【今日CV 计算机视觉论文速览 第138期】Mon, 1 Jul 2019
今日CS.CV 计算机视觉论文速览
Mon, 1 Jul 2019
Totally 71 papers
?上期速览✈更多精彩请移步主页

Interesting:
?***PointFlow基于连续norm流生成点云, 提出了一种点云的生成方法PointFlow,通过构建点云分布的 分布来进行建模并在概率框架下实现点云生成。研究人员利用两级的层级分布来处理这个问题,第一层用于处理形状的分布,第二层用于处理给定形状下的点云分布。(from 康奈尔)

这使得研究人员可以在采样形状的同时也可以采样任意数量的点。这种方法通过连续的归一化流来学习两个不同层级的分布。这种可逆的归一化流可以在训练时计算似然,并使得模型可以实现变分推理。
模型的架构,训练时的编码器对输入点云进行编码,并同时输出三个损失,在测试时直接利用z进行形状和点云的采样:

生成的点云结果:
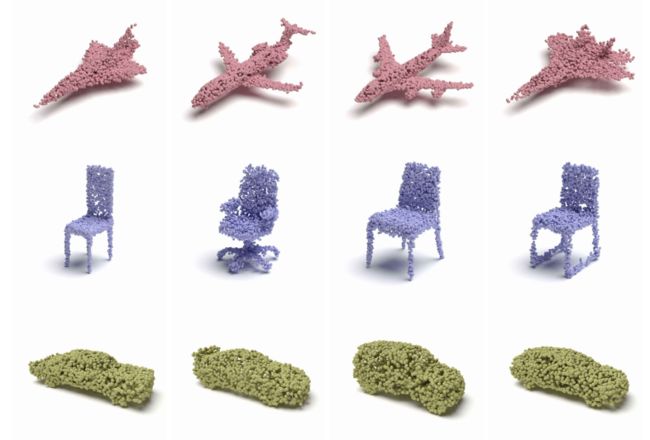
project:https://www.guandaoyang.com/PointFlow/
code:https://github.com/stevenygd/PointFlow
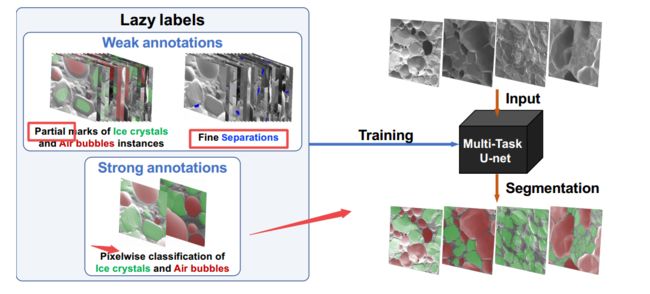
?基于弱监督的多任务U-Net, 基于粗糙的数据标签和少数像素级别标注的数据进行多类别分割任务(laze label data,食物的扫描电镜图像ice cream SEM images )。将实例的粗分割、分离出没有清晰边界的物体,以及像素级的分割来寻找精确的边界三个任务进行融合。(from 剑桥)
?Deep Radar Detector对于雷达信号检测进行处理, 将深度学习对于激光雷达的处理拓张到了微波雷达中,同时提出了数据集和雷达数据增强技术。(from Tel-Aviv University)
?教会cnn设计时尚衣服纹理, 提出了一种自动探索、检测合成时装的新方法(from Myntra Designs 印度 KDD 2019 Workshop)

一些得到的结果:


Daily Computer Vision Papers
| PointFlow: 3D Point Cloud Generation with Continuous Normalizing Flows Authors Guandao Yang, Xun Huang, Zekun Hao, Ming Yu Liu, Serge Belongie, Bharath Hariharan 随着3D点云成为多视觉和图形应用的选择,合成或重建高分辨率,高保真点云的能力变得至关重要。尽管深度学习模型最近在点云的判别任务中取得了成功,但生成点云仍然具有挑战性。本文提出了一个原理概率框架,通过将它们建模为分布分布来生成三维点云。具体来说,我们学习了两级分布层次,其中第一层是形状的分布,第二层是给定形状的点的分布。这个公式允许我们对形状进行采样并从形状中采样任意数量的点。我们的生成模型,名为PointFlow,通过连续的标准化流程来学习每个级别的分布。归一化流的可逆性使得能够在训练期间计算可能性,并允许我们在变分推理框架中训练我们的模型。根据经验,我们证明PointFlow在点云生成方面实现了最先进的性能。我们还表明,我们的模型可以忠实地重建点云,并以无人监督的方式学习有用的表示。代码将在 |
| On the notion of number in humans and machines Authors Norbert B tfai, D vid Papp, Gerg Bogacsovics, M t Szab , Viktor Szil rd Simk , M ri Bersenszki, Gergely Szab , Lajos Kov cs, Ferencz Kov cs, Erik Szilveszter Varga 在本文中,我们进行了两种类型的软件实验来研究人体和机器中的数量级分类。专注于特定类型任务的实验被称为语义MNIST或简称为SMNIST,其中必须确定放置在图像中的对象的数量。用于人类的SMNIST实验旨在测量人类目标文件系统的容量。在这种类型的实验中,测量结果与认知心理学文献中已知的值非常一致。名为SMNIST for Machines的实验用于类似的目的,但他们调查现有的,众所周知但最初为其他目的和正在开发的深度学习计算机程序开发的。这些测量结果可以解释为类似于SMNIST对人类的结果。本文的主要论文可以在机器中制定如下:当这些数值小于人类OFS的能力时,图像分类人工神经网络可以学习区分数值更高的精度。最后,我们概述了一个概念框架,用于研究人类和机器中数字的概念。 |
| Adversarial Pixel-Level Generation of Semantic Images Authors Emanuele Ghelfi, Paolo Galeone, Michele De Simoni, Federico Di Mattia 生成性对抗网络GAN在生成逼真图像方面取得了非凡的成功,这是一种可接受较低像素级精度的领域。我们研究了从先前的分布开始生成语义图像的问题,但尚未在文献中解决。直观地,可以使用标准方法和体系结构来解决该问题。然而,需要更合适的方法来避免产生模糊,幻觉和因此不可用的图像,因为诸如语义分割之类的任务需要像素级精确性。在这项工作中,我们提出了一种新颖的架构,用于学习生成像素级准确的语义图像,即语义生成对抗网络SemGAN。实验评估表明,在许多语义图像生成任务中,我们的架构从定量和定性的角度都优于标准架构。 |
| A Deep Decoder Structure Based on WordEmbedding Regression for An Encoder-Decoder Based Model for Image Captioning Authors Ahmad Asadi, Reza Safabakhsh 近年来,生成图像的文本描述一直是计算机视觉和自然语言处理研究人员的一个有吸引力的问题。已经提出了许多基于深度学习的模型来解决这个问题。现有方法基于配备有关注机制的神经编码器解码器结构。这些方法努力训练解码器以最小化给定先前的句子中的下一个单词的对数似然性,这导致输出空间的稀疏性。在这项工作中,我们提出了一种新的方法来训练解码器,使相对于先前的单词嵌入下一个单词的单词,而不是最小化对数似然。所提出的方法能够学习和提取长期信息,并且可以生成更长的细粒度字幕而不引入任何外部存储器单元。此外,通过所提出的技术训练的解码器可以在生成字幕时考虑所生成的字的重要性。此外,提出了一种新颖的语义注意机制,通过图像引导注意点,同时考虑先前生成的单词的含义。我们使用MS COCO数据集评估建议的方法。所提出的模型优于最先进的模型,特别是在生成更长的字幕时。它获得了等于125.0的CIDEr分数和等于50.5的BLEU 4分数,而现有技术模型的最佳分数分别为117.1和48.0。 |
| Deep Radar Detector Authors Daniel Brodeski, Igal Bilik, Raja Giryes 自从引入深度学习以来,相机和激光雷达处理已经发生了革命性的变化,雷达处理仍然依赖于经典工具。在本文中,我们介绍了雷达处理的深度学习方法,直接与雷达复杂数据一起工作。为了克服雷达标记数据的缺乏,我们仅依靠雷达校准数据进行训练,并引入新的雷达增强技术。我们在雷达4D检测任务上评估我们的方法,并且与传统方法相比表现出优越的性能,同时保持实时性能。对雷达数据应用深度学习具有几个优点,例如每次都不需要昂贵的雷达校准过程,并且能够以几乎为零的开销对检测到的物体进行分类。 |
| Reconstructing Perceived Images from Brain Activity by Visually-guided Cognitive Representation and Adversarial Learning Authors Ziqi Ren, Jie Li, Xuetong Xue, Xin Li, Fan Yang, Zhicheng Jiao, Xinbo Gao 基于功能磁共振成像fMRI测量的脑信号重建感知图像是脑驱动计算机视觉中的重要且有意义的任务。然而,fMRI信号和视觉图像之间的不一致分布和表示导致异质性差异,这使得学习它们之间的可靠映射具有挑战性。此外,考虑到fMRI信号具有极高的维度并且包含许多视觉上无关的信息,有效地降低噪声并编码用于图像重建的强大视觉表示也是一个开放的问题。我们表明,通过学习由相应视觉特征引导的fMRI信号的视觉相关潜在表示,并通过对抗性学习恢复感知图像,可以克服这些挑战。得到的框架称为双变分自动编码器生成对抗网络D VAE GAN。通过使用新颖的3阶段训练策略,它通过双结构变分自动编码器D VAE编码认知和视觉特征,以使认知特征适应视觉特征空间,然后学习利用生成对抗网络GAN重建感知图像。对三个fMRI记录数据集的大量实验表明,与现有技术方法相比,D VAE GAN实现了更精确的视觉重建。 |
| A multi-task U-net for segmentation with lazy labels Authors Rihuan Ke, Aur lie Bugeau, Nicolas Papadakis, Peter Schuetz, Carola Bibiane Sch nlieb 对劳动密集型像素明确注释的需求是许多用于图像分割的完全监督学习方法的主要限制。在本文中,我们提出了一种用于多类分割的深度卷积神经网络,通过在粗略数据标签上训练并且仅使用具有像素明确注释的非常少量的图像来训练该问题。我们将这种新的标签策略称为懒惰标签。然后将图像分割分层为三个连接的任务,粗略检测类实例,分离错误连接的对象而没有清晰的边界,以及像素分割以找到每个对象的准确边界。这些问题被集成到多任务学习框架中,并且模型以半监督的方式端到端地进行训练。该方法应用于食物显微镜图像的数据集。我们表明,即使大多数带注释的数据缺少精确的边界标签,该模型也能提供准确的分割结果。通过收集比精确分割的图像更加懒惰的粗略注释,这允许更多的灵活性和效率来训练在手动注释昂贵的实际环境中数据饥饿的深度神经网络。 |
| Filter Early, Match Late: Improving Network-Based Visual Place Recognition Authors Stephen Hausler, Adam Jacobson, Michael Milford CNN在执行位置识别方面具有优势,特别是当神经网络针对当前环境条件下的定位进行优化时。在本文中,我们研究了特征映射过滤的概念,其中,不使用卷积张量内的所有激活,而是仅使用最有用的激活。由于特定要素图编码不同的视觉特征,因此目标是移除特征贴图,这些特征贴图会降低在外观变化中识别位置的能力。我们的关键创新是在早期卷积层中过滤特征图,但随后继续运行网络并使用同一网络中的后一层提取特征向量。通过过滤早期视觉特征并从更高,更多视点不变的后期层提取特征向量,我们证明了改进的条件和视点不变性。我们的方法需要从部署环境进行训练的图像对,但我们表明,只需一个训练图像对就可以定期实现最先进的性能。进行详尽的实验分析以确定早期层过滤和后期层提取之间的因果关系的全部范围。为了有效性,我们使用三个数据集Oxford RobotCar,Nordland和Gardens Point,实现了NetVLAD的整体优越性能。这项工作提供了许多探索CNN优化的新途径,没有经过全面的培训。 |
| Are you really looking at me? A Framework for Extracting Interpersonal Eye Gaze from Conventional Video Authors Minh Tran, Taylan Sen, Kurtis Haut, Mohammad Rafayet Ali, Mohammed Ehsan Hoque 尽管视频摄像机在我们日常生活中的普遍性发生了革命,但非常有意义的非语言情感交流形式之一,人际视线注视,即相对于会话伙伴的目光注视,并不能从普通视频中获得。我们介绍了Interpersonal Calibrating Eye凝视编码器ICE,它可以自动从视频录制中提取人际凝视,无需专门的硬件,也无需事先了解参与者位置。利用个人花费大量对话看彼此的直觉,使ICE动态聚类算法能够提取人际凝视。我们使用具有红外凝视跟踪器F1 0.846,N 8的客观度量在视频聊天中验证ICE,以及与眼接触r 0.37,N 170的专家评级评估的面对面通信。然后,我们使用ICE来分析两种不同但重要的情感交流领域中的行为,基于欺骗检测的审讯和快速约会中的沟通技巧评估。我们发现,在回答问题时,诚实的证人打破了人际关系的凝视联系,并且比欺骗性的证人往往更容易往下看p 0.004,d 0.79。在预测速度约会视频中的专家沟通技能评级时,我们证明单独的人际凝视比面部表情具有更强的预测能力。 |
| Road-network-based Rapid Geolocalization Authors Yongfei Li, Dongfang Yang, Shicheng Wang, Hao He 利用地理信息协助无人驾驶飞行器的导航一直是研究的热点。本文提出了一种基于路网的定位方法。我们将测量图像中的道路与参考道路矢量地图进行匹配,并在与整个城市一样大的区域上实现成功定位。道路网络匹配问题被视为二维投影变换下的点云配准问题,并在假设和测试框架下求解。为了处理投影点云配准问题,提出了一种全局投影不变特征,它由两条道路交叉点组成,并增加了它们的切线信息。我们称之为两个道路交叉点元组。我们推导出用于确定来自一对匹配的两个道路交叉元组的对齐变换的封闭形式解决方案。此外,我们提出了元组匹配的必要条件。这可以减少候选匹配元组,从而在很大程度上加速搜索。我们在假设和测试框架下测试所有候选匹配元组以搜索最佳匹配。实验表明,我们的方法可以在一个cpu上在1秒内在400区域内定位目标区域。 |
| New pointwise convolution in Deep Neural Networks through Extremely Fast and Non Parametric Transforms Authors Joonhyun Jeong, Sung Ho Bae 诸如离散Walsh Hadamard变换DWHT和离散余弦变换DCT的一些常规变换已被广泛用作图像处理中的特征提取器,但很少应用于神经网络。然而,我们发现这些传统变换具有捕获跨信道相关性的能力,而DNN中没有任何可学习的参数。本文首先提出将常规变换应用于逐点卷积,表明这种变换显着降低了神经网络的计算复杂度,而没有精度性能下降。特别是对于DWHT,它不需要浮点乘法,只需要加法和减法,这可以大大减少计算开销。此外,其快速算法进一步降低了从mathcal O n 2到mathcal O n log n的浮点加法的复杂性。这些不错的属性在数字参数和操作中构建了非常有效的网络,从而获得了准确性。我们提出的基于DWHT的模型与CIFAR 100数据集上的基线模型MoblieNet V1相比,准确度提高了1.49,参数减少了79.1,FLOP减少了48.4。 |
| Gesture Recognition in RGB Videos UsingHuman Body Keypoints and Dynamic Time Warping Authors Pascal Schneider, Raphael Memmesheimer, Ivanna Kramer, Dietrich Paulus 手势识别为人类直观地与机器交互开辟了新途径。特别是对于服务机器人,手势可以是通信手段的有价值的补充,例如,将机器人的注意力吸引到某人或某物上。从视频数据中提取手势并对其进行分类是一项具有挑战性的任务,并且多年来已经提出了各种方法。本文提出了一种RGB视频中的手势识别方法,该方法使用OpenPose提取人的姿势,动态时间扭曲DTW与一个最近邻1NN一起用于时间序列分类。这种方法的主要特征是任何特定硬件的独立性和高度灵活性,因为可以通过仅添加几个示例将新手势添加到分类器。我们利用基于深度学习的OpenPose框架的稳健性,同时避免自己训练神经网络的数据密集型任务。我们使用公共数据集演示了我们方法的分类性能。 |
| LipReading with 3D-2D-CNN BLSTM-HMM and word-CTC models Authors Dilip Kumar Margam, Rohith Aralikatti, Tanay Sharma, Abhinav Thanda, Pujitha A K, Sharad Roy, Shankar M Venkatesan 近年来,基于深度学习的机器唇读已经获得了突出地位。为此,已经提出了诸如LipNet,LCANet和其他几种体系结构,与在DCT特征上训练的传统唇形DNN HMM混合系统相比,其表现非常好。在这项工作中,我们提出了一个更简单的3D 2D CNN BLSTM网络架构,带有瓶颈层。我们还对这种架构的两种不同的唇读方法进行了分析。在第一种方法中,3D 2D CNN BLSTM网络在字符ch CTC上训练CTC丢失。然后,在传统的ASR训练管道中,从3D 2D CNN BLSTM ch CTC网络中提取的瓶颈唇部特征训练BLSTM HMM模型。在第二种方法中,相同的3D 2D CNN BLSTM网络在CTC上的字标签上训练CTC丢失。第一种方法表明,与DCT功能相比,瓶颈功能表现更好。使用Grid语料库中的第二种方法看到扬声器测试集,我们报告1.3 WER相对于LCANet有55改进。在看不见的扬声器测试装置上,我们报告了8.6 WER,相对于LipNet,这是24.5的改进。我们还在我们收集的81个扬声器的第二个数据集上验证了该方法。最后,我们还讨论了特征重复对BLSTM HMM模型性能的影响。 |
| Gray Level Image Threshold Using Neutrosophic Shannon Entropy Authors Vasile Patrascu 本文介绍了一种通过最小化香农中性熵来分割灰度图像的新方法。对于所提出的分割方法,中性信息分量,即真实度,中性程度和虚假程度是在考虑到属于分割区域并且同时考虑到分离阈值区域的情况下定义的。该方法的原理简单易懂,可导致多个阈值。使用一些测试灰度图像说明该方法的功效。实验结果表明,该方法具有良好的灰度阈值分割性能。 |
| Localizing Unseen Activities in Video via Image Query Authors Zhu Zhang, Zhou Zhao, Zhijie Lin, Jingkuan Song, Deng Cai 未修剪视频中的动作本地化是视频理解领域中的重要主题。但是,现有的动作本地化方法仅限于预先定义的一组动作,并且无法本地化看不见的活动。因此,我们考虑通过图像查询本地化视频中看不见的活动的新任务,命名为基于图像的活动本地化。该任务面临三个固有挑战:1如何消除图像查询中语义上不必要内容的影响2如何处理不准确图像查询的模糊定位3如何确定目标片段的精确边界。然后,我们提出了一种新颖的自我关注交互定位器,以端到端的方式检索看不见的活动。具体来说,我们首先设计一种具有相对位置编码的区域自我关注方法,以学习细粒度图像区域表示。然后,我们采用局部变压器编码器来构建图像和视频内容的多步融合和推理。我们接下来采用订单敏感的本地化程序来直接检索目标段。此外,我们通过重新组织ActivityNet数据集来构建新的数据集ActivityIBAL。大量实验表明了该方法的有效性。 |
| Teaching DNNs to design fast fashion Authors Abhianv Ravi, Arun Patro, Vikram Garg, Anoop Kolar Rajagopal, Aruna Rajan, Rajdeep Hazra Banerjee 快速时尚引领时尚界最大的破坏,使得能够设计弹性供应链,以快速响应不断变化的时尚潮流。商业制造中的传统设计过程通常通过世界各地的趋势或主流敷料模式来表示,这表明对于给定时间框架的新形式表达,循环模式和流行的表达模式的突然兴趣。在这项工作中,我们提出了一个全自动系统,通过设计具有社交媒体源生成的时间序列信号的服装的代表性原型,探索,检测并最终将时尚趋势综合到设计元素中。我们的系统设想是Fast Fashion设计的第一步,从设计开始到制造的服装生产周期旨在快速响应当前趋势。它还通过在设计生成时接受客户对可销售性的反馈来减少时装生产中的浪费。我们还提供了一个界面,其中设计师可以在时尚中使用多种趋势样式,并将设计可视化为这些样式元素的插值。我们的目标是通过为设计师创造有趣和鼓舞人心的组合来帮助创作过程,通过在关键客户中运行它们来考虑。 |
| Open-Ended Long-Form Video Question Answering via Hierarchical Convolutional Self-Attention Networks Authors Zhu Zhang, Zhou Zhao, Zhijie Lin, Jingkuan Song, Xiaofei He 开放式视频问答的目的是根据给定的问题从引用的视频内容中自动生成自然语言答案。目前,大多数现有方法关注于具有多模式重复编码器解码器网络的短格式视频问题应答。虽然这些作品已经取得了很好的表现,但由于缺乏远程依赖建模和巨大的计算成本,它们仍可能无法有效地应用于长视频视频问答。为了解决这些问题,我们提出了一种快速的分层卷积自注意编码器解码器网络HCSA。具体地说,我们首先开发一种分层卷积自注意编码器,以有效地对长格式视频内容进行建模,从而构建视频序列的层次结构,并从视频上下文中捕获问题感知的长距离依赖性。然后,我们设计了一个多尺度的注意力解码器,以结合用于答案生成的多层视频表示,这避免了顶部编码器层的信息丢失。大量实验表明了该方法的有效性和有效性。 |
| Place recognition in gardens by learning visual representations: data set and benchmark analysis Authors Maria Leyva Vallina, Nicola Strisciuglio, Nicolai Petkov 视觉位置识别是摄像机定位和循环闭合检测系统的重要组成部分。它涉及仅基于视觉线索识别先前访问过的地点。尽管对于室内和城市环境来说这是一个被广泛研究的问题,但由于花园般环境的挑战性外观,最近使用机器人来实现农业和园艺任务的自动化已经产生了新的问题。花园场景主要包含绿色,以及重复的图案和纹理。在花园和自然环境中记录的可用数据的缺乏使得视觉定位算法的改进变得困难。在本文中,我们提出了TB Places数据集的扩展版本,该数据集用于测试视觉位置识别的算法。它包含在不同季节的真实花园中记录的真实相机姿势的图像,具有不同的光线条件。我们为所有可能的图像对构建并发布了一个基本事实,表明它们是否描绘了相同的位置。我们提出了基于卷积神经网络的方法基准分析的结果,用于整体图像描述和位置识别。我们训练现有网络,即ResNet,DenseNet和VGG NetVLAD,作为具有对比损失功能的双向架构的骨干。我们获得的结果表明,学习园区定制的表示有助于提高性能,尽管泛化能力有限。 |
| Fully automatic computer-aided mass detection and segmentation via pseudo-color mammograms and Mask R-CNN Authors Hang Min, Devin Wilson, Yinhuang Huang, Samuel Kelly, Stuart Crozier, Andrew P Bradley, Shekhar S. Chandra 目的提出增强乳房X线照相质量的伪彩色乳房X线照片作为快速计算机辅助检测CAD系统的一部分,该系统可在无需任何用户干预的情况下同时检测和分割肿块。方法提出的伪彩色乳房X线照片,其三个通道包含原始灰度乳房X线照片和两个形态增强图像,用于为病变提供伪彩色对比。形态增强可以像乳房X线照相模式一样筛选质量,从而改善检测和分割。我们构建了一个快速,全自动的同步质量检测和分割CAD系统,使用彩色乳房X线照片作为转移学习的输入,使用Mask R CNN,这是一种先进的深度学习框架。这项工作的源代码已在线提供。结果在公开的乳腺X线摄影数据集INbreast上进行评估,该方法优于现有技术方法,通过在每个图像0.9假阳性和0.88的质量分割的平均Dice相似性指数达到0.90的平均真阳性率,同时花费20.4秒平均处理每个图像。结论该方法在不超过半分钟的情况下提供准确,全自动的乳房肿块检测和分割结果,无需任何用户干预,同时优于最先进的方法。 |
| A linear method for camera pair self-calibration and multi-view reconstruction with geometrically verified correspondences Authors Nikos Melanitis, Petros Maragos 我们在无序的未校准图像集中检查建筑场景的3D重建。我们引入线性方法进行自校准并找到相机对的度量重建。我们假设未知和不同的焦距,但是已知的内部相机参数和相机对的已知投影重建。我们在太空中恢复了两种可能的相机配置,并使用Cheirality条件,即所有3D场景点都位于两个相机的前面,以消除解决方案的歧义。我们在两个定理中展示,首先是两个解决方案处于镜像位置,然后是它们的观察方向之间的关系。我们的新方法使用标准方法Kruppa方程Delta R 3.77 circ进行自校准和5点算法进行相机中位数旋转误差Delta R 3.49 circ,用于相机对的校准度量重建。我们通过引入一种方法来检查错误的图像对应,以检查点对应是否沿着图像对中的x,y图像轴以相同的顺序出现。我们通过它的精确度和召回率来评估这种方法,并表明它提高了建筑和一般场景中点匹配的鲁棒性。最后,我们将所有引入的方法集成到3D重建管道中。我们利用旋转平均算法和平均焦距估计的新方法利用众多相机对度量重构。 |
| Background Subtraction using Adaptive Singular Value Decomposition Authors G nther Reitberger, Tomas Sauer 处理传感器数据时的一个重要任务是区分相关数据和不相关数据。本文描述了一种迭代奇异值分解的方法,该方法通过跨越图像空间子空间的奇异向量来维持背景模型,从而提供一种确定输入帧中包含的新信息量的方法。我们以计算有效的方式更新跨越背景空间的奇异向量,并提供执行块智能更新的能力,从而实现快速且稳健的自适应SVD计算。在定性和定量评估中都示出了这两种性质的效果以及整体方法在执行现有技术背景扣除方面的成功。 |
| ProtoNet: Learning from Web Data with Memory Authors Yi Tu, Li Niu, Dawei Cheng, Liqing Zhang 近年来,从网络数据中学习吸引了许多研究兴趣。然而,爬行的网络图像通常具有两种类型的噪声,标签噪声和背景噪声,这导致有效利用它们的额外困难。大多数现有方法要么依赖于人为监督,要么忽略背景噪声。在本文中,我们提出了新颖的ProtoNet,它能够一起处理这两种类型的噪声,而不需要在训练阶段监控干净的图像。特别是,我们使用内存模块来识别每个类别的代表性和判别性原型。然后,我们借助内存模块从Web数据集中删除噪声图像和噪声区域提议。我们的方法很有效,可以轻松集成到任意CNN模型中。对四个基准数据集的大量实验证明了我们方法的有效性。 |
| BTEL: A Binary Tree Encoding Approach for Visual Localization Authors Huu Le, Tuan Hoang, Michael Milford 由于相机技术和基于视觉的技术的最新进展,视觉定位算法已经在性能方面取得了显着的改进。然而,仍然存在一个关键的警告,基于图像检索的所有当前方法当前最大程度地与环境的大小线性地相关于存储,并且因此在大多数方法中,查询时间。这种限制严重削弱了自治系统在各种计算,功率,存储,尺寸,重量或成本受限应用(如无人机)中的能力。在这项工作中,我们提出了一种新的二叉树编码方法,用于视觉定位,可以作为现有量化和索引技术的替代方案。所提出的树结构允许我们导出压缩训练方案,该方案在所需存储和推理时间中实现子线性。可以容易地配置编码存储器以满足不同的存储约束。此外,我们的方法适用于可选的序列过滤机制,以进一步改善定位结果,同时保持相同的存储量。我们的系统与前端描述符完全无关,允许它在最新的最先进的图像表示之上使用。实验结果表明,该方法在有限的存储约束下明显优于现有技术方法。 |
| Convolution Based Spectral Partitioning Architecture for Hyperspectral Image Classification Authors Ringo S.W. Chu, Ho Cheung Ng, Xiwei Wang, Wayne Luk 高光谱图像HSI可以区分具有大量光谱带的材料,这在遥感应用中被广泛采用,并且在高精度土地覆盖分类中具有优势。然而,HSI处理与高维度和有限数量的标记数据的问题纠缠在一起。为了应对这些挑战,本文提出了一种深度学习架构,该架构使用三维卷积神经网络和谱分割来执行有效的特征提取。我们使用美国宇航局机载可见红外成像光谱仪获得的印度松树和萨利纳斯场景进行实验。与先前的结果相比,我们的架构显示了当前方法的分类结果的竞争性能。 |
| A Utility-Preserving GAN for Face Obscuration Authors Hanxiang Hao, David G era, Amy R. Reibman, Edward J. Delp 从电视新闻到谷歌街景,脸部蒙昧已被用于隐私保护。由于深度学习领域的最新进展,诸如高斯模糊和像素化之类的遮蔽方法不能保证隐藏身份。在本文中,我们提出了一种实用保留生成模型UP GAN,它能够提供有效的面部遮挡,同时保持面部效用。通过实用性保留,我们的意思是保留不显示身份的面部特征,例如年龄,性别,肤色,姿势和表情。我们表明,所提出的方法在遮蔽和实用性保存方面达到了最佳性能。 |
| Datasets for Face and Object Detection in Fisheye Images Authors Jianglin Fu, Ivan V. Bajic, Rodney G. Vaughan 我们提出了两个新的鱼眼图像数据集,用于训练面部和物体检测模型VOC 360和Wider 360.鱼眼图像是通过后处理从两个众所周知的数据集(VOC2012和Wider Face)收集的常规图像创建的,使用定期映射到鱼眼的模型在Matlab中实现的图像。 VOC 360包含39,575个鱼眼图像,用于物体检测,分割和分类。更广泛的360包含63,897个鱼眼图像用于面部检测。这些数据集将用于开发面部和物体检测器以及用于鱼眼图像的分割模块,同时正在努力收集和手动注释真实的鱼眼图像。 |
| Homography from two orientation- and scale-covariant features Authors Daniel Barath, Zuzana Kukelova 本文提出了角度和尺度的几何解释,其中定向和尺度协变特征检测器,例如, SIFT,提供。在比例和旋转上导出两个新的一般约束,可以在任何几何模型估计任务中使用。使用这些公式,引入了两个关于单应性估计的新约束。利用导出的方程,提出了用于从最小数量的两个对应关系估计单应性的求解器。此外,还示出了点对应的归一化如何影响旋转和比例参数,从而实现数值稳定的结果。由于仅需要两个特征对,所以可以使用稳健的估计器,例如,与使用四点算法相比,RANSAC的迭代次数要少得多。使用协变特征时,例如SIFT,有关比例和方向的信息是免费提供的。所提出的单应性估计方法在合成环境和公开可用的现实世界数据集中进行测试。 |
| Learning from Discovering: An unsupervised approach to Geographical Knowledge Discovery using street level and street network images Authors Stephen Law, Mateo Neira 最近的研究表明,机器学习方法在地理和城市分析中的使用越来越多,主要是从空间和时间数据中提取特征和模式。研究,将地理过程整合到机器学习模型中,利用地理信息来更好地解释这些方法的研究很少。这项研究有助于我们展示如何从无监督学习方法中学习的潜在变量可用于地理知识发现。特别是,我们提出了一种简单而新颖的方法,称为卷积PCA ConvPCA,它应用于街道和街道网络图像,找到一组不相关的视觉潜在响应。该方法允许使用地理和生成可视化的组合来探索潜在空间的有意义的解释,并且示出如何使用学习的嵌入来预测诸如街道级别封闭和街道网络密度的城市特征。 |
| Data Extraction from Charts via Single Deep Neural Network Authors Xiaoyi Liu, Diego Klabjan, Patrick NBless 从图表中自动提取数据具有挑战性,原因有两个,即图表中对象之间存在许多关系,这在一般计算机视觉问题中并不常见,并且不同类型的图表可能无法由同一模型处理。为了解决这些问题,我们提出了一个单一深度神经网络的框架,它由对象检测,文本识别和对象匹配模块组成。该框架处理条形图和饼图,并且还可以通过略微修改和扩充训练数据扩展到其他类型的图表。我们的模型在79.4的测试模拟条形图和88.0的测试模拟饼图上成功执行,而对于训练域之外的图表,它分别降低了57.5和62.3。 |
| A synthetic dataset for deep learning Authors Xinjie Lan 在本文中,我们提出了一种生成服从高斯分布的合成数据集的新方法。与具有未知分布的常用基准数据集相比,合成数据集具有明确的分布,即高斯分布。同时,它具有与基准数据集MNIST相同的特征。因此,我们可以轻松地在合成数据集上应用Deep Neural Networks DNN。该综合数据集提供了一种新的实验工具来验证所提出的深度学习理论。 |
| Effective degrees of freedom for surface finish defect detection and classification Authors Natalya Pya Arnqvist, Blaise Ngendangenzwa, Eric Lindahl, Leif Nilsson, Jun Yu 汽车工业中产品质量控制的主要问题之一是自动检测镜面车身表面上的小尺寸缺陷。针对特征提取和k近邻概率分类器的样条平滑方法,提出了一种新的表面完成缺陷检测统计学习方法。由于表面是镜面的,因此采用结构化闪电反射技术进行图像采集。降低的等级三次回归样条用于平滑像素值,而所获得的平滑的有效自由度用作特征向量的分量。该方法的一个关键优势是,当应用标准学习分类器时,它允许达到接近零的错误分类错误率。我们还提出基于概率的绩效评估指标作为传统指标的替代方案。这些的使用提供了用于分类器的预测性能的不确定性估计的手段。从位于瑞典Ume aa的沃尔沃GTO驾驶室工厂的试验系统获得的图像的实验分类结果表明,所提出的方法比比较方法更有效。 |
| Video Action Classification Using PredNet Authors Roshan Rane, Vageesh Saxena, Edit Sz gyi 在本文中,我们在Something something动作数据集上评估PredNet cite lotter16引用farzaneh18并实现PredNet,我们以多任务方式训练它以输出分类标签和预测。我们的想法是相互制定视频预测和行动分类。我们讨论了关于PredNet的一系列观察,并得出结论,它并不完全遵循预测编码框架的原则。 |
| Comparing Machine Learning Approaches for Table Recognition in Historical Register Books Authors St phane Clinchant, Herv D jean, Jean Luc Meunier, Eva Lang, Florian Kleber 我们在本文中提出了表格识别手册中的实验书籍。我们首先解释如何对行和列检测的问题进行建模,然后比较两种机器学习方法条件随机场和图形卷积网络来检测这些表元素。对Passau教区档案馆提供的死亡记录进行了评估。两种方法都显示相似的结果,89 F1得分,允许信息提取的质量。软件和数据集是开源数据。 |
| A database for face presentation attack using wax figure faces Authors Shan Jia, Chuanbo Hu, Guodong Guo, Zhengquan Xu 与2D面部呈现攻击相比,例如通过呈现3D特征或类似于真实面部的材料,3D打印照片和视频回放对于面部识别系统FRS来说更具挑战性。然而,现有的3D面部欺骗数据库主要基于3D掩模,由于生产困难和高成本而限于小数据大小或不良真实性。在这项工作中,我们引入了第一个蜡像人脸数据库WFFD,作为一种超现实的3D演示攻击来欺骗FRS。该数据库由2200张真实和蜡像面孔组成,共有4400张面孔,与在线收藏品有很大差异。该数据库的实验首先调查了三种流行的FRS对这种新攻击的脆弱性。此外,我们评估了几种面部呈现攻击检测方法的性能,以显示这种超逼真的面部欺骗数据库的攻击能力。 |
| Lidar based Detection and Classification of Pedestrians and Vehicles Using Machine Learning Methods Authors Farzad Shafiei Dizaji 本文的目的是将LiDAR传感器映射的对象分类为不同的类别,如车辆,行人和骑自行车的人。利用基于LiDAR的物体检测器和基于神经网络的分类器,基本上针对辅助自驾车辆识别和分类在驾驶过程中遇到的其他物体并且相应地进行,提出了一种新颖的实时物体检测。我们使用机器学习方法讨论我们的工作,以解决在自动驾驶汽车的机器学习应用中发现的常见高级问题,即从3D LiDAR传感器获得的pointcloud数据的分类。 |
| InsectUp: Crowdsourcing Insect Observations to Assess Demographic Shifts and Improve Classification Authors L onard Boussioux, Tom s Giro Larraz, Charles Guille Escuret, Mehdi Cherti, Bal zs K gl 昆虫在生态系统中发挥着如此重要的作用,即少数物种的人口变化会对环境,社会和经济层面产生破坏性后果。尽管如此,昆虫人口统计学的评估受到以足够规模收集人口普查数据的困难的严重限制。我们提出了一种方法来收集和利用旁观者,徒步旅行者和昆虫学爱好者的观察结果,以便为研究人员提供可以显着帮助预测和识别环境威胁的数据。最后,我们表明双方确实对这种合作感兴趣。 |
| On Physical Adversarial Patches for Object Detection Authors Mark Lee, Zico Kolter 在本文中,我们展示了针对物体探测器的物理对抗性补丁攻击,尤其是YOLOv3探测器。与先前关于物理对象检测攻击的工作不同,后者要求补丁与被错误分类的对象重叠或避免检测,我们表明正确设计的补丁几乎可以抑制图像中所有检测到的对象。也就是说,我们可以将贴片放置在图像中的任何位置,导致图像中的所有现有对象完全被探测器遗漏,即使远离贴片本身也是如此。这反过来又开启了针对物体检测系统的新线路物理攻击,这些物理攻击不需要修改场景中的物体。可以在以下位置找到该系统的演示 |
| Classifying logistic vehicles in cities using Deep learning Authors Salma Benslimane, Simon Tamayo CAOR , Arnaud de La Fortelle CAOR 由于运输卡车和轻型商用车辆的使用正在发展,因此城市地区的交付和货运的快速增长正在增加。主要城市可以使用交通计数作为监控运载工具存在的工具,以实施智能城市规划措施。用于计数车辆的传统方法使用机械,电磁或气动传感器,但是这些装置昂贵,难以实施并且仅在不提供关于其类别,模型或轨迹的信息的情况下检测车辆的存在。本文提出了一种深度学习工具,用于在考虑不同类别的物流车辆(即轻型,中型和重型车辆)的同时对给定图像中的车辆进行分类。所提出的方法产生了两个主要贡献,首先我们开发了一个架构来创建一个注释和平衡的物流车辆数据库,减少了手动注释工作。其次,我们建立了一个分类器,可以准确地对通过给定道路的物流车辆进行分类。这项工作的结果首先是一个包含4个车辆类别的72 000个图像的数据库和第二个2个重新训练的卷积神经网络InceptionV3和MobileNetV2,能够对精度超过90的车辆进行分类。 |
| Labeling, Cutting, Grouping: an Efficient Text Line Segmentation Method for Medieval Manuscripts Authors Michele Alberti, Lars Voe gtlin, Vinaychandran Pondenkandath, Mathias Seuret, Rolf Ingold, Marcus Liwicki 本文介绍了一种基于深度学习的预分类和最新分割方法的文本行提取方法。复杂手写文档中的文本行提取对于最现代的计算机视觉算法提出了重大挑战。历史手稿是一类特别难以处理的文件,因为它们呈现出几种形式的噪音,例如降解,渗透,线性光泽和精心制作的文字。在这项工作中,我们提出了一种新的方法,它使用像素级的语义分割作为中间任务,然后是文本行提取步骤。我们在最近的挑战中世纪手稿的数据集上测量了我们的方法的性能,并通过将误差减少80.7来超越最先进的结果。此外,我们证明了我们的方法在用不同脚本编写的各种其他数据集上的有效性。因此,我们的贡献是两倍。首先,我们证明语义像素分割可以在执行文本行提取之前用作强去噪预处理步骤。其次,我们介绍了一种新颖,简单而强大的算法,该算法利用高质量的语义分段,在具有挑战性的数据集上实现99.42行IU的文本行提取性能。 |
| HalalNet: A Deep Neural Network that Classifies the Halalness Slaughtered Chicken from their Images Authors A. Elfakharany, R. Yusof, N. Ismail, R. Arfa, M. Yunus 食品中的清真要求对全世界数百万穆斯林来说非常重要,尤其是肉类和鸡肉产品,确保屠宰场遵守这一要求是一项具有挑战性的手工任务。在本文中,提出了一种方法,该方法使用摄像机在屠宰场的传送带上拍摄屠宰鸡的图像,然后通过深度神经网络分析图像,以分类图像是否是清真屠宰的鸡。然而,传统的深度学习模型需要大量的数据进行训练,在这种情况下,这些数据量很难收集特别是非清真屠宰鸡的图像,因此本文展示了如何使用一次性学习1和转移学习2可以在少量可用数据上达到高精度。所使用的体系结构基于Siamese神经网络体系结构,该体系结构对两个输入3之间的相似性进行排序,同时使用Xception网络4作为双网络。我们称之为HalalNet。这项工作是作为符合SYCUT syriah标准的屠宰系统的一部分完成的,该系统是一个监测系统,监测屠宰场屠宰鸡的清真度。用于培训和验证HalalNet的数据来自马来西亚雪兰莪的Azain屠宰场Semenyih,其中包含清真和非清真屠宰鸡的图像。 |
| Fine-grained zero-shot recognition with metric rescaling Authors Boris N. Oreshkin, Negar Rostamzadeh, Pedro O. Pinheiro, Christopher Pal 我们解决了学习细粒度交叉模态表示的问题。我们在联合视觉和文本空间中提出了基于实例的深度量学习方法。最重要的是,我们推导出一种度量重新缩放方法,它解决了广义零镜头学习设置中的一个非常常见的问题,即将来自看不见的类的测试图像分类为训练期间看到的类之一。我们在两个细粒度零射击学习数据集CUB和FLOWERS上评估我们的方法。我们发现,在广义零射击分类任务中,所提出的方法始终优于两个数据集上的现有方法。我们证明了所提出的方法,尽管其实施和培训简单,但优于我们所知的使用相同评估框架的所有最新技术方法。 |
| Characterizing Bias in Classifiers using Generative Models Authors Daniel McDuff, Shuang Ma, Yale Song, Ashish Kapoor 从现实世界数据中学习的模型通常是有偏见的,因为用于训练它们的数据是有偏见的。这可以传播存在的系统性人类偏见,并最终导致对人,特别是少数民族的不公平待遇。为了表征学习分类器中的偏差,现有方法依赖于人类神谕标记真实世界的例子来识别分类器的盲点,这些盲点由于所需的人工劳动和现有图像示例的有限性而最终受限。我们提出了一种基于模拟的方法,用于以系统的方式使用生成对抗模型来询问分类器。我们采用渐进式条件生成模型来合成照片逼真的面部图像和贝叶斯优化,以有效地查询独立的面部图像分类系统。我们展示了如何使用这种方法有效地表征商业系统中的种族和性别偏见。 |
| Deep Eyedentification: Biometric Identification using Micro-Movements of the Eye Authors Lena A. J ger, Silvia Makowski, Paul Prasse, Sascha Liehr, Maximilian Seidler, Tobias Scheffer 我们研究眼睛的无意识微动作以进行生物识别。虽然先前的研究从基于视频的眼睛跟踪系统的输出中提取较低频率的宏观运动并且设计这些宏观运动的显式特征,但是我们开发了一种处理原始眼睛跟踪信号的深度卷积结构。与先前的工作相比,网络的误码率降低了一个数量级,并且速度提高了两个数量级,可在几秒内准确识别用户。 |
| Coloring With Limited Data: Few-Shot Colorization via Memory-Augmented Networks Authors Seungjoo Yoo, Hyojin Bahng, Sunghyo Chung, Junsoo Lee, Jaehyuk Chang, Jaegul Choo 尽管最近在基于深度学习的自动着色方面取得了进步,但是当涉及到很少的镜头学习时,它们仍然是有限的。现有模型需要大量的训练数据。为了解决这个问题,我们提出了一种新颖的记忆增强色彩模型MemoPainter,它可以用有限的数据产生高质量的色彩。特别是,我们的模型能够捕获罕见的实例并成功着色它们。我们还提出了一种新的阈值三重态丢失,它可以在不需要类标签的情况下实现对存储器网络的无监督训练。实验表明,我们的模型在少量镜头和一次镜片着色任务中都具有卓越的品质。 |
| A Preliminary Study on Data Augmentation of Deep Learning for Image Classification Authors Benlin Hu, Cheng Lei, Dong Wang, Shu Zhang, Zhenyu Chen 深度学习模型具有大量的自由参数,需要通过对大量训练数据的模型进行有效训练来计算,以提高其泛化性能。然而,数据获取和标记在实践中是昂贵的。数据增加是缓解此问题的方法之一。在本文中,我们对三种变量增强方法,每个标签基本数据集的增大率和大小如何影响图像分类深度学习的准确性进行了初步研究。该研究提供了一些指导方针1,最好使用改变图像几何形状的转换,而不是那些只是照明和颜色的转换。 2 2 3倍的增强率足以进行训练。 3数据量越小,贡献就越明显。 |
| Traffic Light Recognition Using Deep Learning and Prior Maps for Autonomous Cars Authors Lucas C. Possatti, R nik Guidolini, Vinicius B. Cardoso, Rodrigo F. Berriel, Thiago M. Paix o, Claudine Badue, Alberto F. De Souza, Thiago Oliveira Santos 自主地面车辆必须能够感知交通灯并识别其当前状态以与人类驾驶员共享街道。大多数时候,人类驾驶员可以轻松识别相关的交通灯。为了解决这个问题,自动驾驶汽车的通用解决方案是将识别与先前的地图集成。然而,需要额外的解决方案来检测和识别交通信号灯。深度学习技术表现出很强的性能和泛化能力,包括与交通相关的问题。在深度学习的进步的推动下,一些最近的作品利用一些最先进的深度探测器来定位和进一步识别来自2D相机图像的交通灯。然而,它们都没有将基于深度学习的探测器的功率与先前的地图结合以识别相关交通灯的状态。在此基础上,这项工作提出将基于深度学习的检测功能与我们的汽车平台IARA首字母缩略词用于智能自主机器人汽车的先前地图相结合,以识别预定路线的相关交通信号灯。该过程分为两个阶段:地图构建和交通灯注释的离线阶段和交通灯识别和相关识别的在线阶段。拟议的系统在Vit ria市的五个测试案例路线上进行了评估,每个案例由视频序列和先前的地图组成,其中包含该路线的相关交通灯。结果表明,该技术能够正确识别沿轨迹的相关交通灯。 |
| Robust Classification with Sparse Representation Fusion on Diverse Data Subsets Authors Chun Mei Feng, Yong Xu, Zuoyong Li, Jian Yang 稀疏表示SR技术将测试样本编码为所有训练样本的稀疏线性组合,然后将测试样本分类为具有最小残差的类。 SR技术的分类取决于测试样本的表示能力。然而,这些模型中的大多数将测试样本的表示问题视为确定性问题,忽略了表示的不确定性。不确定性是由两个因素引起的,即样本中的随机噪声和样本集的内在随机性,这意味着如果我们捕获一组样本,所获得的样本集将在不同条件下不同。在本文中,我们提出了一种基于协同表示的新方法,它是SR的一个特殊实例,具有封闭形式的解决方案。它基于训练样本SRFDS的多样子集执行稀疏表示融合,减少了样本集随机性的影响,提高了分类结果的鲁棒性。所提出的方法适用于多种类型的数据,并且不需要任务的模式类型。此外,SRFDS不仅可以保留封闭形式的解决方案,还可以大大提高分类性能。各种数据集的有希望的结果可以作为SRFDS比其他基于SR的方法更好的性能的证据。可以访问SRFDS的Matlab代码 |
| Identifying Emotions from Walking using Affective and Deep Features Authors Tanmay Randhavane, Aniket Bera, Kyra Kapsaskis, Uttaran Bhattacharya, Kurt Gray, Dinesh Manocha 我们提出了一种新的数据驱动模型和算法,以根据他们的行走方式识别个体的感知情绪。给定个人行走的RGB视频,我们以一系列3D姿势的形式提取他的步行步态。我们的目标是利用步态特征将人类的情绪状态分为快乐,悲伤,愤怒或中立的四种情绪之一。我们的感知情绪识别方法基于使用通过LSTM在标记的情感数据集上学习的深层特征。此外,我们将这些特征与使用姿势和运动线索从步态计算出的情感特征相结合。使用随机森林分类器对这些特征进行分类。我们表明,我们在组合特征空间和感知情绪状态之间的映射在识别感知情绪方面提供了80.07的准确性。除了对离散的情绪类别进行分类之外,我们的算法还可以根据步态预测感知效价和觉醒的价值。我们还提供了一个EWalk Emotion Walk数据集,其中包含步态个体的步态和标记情绪的视频。据我们所知,这是第一个基于步态的模型,用于识别行走个体视频中的感知情绪。 |
| Unsupervised Learning of Object Keypoints for Perception and Control Authors Tejas Kulkarni, Ankush Gupta, Catalin Ionescu, Sebastian Borgeaud, Malcolm Reynolds, Andrew Zisserman, Volodymyr Mnih 计算机视觉中对象表示的研究主要集中在开发对图像分类,对象检测或语义分割有用的表示作为下游任务。在这项工作中,我们的目标是学习对控制和强化学习RL有用的对象表示。为此,我们引入了Transporter,一种神经网络架构,用于根据关键点或图像空间坐标发现简洁的几何对象表示。我们的方法通过使用关键点瓶颈在视频帧之间传输学习的图像特征,以完全无监督的方式从原始视频帧中学习。发现的关键点比最近的类似方法更准确地跟踪长时间视野中的对象和对象部分。此外,一致的长期跟踪使得控制域1中的两个显着结果使用关键点坐标和相应的图像特征作为输入使得高度样本有效的强化学习2通过控制关键点位置来学习探索大大减少了搜索空间,从而实现深入探索通过随机行动探索无法获得的状态,没有任何外在奖励。 |
| Explicit Disentanglement of Appearance and Perspective in Generative Models Authors Nicki Skafte Detlefsen, S ren Hauberg 解缠结的表示学习发现紧凑,独立且易于解释的数据因素。已经证明学习这样的需要归纳偏差,我们在图像的生成模型中明确地编码。具体来说,我们提出了一个带有两个潜在空间的模型,一个表示输入数据的空间变换,另一个表示变换后的数据。我们发现后者自然地捕获了数据的内在外观。为了实现生成模型,我们提出了一种变分推断的变换自动编码器VITAE,它将空间变换器结合到变分自动编码器中。我们展示了如何通过仔细设计编码器并将转换类限制为微分同构来有效地在模型中进行推理。根据经验,我们的模型将视觉风格与MNIST上的数字类型分开,并分离人体图像中的形状和姿势。 |
| Style Generator Inversion for Image Enhancement and Animation Authors Aviv Gabbay, Yedid Hoshen 培养高质量图像生成模型的主要动机之一是它们作为图像处理工具的潜在用途。最近,生成对抗性网络GAN已经能够生成具有显着质量的图像。不幸的是,经过对侧训练的无条件发电机网络作为图像先验并不成功。网络作为生成图像之前的主要要求之一是能够从目标分布生成每个可能的图像。对抗性学习经常会出现模式崩溃,这表现在无法生成某些目标分布模式的生成器中。通常不满足的另一个要求是可逆性,即在给定所需输出图像的情况下具有找到有效输入潜码的有效方式。在这项工作中,我们表明,与早期的GAN不同,最近提出的样式生成器很容易反转。我们使用这个重要的观察来提出样式生成器作为通用图像先验。我们展示了样式生成器优于其他GAN以及Deep Image Prior作为图像增强任务的先驱。由样式生成器跨越的潜在空间满足线性身份姿势关系。潜在的空间线性与可逆性相结合,使我们能够在没有监督的情况下为静止的面部图像制作动画。进行了大量实验以支持本文的主要贡献。 |
| Comparing Energy Efficiency of CPU, GPU and FPGA Implementations for Vision Kernels Authors Murad Qasaimeh, Kristof Denolf, Jack Lo, Kees Vissers, Joseph Zambreno, Phillip H. Jones 开发高性能嵌入式视觉应用程序需要平衡运行时性能和能量限制。鉴于存在用于嵌入式计算机视觉的硬件加速器的混合,例如多核CPU,GPU和FPGA及其相关的供应商优化视觉库,开发人员在这个分散的解决方案空间中进行导航成为一项挑战。为了帮助确定哪种嵌入式平台最适合其应用,我们对各种视觉内核的运行时性能和能效进行了全面的基准测试。我们讨论了为什么给定的底层硬件架构根据一系列视觉内核类别的特性天生地表现良好或不良的原理。具体来说,我们的研究是针对嵌入式视觉应用ARM57 CPU,Jetson TX2 GPU和ZCU102 FPGA的三种常用硬件加速器,使用其供应商优化的视觉库OpenCV,VisionWorks和xfOpenCV。我们的结果表明,与简单内核的GPU相比,GPU的能量帧减少率为1.1 3.2倍。对于更复杂的内核和完整的视觉流水线,FPGA的能量帧缩减率为1.2 22.3x,优于其他FPGA。还观察到随着视觉应用的管道复杂性的增加,FPGA的性能越来越好。 |
| Deep Learning-Based Classification Of the Defective Pistachios Via Deep Autoencoder Neural Networks Authors Mehdi Abbaszadeh, Aliakbar Rahimifard, Mohammadali Eftekhari, Hossein Ghayoumi Zadeh, Ali Fayazi, Ali Dini, Mostafa Danaeian 开心果主要以生食,盐腌或烤制的形式食用,因为它具有高营养特性和良好的口感。具有壳和核缺陷的开心果除了不被消费者接受外,还易于受到昆虫损害,霉菌腐烂和黄曲霉毒素污染。在这项研究中,开发了一种基于深度学习的成像算法来改进坚果的分类,其中壳和核缺陷表明黄曲霉毒素污染的风险,例如深色污渍,油性污渍,粘附的船体,真菌腐烂和曲霉菌。本文提出了一种基于深度自动编码器神经网络对缺陷和令人不快的开心果进行分类的无监督学习方法。在验证数据集上对设计的神经网络进行测试表明,具有深色斑点,油性污渍或粘附的船体,精度为80.3的坚果可以与普通坚果区分开来。由于大学HPC的内存有限,结果是合理且合理的。 |
| Making CNNs for Video Parsing Accessible Authors Zijin Luo, Matthew Guzdial, Mark Riedl 为高分辨率电子竞技游戏提取游戏事件序列的能力传统上需要访问游戏引擎。这对于不具备此访问权限的团体来说是一个障碍。可以应用深度学习从游戏视频中导出这些日志,但它需要计算能力作为额外的障碍。这些小组将受益于访问这些日志,例如小型电子竞技比赛组织者,他们可以更好地可视化游戏玩法,以通知观众和评论员。在本文中,我们提出了一种组合解决方案,以减少所需的计算资源和时间来应用卷积神经网络CNN从电子游戏视频中提取事件。该解决方案包括更快地训练CNN的技术和更快地执行预测的方法。这扩展了能够训练和运行这些模型的机器类型,从而扩展了使用这种方法提取游戏日志的访问权限。我们评估DOTA2领域的方法,DOTA2是最受欢迎的电子竞技项目之一。我们的结果表明我们的方法优于标准的反向传播基线。 |
| Uncertainty Based Detection and Relabeling of Noisy Image Labels Authors Jan M.K hler, Maximilian Autenrieth, William H. Beluch 深度神经网络DNN是计算机视觉任务中的强大工具。然而,在许多现实场景中,标签噪声在训练图像中是普遍的,并且过度拟合这些噪声标签会显着损害DNN的泛化性能。我们提出了一种新技术,用于根据来自DNN的预测不确定性对清洁和噪声数据的不同分布来识别具有噪声标签的数据。另外,在训练过程中不确定性的行为有助于识别最佳可用于重新标记噪声标签的网络权重。因此,可以在迭代过程中清洁具有噪声标签的数据。我们提出的方法可以很容易地实现,并且在CIFAR 10和CIFAR 100上的噪声标签检测任务上表现出很好的性能。 |
| Team JL Solution to Google Landmark Recognition 2019 Authors Yinzheng Gu, Chuanpeng Li 在本文中,我们描述了我们在Kaggle上举行的Google Landmark Recognition 2019挑战赛的解决方案。由于大量的类,噪声数据,不平衡的类大小以及测试集中存在大量干扰物,我们的方法主要基于具有全局和本地CNN方法的检索技术。在对模型进行整合并应用几个重新排名策略后,我们的完整渠道在私人排行榜上获得0.37606 GAP,赢得了比赛的第一名。 |
| VolMap: A Real-time Model for Semantic Segmentation of a LiDAR surrounding view Authors Hager Radi, Waleed Ali 本文介绍了VolMap,一种用于自动驾驶车辆中3D LiDAR环绕视图系统语义分割的实时方法。我们设计了一个优化的深度卷积神经网络,可以精确地分割由360度LiDAR设置产生的点云,其中输入包括体积鸟瞰图,其中LiDAR高度层用作输入通道。我们进一步研究了多LiDAR设置的使用及其对语义分割任务性能的影响。我们的评估是在包含LiDAR茧设置和KITTI数据集的大规模3D物体检测基准上进行的,其中每点分割标签来自3D边界框。我们证明了VolMap在CPU的高精度和实时运行之间取得了很好的平衡。 |
| Using Self-Supervised Learning Can Improve Model Robustness and Uncertainty Authors Dan Hendrycks, Mantas Mazeika, Saurav Kadavath, Dawn Song 自我监督为下游任务提供有效的表示,无需标签。然而,现有方法落后于完全监督的训练,并且除了避免注释的需要之外通常不被认为是有益的。我们发现自我监督可以通过各种方式获得稳健性,包括对抗性示例的稳健性,标签损坏和常见的输入损坏。此外,自我监督极大地有利于在困难的近分布异常值上进行分布检测,以至于它超出了完全监督方法的性能。这些结果表明,自我监督有望提高稳健性和不确定性评估,并将这些任务建立为未来自我监督学习研究的新评估轴。 |
| Modelling Airway Geometry as Stock Market Data using Bayesian Changepoint Detection Authors Kin Quan, Ryutaro Tanno, Michael Duong, Arjun Nair, Rebecca Shipley, Mark Jones, Christopher Brereton, John Hurst, David Hawkes, Joseph Jacob 许多肺部疾病,例如特发性肺纤维化IPF,表现出气道扩张。准确测量扩张能够评估疾病的进展。不幸的是,图像噪声和气道分叉的组合导致横截面区域的轮廓的高度可变性,使得对受影响区域的识别非常困难。在这里,我们介绍了一种噪声鲁棒方法,用于在不同时间点获得同一气道的两个轮廓,自动检测进行性气道扩张的位置。我们提出了概率之间突然相对变化的概率模型,并通过可逆跳跃马尔可夫链蒙特卡罗采样进行推理。我们证明了所提出的方法对健康气道图像的两个数据集的有效性,模拟扩张ii对以1年为间隔获得的IPF影响气道的实际图像。我们的模型能够在模拟数据上检测气道扩张的起始位置,精确度为2.5mm。 IPF数据集上的实验显示与放射科医师的合理协议。我们可以计算气道容积的相对变化,这可能有助于量化IPF疾病进展。 |
| Adversarial optimization for joint registration and segmentation in prostate CT radiotherapy Authors Mohamed S. Elmahdy, Jelmer M. Wolterink, Hessam Sokooti, Ivana I gum, Marius Staring 联合图像配准和分割一直是医学成像研究的一个活跃领域。在这里,我们使用对抗性学习在深度学习环境中重新解决这个问题。我们考虑固定和移动图像及其分割可用于训练的情况,而在测试放射治疗中的常见情况期间无法进行分割。所提出的框架包括3D端到端生成器网络,其以无监督的方式估计固定和运动图像之间的变形矢量场DVF,并将该DVF应用于运动图像及其分割。训练鉴别器网络以评估运动图像和分割与固定图像和分割的对齐程度。对用于图像引导放射治疗的后续前列腺CT扫描训练和评估所提出的网络,其中使用估计的DVF将计划CT轮廓传播到每日CT图像。与使用texttt elastix的常规配准进行定量比较表明,所提出的方法提高了性能并大大缩短了计算时间,从而实现了在线自适应放射治疗所需的实时轮廓传播。 |
| Accurate Retinal Vessel Segmentation via Octave Convolution Neural Network Authors Zhun Fan, Jiajie Mo, Benzhang Qiu 视网膜血管分割是诊断和筛查各种疾病(包括糖尿病,眼科疾病和心血管疾病)的关键步骤。在本文中,我们提出了一种有效的方法,使用基于编码器解码器的倍频程卷积网络对彩色眼底图像进行精确的血管分割。与利用香草卷积进行特征提取的其他基于卷积网络的方法相比,该方法采用倍频程卷积进行多个空间频率特征学习,从而可以更好地捕获不同大小和形状的视网膜脉管系统。我们凭经验证明低频核的特征图响应于主要的血管树,而高频特征图可以更好地捕获低对比度细血管的微小细节。为了提供学习如何解码多频特征的网络能力,我们扩展了八度音程卷积,并提出了一种新的操作,称为八度转置卷积,采用相同的多频方法。我们还提出了一种基于编码器解码器的新型完全卷积网络,称为Octave UNet,可在单前向馈送中生成高分辨率的血管分割。所提出的方法在四个公开可用的数据集DRIVE,STARE,CHASE DB1和HRF数据集上进行评估。大量实验结果表明,所提出的方法以最快的处理速度实现了对现有技术方法的更好或兼容的性能。 |
| Densely Residual Laplacian Super-Resolution Authors Saeed Anwar, Nick Barnes 超分辨率卷积神经网络最近证明了单个图像的高质量恢复。然而,现有算法通常需要非常深的架构和长的训练时间。此外,目前用于超分辨率的卷积神经网络无法利用多个尺度的特征并对它们进行相同的权衡,从而限制了它们的学习能力。在本次论述中,我们提出了一种紧凑而精确的超分辨率算法,即密集残差拉普拉斯网络DRLN。所提出的网络在残余结构上采用级联残差,以允许低频信息的流动集中于学习高级和中级特征。此外,通过密集连接的残差块设置实现深度监督,这也有助于从高级复杂特征中学习。此外,我们建议拉普拉斯注意模拟关键特征,以了解特征图之间的层间和层内依赖关系。对低分辨率,噪声低分辨率和真实历史图像基准数据集的全面定量和定性评估表明,我们的DRLN算法在视觉和准确方面对最先进的方法表现出良好的效果。 |
| Studying the Impact of Mood on Identifying Smartphone Users Authors Khadija Zanna, Sayde King, Tempestt Neal, Shaun Canavan 本文探讨了当受试者感到快乐,心烦或压力不足或存在时收集某些样本时智能手机用户的识别。我们使用StudentLife数据集收集了来自19个受试者的数据,该数据集是达特茅斯学院研究人员收集的数据集,最初收集该数据集是为了将智能手机使用模式所表现的行为与压力和学习成绩的变化相关联。虽然许多先前关于行为生物特征识别的研究表明情绪是人体内变异的来源,这可能影响生物特征表现,但我们的结果与这一假设相矛盾。我们的研究结果表明,当移除受试者可能感到快乐,不安或压力时产生的样本时,性能会恶化。因此,没有迹象表明情绪会对表现产生负面影响。但是,我们发现智能手机使用模式中存在的变化可能与情绪有关,包括锁定,音频,位置,呼叫,主屏幕和电子邮件习惯的变化。因此,我们表明虽然情绪是人内变异的来源,但生物识别系统尤其是移动生物识别可能受情绪影响可能是不准确的假设。 |
| Supervise Thyself: Examining Self-Supervised Representations in Interactive Environments Authors Evan Racah, Christopher Pal 自我监督的方法,其中代理仅通过观察其动作的结果来学习表示,在不提供密集的奖励信号或具有标签的环境中变得至关重要。在大多数情况下,这些方法用于下游任务的预训练或辅助任务,例如控制,探索或模仿学习。但是,不清楚哪种方法的表示最能捕获环境的有意义的特征,哪种方法最适合哪种类型的环境。我们在两个视觉环境Flappy Bird和Sonic The Hedgehog上展示了一个关于自我监督方法的小规模研究。特别地,我们在两个上下文中定量地评估从这些任务中学习的表示,表示方式捕获代理的真实状态信息的程度以及这些表示对新情况(例如新级别和纹理)的一般化。最后,我们通过可视化他们关注的环境部分来评估这些自我监督的功能。我们的结果表明,表示的效用高度依赖于环境的视觉和动态。 |
| HEMELB Acceleration and Visualization for Cerebral Aneurysms Authors Sahar Soheilian Esfahani, Xiaojun Zhai, Minsi Chen, Abbes Amira, Faycal Bensaali, Julien AbiNahed, Sarada Dakua, Georges Younes, Robin A. Richardson, Peter V. Coveney 导致血管扩张或膨胀的脑动脉壁的弱点被称为脑动脉瘤。最佳治疗需要快速准确地诊断动脉瘤。 HemeLB是一种用于复杂几何形状的流体动力学求解器,用于为神经外科医生提供与动脉瘤内和周围血液流动相关的信息。在具有成本效益的平台上,HemeLB可以在医院中使用,以便为外科医生提供实时的模拟结果。在这项工作中,我们开发了一个改进版的HemeLB,用于GPU实现和结果可视化。还提供了一个可视化平台,用于与最终用户的顺畅交互。最后,报告了对该实施的综合评估。结果表明,所提出的实施方案实现了每秒15,168,964次站点更新的最大性能,并且能够加速HemeLB在医院和临床调查中的部署。 |
| A New Compensatory Genetic Algorithm-Based Method for Effective Compressed Multi-function Convolutional Neural Network Model Selection with Multi-Objective Optimization Authors Luna M. Zhang 近年来,已经出现了许多流行的卷积神经网络CNN,例如Google的Inception V4,它们在各种图像分类问题上表现得非常好。这些常用的CNN模型通常对卷积层中的所有神经元使用相同的激活函数,例如RELU,它们是单功能CNN。但是,SCNN可能并不总是最佳的。因此,已经证明,对于不同神经元使用不同激活函数的多功能CNN MCNN优于SCNN。此外,CNN通常具有非常大的架构,其使用大量存储器并且需要大量数据以便被良好地训练。因此,他们往往也有很高的培训和预测时间。一个重要的研究问题是如何自动有效地找到具有高分类性能和紧凑架构的最佳CNN,具有高训练和预测速度,小功率使用和小内存大小,适用于任何图像分类问题。从大量候选MCNN中智能地找到有效,快速,节能且存储有效的压缩多功能CNN CMCNN非常有用。利用新的遗传算法GA创建了一种新的补偿算法,以找到最佳的CMCNN,并在性能和体系结构尺寸之间进行理想的补偿。最佳的CMCNN具有最佳性能和最小的架构尺寸。使用CIFAR10数据集的模拟显示,新的补偿算法可以找到在分类性能F1得分,速度,功率使用和内存使用方面优于非压缩MCNN的CMCNN。基于流行的CNN架构的其他有效,快速,高效且节省内存的CMCNN将被开发用于重要的现实世界应用中的图像分类问题,例如脑信息学和生物医学成像。 |
| DVDnet: A Fast Network for Deep Video Denoising Authors Matias Tassano, Julie Delon, Thomas Veit 在本文中,我们提出了一种基于卷积神经网络架构的最先进的视频去噪算法。先前基于神经网络的视频去噪方法不成功,因为它们的性能不能与基于补丁的方法的性能竞争。但是,我们的方法在显着降低计算时间方面优于其他基于补丁的竞争对手。与其他现有的神经网络降噪器相比,我们的算法具有多种理想的特性,例如较小的内存占用,以及使用单一网络模型处理各种噪声级别的能力。它的去噪性能和较低的计算负荷之间的结合使得该算法对于实际的去噪应用具有吸引力。我们将我们的方法与不同的现有算法进行比较,包括视觉和客观质量指标。实验表明,我们的算法与其他现有技术方法相比具有优势。视频示例,代码和模型可在网址上公开获取 |
| From Data Quality to Model Quality: an Exploratory Study on Deep Learning Authors Tianxing He, Shengcheng Yu, Ziyuan Wang, Jieqiong Li, Zhenyu Chen 如今,人们努力提高深度学习模型的准确性。但是,很少有工作集中在数据集的质量上。实际上,数据质量决定了模型质量。因此,研究数据质量如何影响模型质量对我们来说非常重要。在本文中,我们主要考虑数据质量的四个方面,包括数据集均衡,数据集大小,标签质量,数据集污染。我们设计了MNIST和Cifar 10的实验,并试图找出这四个方面对模型质量的影响。实验结果表明,四个方面都对模型质量起决定性作用。这意味着这些方面的数据质量下降会降低模型的准确性。 |
| Instant automatic diagnosis of diabetic retinopathy Authors Gwenol Quellec, Mathieu Lamard, Bruno Lay, Alexandre Le Guilcher, Ali Erginay, B atrice Cochener, Pascale Massin 本研究的目的是评估OphtAI系统的性能,用于自动检测可诱发的糖尿病视网膜病变DR和使用彩色眼底照相自动评估DR严重程度。 OphtAI依赖于训练的卷积神经网络的集合,以识别眼睛偏侧性,检测可参考的DR并评估DR严重性。系统可以处理单个图像或完整的检查记录。为了记录自动诊断,产生准确的热图。该系统使用来自OPHDIAT筛查程序的164,660个筛选程序的763,848个图像的数据集开发和验证。为了进行比较,还在公共Messidor 2数据集中对其进行了评估。使用爱荷华大学的参考标准95 CI 0.984 0.994,可以在Messidor 2数据集中使用AUC 0.989的ROC曲线下面积检测相关DR。这明显优于FDA授权的唯一AI系统,在完全相同的条件下进行评估AUC 0.980。 OphtAI还可以检测威胁视力的DR,其AUC为0.997 95 CI 0.996 0.998,增殖性DR的AUC为0.997 95 CI 0.995 0.999。系统使用图形处理单元在0.3秒内运行,不到2秒即可运行。 OphtAI比目前FDA授权的唯一AI系统更安全,更快速,更全面。现在可以进行即时DR诊断,这有望简化DR筛查并为更多糖尿病患者提供DR筛查的便捷途径。 |
| The Impact of an Inter-rater Bias on Neural Network Training Authors Or Shwartzman, Harel Gazit, Ilan Shelef, Tammy Riklin Raviv 通常在医学图像的手动标记的背景下讨论了评价者间变异性的问题。假设被基于自动模型的图像分割方法绕过,这被认为是客观的,提供单一的,确定性的解决方案。然而,诸如深度神经网络DNN之类的数据驱动方法的出现及其在监督语义分割中的应用使得评估者对这一问题的分歧回到了前面阶段。在本文中,我们强调了评估者间偏差的问题,而不是随机的观察者间变异性,并证明了它对DNN训练的影响,导致相同输入图像的不同分割结果。实际上,如果训练和测试分段具有不同的评分者,则计算较低的Dice分数。此外,我们证明了在考虑测试数据的分割预测时,训练样本中的评估者间偏差被放大。我们支持我们的研究结果,表明在自动分割预测而非测试评注被测试时,基于其手动注释区分评估者的训练分类器DNN表现得更好。 |
| Optimizing CNN-based Hyperspectral ImageClassification on FPGAs Authors Shuanglong Liu, Ringo S.W. Chu, Xiwei Wang, Wayne Luk 高光谱图像HSI分类已广泛应用于涉及需要高分类精度和实时处理速度的遥感图像分析的应用中。基于卷积神经网络CNN的方法已被证明在分类HSI方面实现了最先进的准确性。然而,与传统方法(例如支持向量机SVM)相比,由于HSI的高维性质,CNN模型通常计算量太大而无法实现实时响应。此外,HSI中使用的先前CNN模型并非专为在FPGA等嵌入式设备上有效实施而设计。本文提出了一种新的基于CNN的HSI分类算法,该算法考虑了硬件效率。然后提出一种定制架构,其使得所提出的算法能够有效地映射到FPGA资源上,以支持具有低功耗的实时板载分类。实施结果表明,我们在Xilinx Zynq 706 FPGA板上提出的加速器比Intel 8核Xeon CPU快70倍以上,比NVIDIA GeForce 1080 GPU快3倍。与之前基于SVM的FPGA加速器相比,我们实现了可比较的处理速度,但提供了更高的分类精度。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com