HTTP/2.0 总结
HTTP/2.0 总结
内容:
- HTTP/2 的特点
- 为什么不是 HTTP/1.2
- 二进制分帧层
- 数据流、消息和帧
- 请求与响应复用
- 数据流优先级
- 流控制
- 服务器推送
- 首部压缩
1. HTTP/2 的特点
HTTP/2 的特性就是可以让我们的应用更快、更简单、更稳定。就这么简单。
HTTP/2 的目的是通过支持完整的请求与响应复用来减少延迟,通过有效压缩 HTTP 标头字段将协议开销降至最低,同时增加对请求优先级和服务器推送的支持。虽然这样,HTTP/2 没有改变 HTTP 的语义。HTTP 方法、状态代码、URI 和标头字段等核心概念一如往常。不过,HTTP/2 修改了数据格式化(分帧)以及在客户端与服务器间传输的方式。这两个设计是这个协议的核心。通过新的分帧层向我们的应用隐藏了所有复杂性。因此,所有现有的应用都可以不必修改而在新协议下运行。
2. 为什么不是 HTTP/1.2
为了实现 HTTP 工作组设定的性能目标,HTTP/2 引入了一个新的二进制分帧层,该层无法与之前的 HTTP/1.x 服务器和客户端向后兼容,因此协议的主版本提升到 HTTP/2。
即便如此,除非您在实现网络服务器(或自定义客户端),需要使用原始的 TCP 套接字,否则应该是注意不到任何区别滴,因为所有新的 低级分帧 由客户端和服务器来执行。可观察到的唯一区别将是性能的提升和请求优先级、流控制与服务器推送等新功能的出现。
3. 二进制分帧层
HTTP/2 所有性能增强的核心在于新的二进制分帧层,它定义了如何封装 HTTP 消息并在客户端与服务器之间传输。

3_1binary_framing_layer01
这里所谓的“层”,指的是位于套接字接口与应用可见的高级 HTTP API 之间一个经过优化的新编码机制:HTTP 的语义都不受影响,不同的是传输期间对它们的编码方式变了。HTTP/1.x 协议以换行符作为纯文本的分隔符,而 HTTP/2 将所有传输的信息分割为更小的消息和帧,并采用二进制格式对它们编码。
这样一来,客户端和服务器为了相互理解,都必须使用新的二进制编码机制:HTTP/1.x 客户端无法理解只支持 HTTP/2 的服务器,反之亦然。所以两头都是要进行更新的。
4. 数据流、消息和帧
新的二进制分帧机制改变了客户端与服务器之间交换数据的方式。 为了说明这个过程,我们需要了解 HTTP/2 的三个概念:
- 数据流:已建立的连接内的双向字节流,可以承载一条或多条消息。
- 消息:与逻辑请求或响应消息对应的完整的一系列帧。
- 帧:HTTP/2 通信的最小单位,每个帧都包含帧头,至少也会标识出当前帧所属的数据流。
这些概念的关系总结如下:
- 所有通信都在一个 TCP 连接上完成,此连接可以承载任意数量的双向数据流。
- 每个数据流都有一个唯一的标识符和可选的优先级信息,用于承载双向消息。
- 每条消息都是一条逻辑 HTTP 消息(例如请求或响应),包含一个或多个帧。
- 帧是最小的通信单位,承载着特定类型的数据,例如 HTTP 标头、消息负载,等等。 来自不同数据流的帧可以交错发送,然后再根据每个帧头的数据流标识符重新组装。
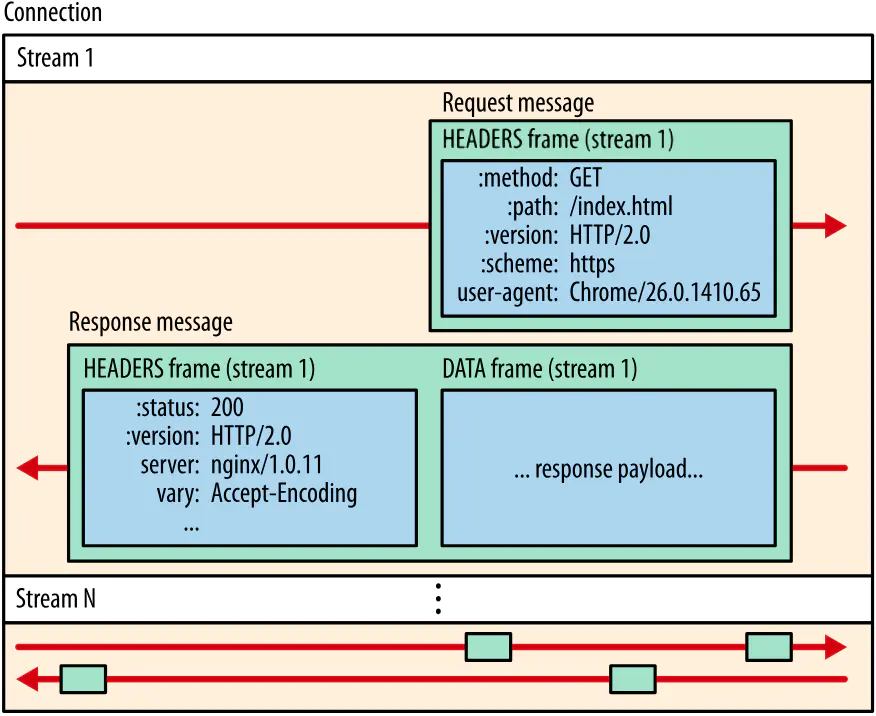
streams_messages_frames01
上图中就是 流、消息、帧 之间的关系。简言之,HTTP/2 将 HTTP 协议通信分解为二进制编码帧的交换,这些帧对应着特定数据流中的消息。所有这些都在一个 TCP 连接内复用。这是 HTTP/2 协议所有其他功能和性能优化的基础。
这里给出 帧-frame 的结构
- Length : 24位无符号整数的帧主体长度。8字节长度的帧报头信息不计算在此内。
- Type : 帧的8位类型。帧类型定义了剩余的帧报头和帧主体将如何被解释。具体实现必须在收到未知帧类型(任何未在文档中定义的帧)时作为连接错误中的类型协议错误(PROTOCOL_ERROR)处理。
- Flags : 为帧类型保留的8字节字段有具体的布尔标识。 标识针对确定的帧类型赋予特定的语义。确定帧类型定义语义以外的标示必须被忽略,并且必须在发送的时候保留未设置(0)。
- R : 1位的保留字段。这个字段的语义未设置并且必须在发送的时候保持未设置(0),在接受的时候必须被忽略。
- Stream Identifier : 31字节的流标识符(见StreamIdentifiers)。0是保留的,标明帧是与连接相关作为一个整体而不是一个单独的流。

frame_layout.png
帧的最大长度在接收端返回的 SETTINGS_MAX_FRAME_SIZE 中设定,范围是2^14 (16,384) 到 2^24-1(16,777,215) 字节。
5. 请求与响应复用
在 HTTP/1.x 中,如果客户端要想发起多个并行请求以提升性能,则必须使用多个 TCP 连接。这是 HTTP/1.x 交付模型的直接结果,该模型可以保证每个连接每次只交付一个响应(响应排队)。更糟糕的是,这种模型也会导致队首阻塞,从而造成底层 TCP 连接的效率低下。
怎么个队首阻塞呢?基本上是这样:
- http1.0的队首阻塞
对于同一个tcp连接,所有的http1.0请求放入队列中,只有前一个请求的响应收到了,然后才能发送下一个请求。可见,http1.0的队首组塞发生在客户端。
- http1.1的队首阻塞
对于同一个tcp连接,http1.1允许一次发送多个http1.1请求,也就是说,不必等前一个响应收到,就可以发送下一个请求,这样就解决了http1.0的客户端的队首阻塞。但是,http1.1规定,服务器端的响应的发送要根据请求被接收的顺序排队,也就是说,先接收到的请求的响应也要先发送。这样造成的问题是,如果最先收到的请求的处理时间长的话,响应生成也慢,就会阻塞已经生成了的响应的发送。也会造成队首阻塞。可见,http1.1的队首阻塞发生在服务器端。
HTTP/2 中新的二进制分帧层突破了这些限制,实现了完整的请求和响应复用:客户端和服务器可以将 HTTP 消息分解为互不依赖的帧,然后交错发送,最后再在另一端把它们重新组装起来。正因为打破了相互依赖的关系,所以只要tcp没有人在用那么就可以发送已经生成的requst或者reponse的数据,在两端都不用等,从而彻底解决了http协议层面的队首阻塞问题。

上图展示了同一个连接内并行的多个数据流。客户端正在向服务器传输一个 DATA 帧(数据流 5),与此同时,服务器正向客户端交错发送数据流 1 和数据流 3 的一系列帧。因此,一个连接上同时有三个并行数据流。
将 HTTP 消息分解为独立的帧,交错发送,然后在另一端重新组装是 HTTP/2 最重要的一项增强。事实上,这个机制会在整个网络技术栈中引发一系列连锁反应,从而带来巨大的性能提升,因为我们可以:
- 并行交错地发送多个请求,请求之间互不影响。
- 并行交错地发送多个响应,响应之间互不干扰。
- 使用一个连接并行发送多个请求和响应。
- 不必再为绕过 HTTP/1.x 限制而做很多工作(例如 mage sprites 和域名分片。
- 消除不必要的延迟和提高现有网络容量的利用率,从而减少页面加载时间。
等等…
HTTP/2 中的新二进制分帧层不仅解决了 HTTP/1.x 中存在的队首阻塞问题,也消除了并行处理和发送请求及响应时对多个连接的依赖。结果就是,应用速度更快、开发更简单、部署成本更低。
6. 数据流优先级
那么问题来了,数据不能保证有序就是无用的数据,所以怎么保证有序?还要加个保证有序的机制才行! 为了做到这一点,HTTP/2 标准允许每个数据流都有一个关联的权重和依赖关系:
- 可以向每个数据流分配一个介于 1 至 256 之间的整数。
- 每个数据流与其他数据流之间可以存在显式依赖关系。
数据流依赖关系和权重的组合让客户端可以构建和传递“优先级树”,表明它倾向于如何接收响应。反过来,服务器可以使用此信息通过控制 CPU、内存和其他资源的分配设定数据流处理的优先级,在资源数据可用之后,带宽分配可以确保将高优先级响应以最优方式传输至客户端。
[站外图片上传中...(image-a77752-1537234470817)]
HTTP/2 内的 数据流 依赖关系是通过将 另一个数据流 的唯一标识符作为父项引用来实现的;如果忽略标识符,相应数据流将依赖于“根数据流”。声明数据流依赖关系指出,应尽可能先向父数据流分配资源,然后再向其依赖项分配资源。换句话说,“请先处理和传输响应 D,然后再处理和传输响应 C”。
共享相同父项的数据流(即,同级数据流)应按其权重比例分配资源。 例如,如果数据流 A 的权重为 12,其同级数据流 B 的权重为 4,那么要确定每个数据流应接收的资源比例,就执行以下操作:
将所有权重求和:4 + 12 = 16。
将每个数据流权重除以总权重:A = 12/16, B = 4/16
因此,数据流 A 应获得四分之三的可用资源,数据流 B 应获得四分之一的可用资源;
数据流 B 获得的资源是数据流 A 所获资源的三分之一。
上图中的四棵树,顺序为从左到右:
- 数据流 A 和数据流 B 都没有指定父依赖项,依赖于显式“根数据流”;A 的权重为 12,B 的权重为 4。因此,根据比例权重:数据流 B 获得的资源是 A 所获资源的三分之一。
- 数据流 D 依赖于根数据流;C 依赖于 D。因此,D 应先于 C 获得完整资源分配。权重不重要,因为 C 的依赖关系拥有更高的优先级。
- 数据流 D 应先于 C 获得完整资源分配;C 应先于 A 和 B 获得完整资源分配;数据流 B 获得的资源是 A 所获资源的三分之一。
- 数据流 D 应先于 E 和 C 获得完整资源分配;E 和 C 应先于 A 和 B 获得相同的资源分配;A 和 B 应基于其权重获得比例分配。
如上面的示例所示,数据流依赖关系和权重的组合明确表达了资源优先级,这是一种用于提升浏览性能的关键功能,网络中拥有多种资源类型,它们的依赖关系和权重各不相同。不仅如此,HTTP/2 协议还允许客户端随时更新这些优先级,进一步优化了浏览器性能。换句话说,我们可以根据用户互动和其他信号更改依赖关系和重新分配权重。
7. 流控制
流控制是一种阻止发送方向接收方发送大量数据的机制,以免超出后者的需求或处理能力:发送方可能非常繁忙、处于较高的负载之下,也可能仅仅希望为特定数据流分配固定量的资源。例如,客户端可能请求了一个具有较高优先级的大型视频流,但是用户已经暂停视频,客户端现在希望暂停或限制从服务器的传输,以免提取和缓冲不必要的数据。再比如,一个代理服务器可能具有较快的下游连接和较慢的上游连接,并且也希望调节下游连接传输数据的速度以匹配上游连接的速度来控制其资源利用率;等等。
整理到这里我自己都懵了,怕不是记录的TCP协议,哦,并不是。这个 2.0 版显然要搞事情。
不过,由于 HTTP/2 数据流在一个 TCP 连接内复用,TCP 流控制既不够精细,也无法提供必要的应用级 API 来调节各个数据流的传输。为了解决这一问题,HTTP/2 提供了一组简单的构建块,这些构建块允许客户端和服务器实现其自己的数据流和连接级流控制:
流控制具有方向性。每个接收方都可以根据自身需要选择为每个数据流和整个连接设置任意的窗口大小。
每个接收方都可以公布其初始连接和数据流流控制窗口(以字节为单位),每当发送方发出 DATA 帧时都会减小,在接收方发出 WINDOW_UPDATE 帧时增大。
流控制无法停用。建立 HTTP/2 连接后,客户端将与服务器交换 SETTINGS 帧,这会在两个方向上设置流控制窗口。流控制窗口的默认值设为 65,535 字节,但是接收方可以设置一个较大的最大窗口大小(2^31-1 字节),并在接收到任意数据时通过发送 WINDOW_UPDATE 帧来维持这一大小。
HTTP/2 很懒,未指定任何特定算法来实现流控制。就是说老子戏台子搭好了,你们谁想唱就来唱。
8. 服务器推送
HTTP/2 新增的另一个强大的新功能就是 服务器 可以对一个客户端请求发送多个响应。 换句话说,除了对最初请求的响应外,服务器还可以向客户端推送额外资源,而无需客户端明确地请求。
[站外图片上传中...(image-db5e12-1537234470817)]
为什么在浏览器中需要一种此类机制呢?一个典型的网络应用包含多种资源,客户端需要检查服务器提供的文档才能逐个找到它们。那为什么不让服务器提前推送这些资源,从而减少额外的延迟时间呢?服务器已经知道客户端下一步要请求什么资源,这时候服务器推送即可派上用场。就像上面图上的例子一样,同样还比如网页的图片加载,客户端不用再说“我还要加载某某图片”,服务器直接扔它脸上。
9. 首部压缩
每个 HTTP 传输都承载一个首部,请求头活着响应头,这些首部说明了传输的资源及其属性。 在 HTTP/1.x 中,此元数据始终以纯文本形式,通常会给每个传输增加 500–800 字节的开销。如果使用 HTTP Cookie,增加的开销有时会达到上千字节。为了减少此开销和提升性能,HTTP/2 使用 HPACK 压缩格式压缩请求和响应标头元数据,这种格式采用了两种技术:
- 这种格式支持通过静态 Huffman 代码对传输的标头字段进行编码,从而减小了各个传输的大小。
- 这种格式要求客户端和服务器同时维护和更新一个包含之前见过的标头字段的索引列表(换句话说,它可以建立一个共享的压缩上下文),此列表随后会用作参考,对之前传输的值进行有效编码。
利用 Huffman 编码,可以在传输时对各个值进行压缩,而利用之前传输值的索引列表,我们可以通过传输索引值的方式对重复值进行编码,索引值可用于有效查询和重构完整的标头键值对。
[站外图片上传中...(image-7f4944-1537234470817)]
作为一种进一步优化方式,HPACK 压缩上下文包含一个静态表和一个动态表:
- 静态表在规范中定义,并提供了一个包含所有连接都可能使用的常用 HTTP 标头字段(例如,有效标头名称)的列表;
- 动态表最初为空,将根据在特定连接内交换的值进行更新。
因此,为之前未见过的值采用静态 Huffman 编码,并替换每一侧静态表或动态表中已存在值的索引,可以减小每个请求的大小。
今天先记录到这吧,还有帧的分类,错误码,安全机制没有说,具体的自己查吧。
参考文献:
《谷歌开发者 Web Fundamentals》
RFC7540
微信扫一扫
