【Paper】DeepSaliency: Multi-Task Deep NeuralNetwork Model for Salient Object Detection
DeepSaliency: Multi-Task Deep NeuralNetwork Model for Salient Object Detection_CVPR2015,TIP2016
李玺,赵李明-浙大人工智能研究所
Xi Li, Liming Zhao, Lina Wei, Ming-HsuanYang, Senior Member, IEEE, Fei Wu, Yueting Zhuang, Haibin Ling, and JingdongWang(微软亚研院)
Motivations:
作为计算机视觉中的一个重要且具有挑战性的问题,显著目标检测旨在自动发现和定位与人类感知一致的视觉感兴趣的区域。它有很广的应用,如目标跟踪和识别,图像压缩,图像和视频检索,照片拼贴,视频事件检测等,显著目标检测的重点在于设计各种计算模型来测量图像显着性,这对于分割是有用的。
一般来说,每个目标可以在三个不同的级别(即,低级,中级和高级)上表示。低级视觉涉及原始图像特征,例如颜色,边缘和纹理。中级特征通常对应于关于轮廓,形状和空间上下文的对象信息。高级视觉信息与目标识别与分割以及目标之间的内在语义交互以及背景相关联。本质上,显著目标检测与这三个层次同时相关。因此,如何有效地所有上述因素建模在一个统一的学习框架是一个关键和具有挑战性的问题。

大多数已有的方法是采取多种先验知识检测,如背景先验、中心先验、对比先验,然而显著目标也常出现在图像边缘,与中心远离,因此中心先验就没用了,而且有时显著目标和背景部分区域相似这就比较难检测了。
通过这些观察,本文构建了一个自适应模型,在纯数据驱动框架中以有效地捕获显著目标的内在语义属性及其与背景的本质区别。同时这个模型可以对不同级别的视觉特征编码(图1)。
Contributions:
1) We propose a multi-task FCNN based approach to model the intrinsic semantic properties of salient objects in a totally data-driven manner. The proposed approach performs collaborative feature learning for the two correlated tasks (i.e., saliency detection and semantic image segmentation), which generally leads to the performance improvement of saliency detection in object perception. Moreover, it effectively enhances the feature-sharing capability of salient object detection by using the fully convolutional layers, resulting in a significant reduction of feature redundancy.
2) We present a fine-grained super-pixel driven saliency refinement model based on graph Laplacian regularized nonlinear regression with the output of the proposed FCNN model. The presented model admits a closed-form封闭式 solution,and is able to accurately preserve object boundary information for saliency detection.
Methods:
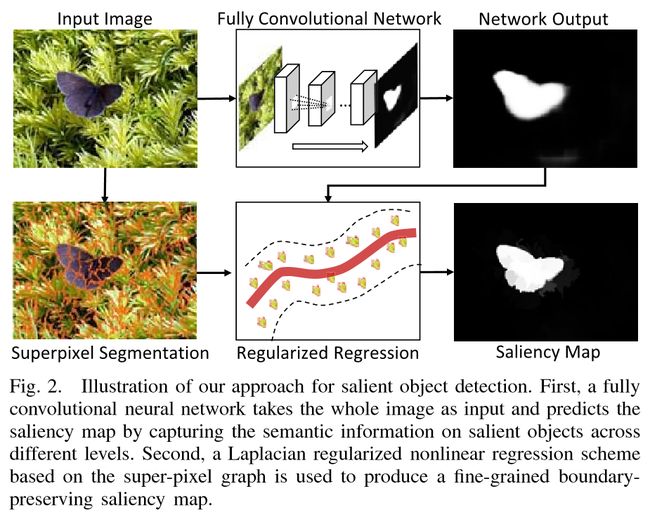
方法流程:
给定一张图,首先用FCNN去计算得到粗纹理的显著性图作为前景信息,同时对这张图进行超像素分割,图像的边界超像素被视为背景种子样本,然后可以通过基于非线性回归的传播来计算别的粗纹理显著性图,之后,粗前景显著性图和背景显著性图结合一起,最终基于图形拉普拉斯正则化非线性回归精化处理,图2 是主要步骤。
1 多任务FCNN
·网络框架
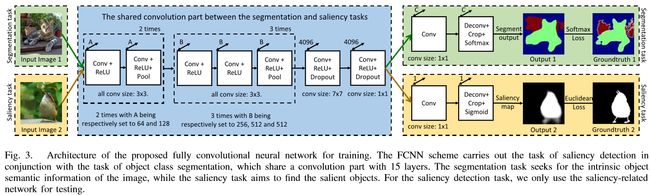
FCNN框架结合显著性检测和目标类分割的任务,其共享具有15个层的卷积部分。
a.共享卷积部分:是为了提取不同语义级别的输入图像的特征的集合。前13层是用vgg-13初始化,为了进一步建模整个图像的空间相关性,只使用完全卷积学习架构(没有任何全连接层)。这是因为完全卷积操作具有在整个图像上共享卷积特征的能力,导致特征冗余的减少。
b.目标分割任务:是为了找到图像的内在目标的语义信息。反卷积层中的参数在训练期间被更新以学习上采样函数。最终输出C个对象类(包括背景)的C个概率图,并且可以使用groudtruth分割图的像素级别的softmax损失函数来训练。??
c.显著性检测任务:是为了找到图像中感兴趣的目标。最后一层是平方欧几里得损失层squared Euclidean loss layer用于显著性回归,从数据学习显著性属性。
损失函数:
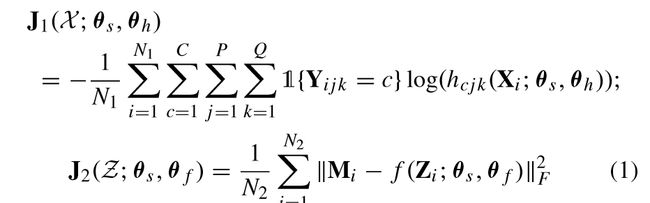
stochastic gradient descent (SGD) method用随机梯度下降法最小化损失函数来训练,两个不同的任务训练样本不同,损失函数不同(cross-entropy交叉熵/squared Euclidean loss term).首先学习分割任务的参数θs和θh,然后学习参数θf以及更新显著性任务的参数θs。
图4是一些直观的例子以显示网络捕获的底层显著性属性。

·用正则化回归来精化
利用内部均匀和边界保留的超像素(通过使用SLIC [45]的过分割获得)作为基本表示单元,然后用空间和特征维度的超像素来构造超像素级邻接图来建模超像素之间的拓扑关系。
在基于图的半监督回归方面,一些超像素被视为具有预先指定的显著性得分的种子样本(例如边界超像素),并且剩余超像素的显著状态暂时未确定(初始化为0),直到它们通过传播到达。
因此,现在的任务是在以下优化框架内学习给定超像素x 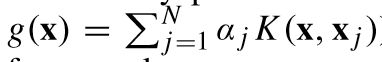 的显著性预测的非线性回归函数:
的显著性预测的非线性回归函数:

[第一项在上述优化问题对应于平方回归损失,第三项确保最终显著图的空间平滑性。]
优化问题的最优解是下图,根据g(x),看可以计算一个图像上任意一个超像素x的显著性分数。

·生成显著性图像
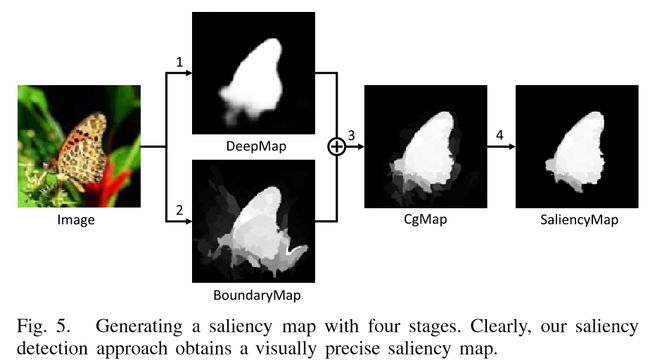
需要四步:
1) object perception by FCNN; FCNN的目标感知;
2) image boundary information propagation within the super-pixel graph; 超像素图内的图像边界信息传播
3) coarse-grained saliency information fusion; 粗纹理显著性信息融合
4) fine grained saliency map generation by non-linear regression-based propagation通过非线性回归传播的细粒度显著性图生成。
Experiments:
DATASETS:
the ASD [29], DUT-OMRON [17], ECSSD [20],PASCAL-S [47], THUR [48], THUS [35], SED2 [49], and SOD [50] datasets.
The first six datasets are composed of object-centric images distributed in relatively simple scenes (e.g., high object contrast and clean background). In contrast, the last two datasets are more challenging with multiple salient objects and background clutters in images.

第三行和第八行效果很不错。
COMPARISION:
compare the proposed approach with several state-of-the-art methods including DeepMC [30], DRFI [37], Wco [18], GC [4],GMR [17], FT [29], MC [3], HS [20], SVO [2], DSR [56], LEGS [36], BL15 [57] and BSCA [19].
Advantages:
1 we propose a simple yet effective multitask deep saliency approach for salient object detection based on the fully convolutional neural network with global input (whole raw images) and global output (whole saliency maps).
2 The proposed saliency approach models the intrinsic semantic properties of salient objects in a totally data-driven manner, and performs collaborative feature learning for the two correlated tasks (i.e., saliency detection and semantic image segmentation), which generally leads to the saliency performance improvement in object perception.
3 Experimental results on the eight benchmark datasets demonstrate the proposed approach performs favorably in different evaluation metrics against the state-of-the-art methods.
Disadvantages:
salient object detection & semantic image segmentation 使用不同数据集,联系小
semantic image segmentation 没测试对比