基于Virtualbox虚拟机搭建hadoop集群环境
1.1安装centos7
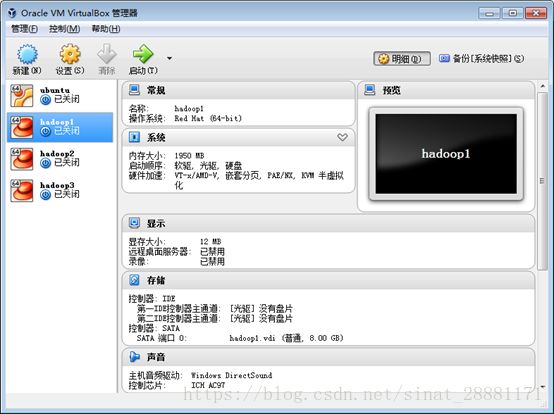
在centos官网下载centos7镜像文件,在Virtualbox软件中导入镜像文件进行安装,本次由于实验环境限制,只安装了三台centos7虚拟机,分别命名为hadoop1,hadoop2,hadoop3,为保证三台虚拟机能够正常通信,三台虚拟机的网络连接方式均设置为仅主机(Host-only)适配器模式,每台虚拟机分配内存为2G,存储为8G。在VrtualBox中搭建好的虚拟机集群如下图所示:
1.2安装JDK
1.2.1安装包准备
由于hadoop是运行于Java之上的,所以安装hadoop之前必须在系统中安装JDK,本次选用的JDK版本为JDK1.8。在oracle官网上下载64位JDK1.8安装文件jdk-8u151-linux-x64.tar.gz,通过建立本地文件传输将系统中的安装包上传到linux系统中,输入:tar –zxvf jdk-8u151-linux-x64.tar.gz命令对压缩包进行解压,完成安装。
1.2.2配置java环境变量
在linux系统中通过编辑profile文件设置Java环境变量,具体操作为:
输入命令:vi/etc/profile,按I键进入profile文件的编辑模式
在profile文件中加入以下几行命令:
JAVA_HOME=/apps/jdk1.8.0_151 #jdk的解压目录
CLASSPATH=.:$JAVA_HOME/lib.tools.jar
PATH=$JAVA_HOME/bin:$PATH
export JAVA_HOME CLASSPATH PATH
修改好文件后通过wq命令保存并退出,再输入source/etc/profile命令使修改生效。
1.2.3验证jdk的有效性
输入java –version命令检查jdk是否安装配置成功,如下图:

证明jdk安装成功
1.3安装hadoop
1.3.1建立ip与域名的映射
为方面后续的相关工作,为每一台虚拟机分配一个静态ip并建立起域名映射。通过编辑/etc/sysconfig/network-scripts/ifcfg-enp0s3文件,输入以下参数进行静态ip配置:

其中的IPADDR即为分配给该主机的静态IP。本次分配给三台虚拟主机的的静态IP分别为:192.168.56.2;192.168.56.3;192.168.56.4.
通过编辑etc/hosts文件建立主机名与域名的映射,本次将三台虚拟主机的域名分别设置为nmnode,ddnode1,ddnode2,如下图:

1.3.2配置ssh免密登录
为方便三台虚拟主机之间的通信,减少输入密码的次数,为三台主机配置ssh免密登录。
输入ssh-keygen -t rsa命令在本台主机生成密钥,再通过ssh copy-id root@主机域名命令实现将密钥拷贝到另一台主机中,实现该主机免密登录本主机。在每台主机生成密钥再将其分发早三台主机之中,实现三台主机之间的免密登录
1.3.3hadoop安装包准备
在apache官网下载hadoop2.6.5安装包hadoop-2.6.5.tar.gz,上传到linux系统后,通过tar命令解压到相应的目录,得到的安装目录结构如下图所示:
![]()
1.3.4修改主要配置文件
主要配置hadoop-2.6.5/etc/hadoop文件夹下的hadoop-env.sh,yarn-env.sh,core-site.xml, hdfs-site.xml, yarn-site.xml,slaves文件。
① 修改hadoop-env.sh,yarn-env.sh的jdk路径
在两个shell文件中修改导入jdk路径的命令,由相对路径改为绝对路径:
export JAVA_HOME=/apps/jdk1.8.0_151
② core-site.xml
该配置文件包含hadoop的一些核心基本配置,本次主要配置了两个属性:
fs.defaultFS
hdfs://nmnode:9000 #默认的文件系统为hdfs,入口为nmnode的9000端口
hadoop.tmp.dir
/apps/hadoop2.6/tmp #设置hadoop临时缓存文件夹
③ hdfs-site.xml
该配置文件主要包含hadoop的分布式文件系统hdfs的一些基本信息,本次主要配置了一个属性:
dfs.replication
1 #文件的备份数为1
④ yarn-site.xml
该配置文件主要包含hadoop分布式计算框架yarn的一些基本信息,本次主要配置如下:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.webapp.address ${yarn.resourcemanager.hostname}:8088
⑤ Slaves
Hadoop通过slave文件确定namenode和datanode,本次将三台虚拟机中的hadoop1作为namenode,hadoop2,hadoop3作为datanode,在salve文件中填入两台datanode的域名ddnode1和ddnode2。
1.3.5启动hadoop
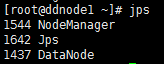
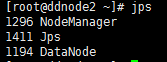
Hadoop配置完毕后,通过scp命令将各配置文件复制到其他主机上,替换原来的文件保证各主机配置相同,此时在namenode节点中通过运行hadoop-2.6.5/sbin文件夹中的start-dfs.sh文件启动hadoop的分布式文件系统hdfs;再运行该文件夹下的start-yarn.sh启动分布式计算框架yarn。启动完成后,在各主机通过jps命令查看hadoop运行状态如下图:

Namenode
Datanode1
Datanode2
基于虚拟机的hadoop集群就此搭建成功