中断,就是说即使有多个客户端对同一个key同时发出INCR命令,也决不会导致竞争的情况。
举个简单的例子,当客户端1和客户端2同时读取key的值是10,并且都INCR将值加1,最终key的值一定是12,Redis服务端收到两个INCR命令时是顺序执行两次 read-increment-set,read-increment-set 操作,后者递增前会重新读取数值,read-increment-set操作完成前,其他客户端不会在同一时间执行任何命令,这也和单线程不存在数据共享有关吧。
这里插一句Redis单线程为什么效率还高呢?
因为多线程的本质就是CPU模拟出来多个线程的情况,这种模拟出来的情况就有一个代价,就是上下文的切换,对于一个内存的系统来说,它没有上下文的切换就是效率最高的。
Redis用单个CPU绑定一块内存的数据,然后针对这块内存的数据进行多次读写的时候,都是在一个CPU上完成的,所以它是单线程处理这个事。在内存的情况下,这个方案就是最佳方案 — — 阿里 沈询
为什么我们大多时候要使用多线程来提高运行速度呢?
这就和CPU、内存、磁盘的运行速度有关,我们大多数的操作是需要读取数据库、接口数据或者文件再进行逻辑计算,需要操作磁盘IO和网络IO,IO操作的时间远远要大于内存、CPU,不能让CPU就这么等着,就要切换到不需要等待的任务上继续执行。
print(r.mget(["user:1000:index", "user:1001:index"]))
print(r.incr("user:1000:index"))
print(r.incr("user:1001:index"))
print(r.mget(["user:1000:index", "user:1001:index"]))
> [None, '1']
> 1
> 2
> ['1', '2']
注: 由于Redis没有一个明确的类型来表示整型数据,所以这个操作是一个字符串操作。
但事实上,Redis内部采用整数形式来存储这些整数值的字符串的。
INCR/INCRBYFLOAT可以不可以操作同一个key?
print(r.mget(["user:1000:index", "user:1001:index"]))
print(r.decr("user:1000:index"))
print(r.decrby("user:1000:index", 10))
print(r.incr("user:1001:index"))
print(r.incrbyfloat("user:1001:index", 1.4))
print(r.incrby("user:1001:index", 2))
> ['-43', '18']
> -44
> -54
> 19
> 20.4
> value is not an integer or out of range
注:INCRBYFLOAT 可以将一个整型数值转化为浮点数进行操作,如果小数位为0的浮点数进行 INCR操作是可以的,但是 INCR 不会对浮点的数值进行四舍五入的取整操作,如果小数位存在有效数值会触发异常。
String的应用
缓存
有一天个人博客“不太灵光的程序员”里有了一篇爆红的文章,访问量巨高都把要把数据库拉挂了?首先文章的内容的更新频率是不高的,我们就可考虑缓存。
首先定义格式为"article:{ids}:details"的key来表示缓存文章,这里设不设置缓存时间区别不大,如果对文章做修改了SET新的文章到key里就好了。
这样每次有新的请求进来就不会去实时的查数据库,从而降低页面的响应时间。
示例代码:
def get_db():
time.sleep(5)
return "不太灵感的程序带你了解Redis"
def get_article_details(article_id):
details = r.get(f"article:{article_id}:details")
if details:
print('我从缓存来')
return details
else:
print('我从数据库来')
details = get_db()
r.set(f"article:{article_id}:details", details)
return details
if __name__ == "__main__":
for i in range(3):
start = time.time()
details = get_article_details(1001)
end = time.time()
print(details, end - start)


计数器
String的原子递增操作最常用的使用场景是计数器。
还是以我们火爆的博客为例子,怎么才能记录它到底有多火爆呢,肯定需要记录下每篇文章的访问量,让后把每日的访问增量和总量,访问爆发的时间段出个统计去找广告商要钱对不对。
先不考虑session的过滤,只要你点进来就算一次访问,接下来按天来统计每篇文章的访问量。
定义格式为"article:{ids}:visits:date"的key来表示文章一天的访问量,每次用户访问这个页面的时候对这个key执行一下incr命令,这样就可以实现一个简单的计数器了。
示例代码:
def read_article(article_id, date):
details = get_article_details(article_id)
print('当前访问量:', r.incr(f"article:{article_id}:visits:{date}"))
return details
if __name__ == "__main__":
for d in pd.date_range(start='2020-02-20', end='2020-02-25', freq='D'):
date = d.date()
for i in range(random.randint(1, 3)):
details = read_article(1001, date)
visits = r.get(f"article:1001:visits:{date}")
print(f"{date}访问量{visits}")


限速器
限速器是一种可以限制某些操作执行速率的特殊场景。
比如博客里会存在军恶意刷留言、刷点赞的情况,就可以用限速器来控制它。
定义格式为"user:{ids}:gives"的key来表示用户点前时段的点赞数,比方我的博客限制10s最多点赞5次,超过5次就提示"您的点赞次数太多了,请休息一下!",在设置个禁言期 20s。
如果你真的现在我的博客和公众号里点赞留言,请点死我!!!!
快来微信搜一搜关注 “不太灵光的程序员”,给予他力量。
和计数器的区别在与key的有效期,当前的场景里我们是不关注key的到底被点击了多少次,只要在10s里没超过5次就不关心,所以需要加超时时间,每次用户点赞的时候对这个key执行一下incr命令。
示例代码:
def give_article(user_id):
keyname = f"user:{user_id}:gives"
gives = r.get(keyname)
if gives and int(gives) >= 5:
print('您的点赞次数太多了,请休息一下!')
else:
gives = r.incr(keyname)
if r.ttl(keyname) == -1:
r.expire(keyname, 10)
if gives == 5:
r.expire(keyname, 20)
print(f'当前点赞 {gives} 次')
if __name__ == "__main__":
for i in range(60):
give_article(1001)
time.sleep(1)

限制当前发文次数、接口调用次数限制、游戏种体力都可以用到限速器。
推荐阅读:
- Redis实现消息队列的6种方案
- 让运维更简单的7种定时任务实现方式
- 细品28岁程序员退休创业背后的可怕故事
- 工作中都有哪些让你心累的时刻
